






前言
今天跟大家分享一篇来自于吉林大学、香港城市大学、快手科技、西安交通大学在AAAI 2025联合发表的基于LLM的推荐系统用户模拟器。
用户模拟器能够快速生成大量实时的用户行为数据,为在线推荐系统提供测试平台,从而加速其迭代和优化。然而,现有的用户模拟器普遍存在显著的局限性,包括用户偏好建模不透明、无法评估模拟效果等。论文设计了一种由大语言模型驱动的推荐系统用户模拟器,以一种显式的方式模拟用户与商品的交互过程。 利用大语言模型的世界知识和推理能力,论文提出了一种逻辑模型实现用户商品交互模拟,并集成了统计模型提高模拟可靠性。与现有的基于大型语言模型的方案相比,该方法在推理阶段无需调用大型语言模型,既利用了其强大的推理能力,又避免了引入额外的时间开销和幻觉问题。 通过在多个数据集上进行的定性和定量实验,论文验证了该模拟器在各种推荐场景中的有效性和稳定性。

论文:https://arxiv.org/abs/2412.16984
代码:https://github.com/Applied-Machine-Learning-Lab/LLM_User_Simulator
1 研究动机
用户在线交互数据能够反映实时反馈和偏好,对持续优化推荐系统至关重要。然而,由于收集开销和隐私问题,获取真实用户的交互数据面临诸多挑战,因此有效模拟用户交互成为亟待解决的难题。用户模拟器可以快速生成交互数据,促进推荐系统的评估,同时保护用户隐私。
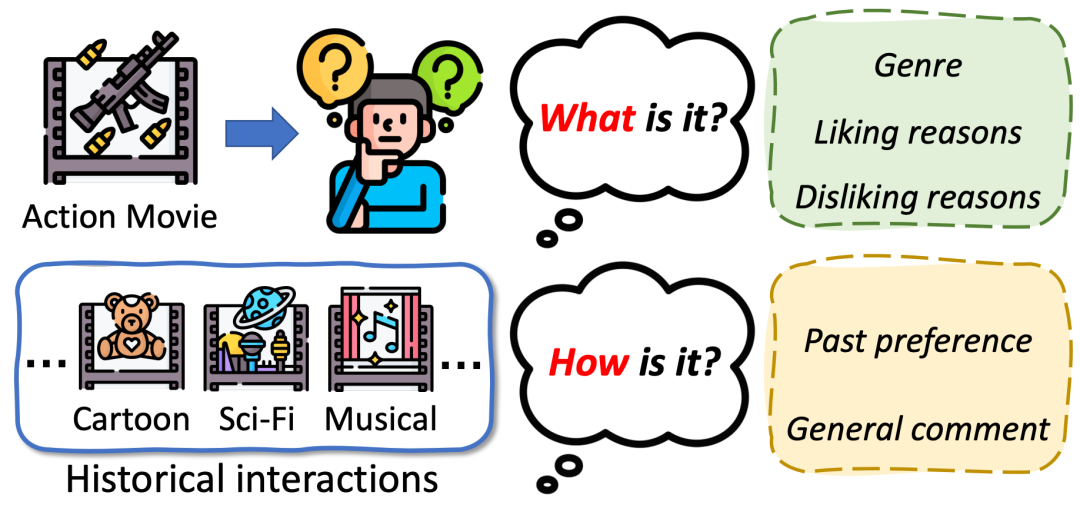
推荐系统用户交互逻辑
用户与商品的交互可以分为两个阶段:首先是认识商品,即了解商品的基本信息;其次是理解商品是否符合个人兴趣。以电影推荐为例,用户首先了解电影的类型,潜在的喜好或厌恶因素等客观信息;随后,用户从主观角度评估该电影是否符合自身兴趣,通常基于历史偏好或其他用户的评价。
本文的主要贡献可以被概括为以下三点:
-
分析用户与推荐商品交互的内在逻辑,在此基础上利用大语言模型分析商品特征并提炼用户偏好,提出一种推断用户交互行为的逻辑模型,为用户行为模拟提供了新的思路和方法。
-
构建了一个由基于规则的逻辑模型和数据驱动的统计模型组成的集成模型。结合了逻辑推理和统计学习的优势,能够更有效地模仿人类的交互行为。
-
在五个基准数据集上(POI、音乐、电影、游戏和动漫领域)进行了定性和定量实验。通过在多样化的数据集上进行实验,验证了所提出方法的有效性和稳定性。
2 方法
2.1 概述
基于用户商品交互逻辑,本文设计了一种基于大语言模型的用户模拟器,用于显式地模拟用户的交互过程(如下图)。具体而言,本文通过大语言模型分析商品,生成可能的喜欢或不喜欢原因,并总结为关键词。这些关键词既基于商品的客观描述,也来源于用户的评价文本,从而涵盖了商品的客观与主观特征。
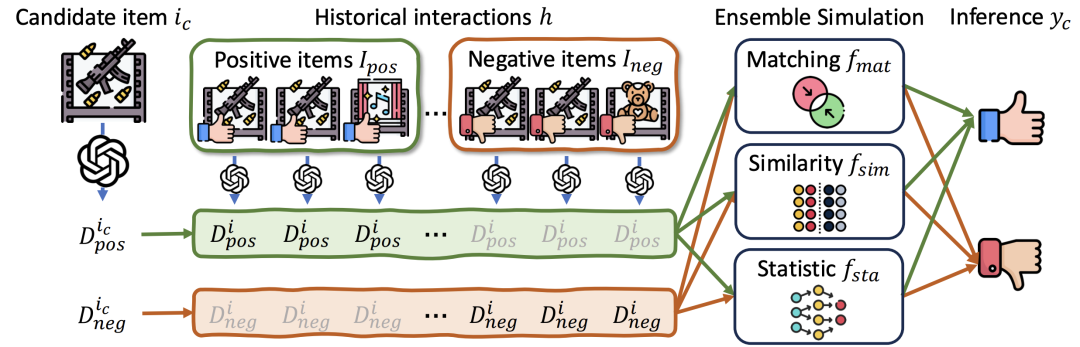
在推理阶段,给定候选商品,模拟器会将其潜在的喜好/不喜欢原因与用户历史中相似商品的交互原因进行匹配,最终预测用户的交互结果。本文综合使用匹配度、相似度计算和传统统计模型,从逻辑与统计分析两个维度共同评估交互结果,以确保模拟的可靠性。
2.2 商品描述收集
商品描述收集是用户模拟器的基础,它为后续的用户偏好分析和交互模拟提供了必要的信息。 文章通过LLM对商品的事实描述进行分析,确定商品类别(),并挖掘用户喜欢()和不喜欢()的客观原因及相关关键词。通过设计特定的提示模板(如 )引导 LLM 生成全面且有针对性的描述,并采用思维链(CoT)方法提升输出质量,最后对提取的关键词进行筛选优化。 商品描述收集分为客观商品描述收集和主观商品描述收集两部分,两个过程使用的prompt如下图所示。
-
客观商品描述收集:通过分析商品的事实性描述,确定商品的类别(如电影的类型),并从商品的基本信息(如名称、属性和类别)出发,利用LLM生成商品可能引起用户喜欢或不喜欢的客观原因。例如,在电影推荐中,LLM会根据电影的属性和类别,生成该电影的优缺点及其对应的证据和关键词。这些关键词和证据为后续的用户偏好分析提供了客观依据。
-
主观商品描述收集:用户对商品的主观看法会受到公众意见的影响。因此,文章通过分析用户评论,提取出反映用户喜欢或不喜欢情感的关键词。具体来说,根据用户的评分和评论,LLM会生成与评分相对应的商品优点及其关键词和证据。

客观商品描述收集prompt

主观商品描述收集prompt
将客观和主观商品描述收集到的关键词合并,形成全面的商品描述,为用户模拟器提供了丰富的商品信息。
2.3 逻辑模型设计
逻辑模型是用户模拟器的核心,它基于用户与推荐项目交互的基本逻辑,模拟用户对候选项目的喜好或不喜欢。逻辑模型包括关键词匹配模型和相似度计算模型。
-
关键词匹配模型:该模型专注于文本关键词的直接匹配。首先,从用户的历史交互项目中提取与候选项目相同类别的项目,然后分别提取出用户喜欢和不喜欢的项目集合。接着,计算候选项目的潜在喜欢/不喜欢原因与用户历史喜欢/不喜欢项目的原因之间的关键词匹配数量。通过比较匹配数量的多少,判断用户对候选项目的倾向。
-
相似度计算模型:为了更细致地理解用户偏好,该模型利用嵌入表示来计算候选项目的优缺点与用户历史喜欢/不喜欢项目之间的相似度。具体来说,使用BERT等预训练语言模型将关键词转换为嵌入向量,然后计算候选项目的优缺点嵌入向量与用户历史喜欢/不喜欢项目的嵌入向量之间的余弦相似度。通过比较相似度的大小,进一步判断用户对候选项目的倾向。
2.4 统计模型引入
为了提高用户交互模拟的准确性和可靠性,文章引入了数据驱动的统计模型。该模型采用深度模型(如SASRec),在用户的历史交互数据上进行预训练,以捕捉用户行为的统计规律。预训练好的统计模型能够为用户模拟器提供一个基于数据的预测结果,增强模拟的稳定性。
2.5 集成模型构建
将上述关键词匹配模型、相似度计算模型和统计模型组合成一个整体的用户模拟器。在强化学习推荐系统训练中,根据三个模型的综合结果确定奖励函数(),以此来模拟用户在不同推荐场景下的行为反应。
3 实验
3.1 实验设置
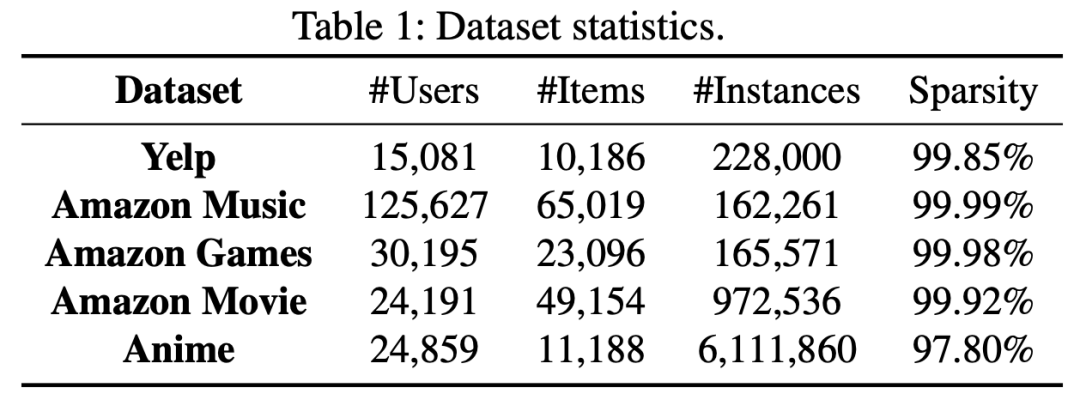
数据集统计
文章选用 Yelp、Amazon Music、Amazon Games、Amazon Movie 和 Anime 等五个涵盖不同领域的数据集,将评分数据转换为二元格式(如评分≥3 记为 1,否则记为 0),以便于实验处理和分析。选用 ChatGLM - 6B 作为 LLM,并采用 A2C、DQN、PPO 和 TRPO 等具有代表性的强化学习算法进行实验,评估模拟器在不同算法环境下的性能表现。
3.2 实验结果
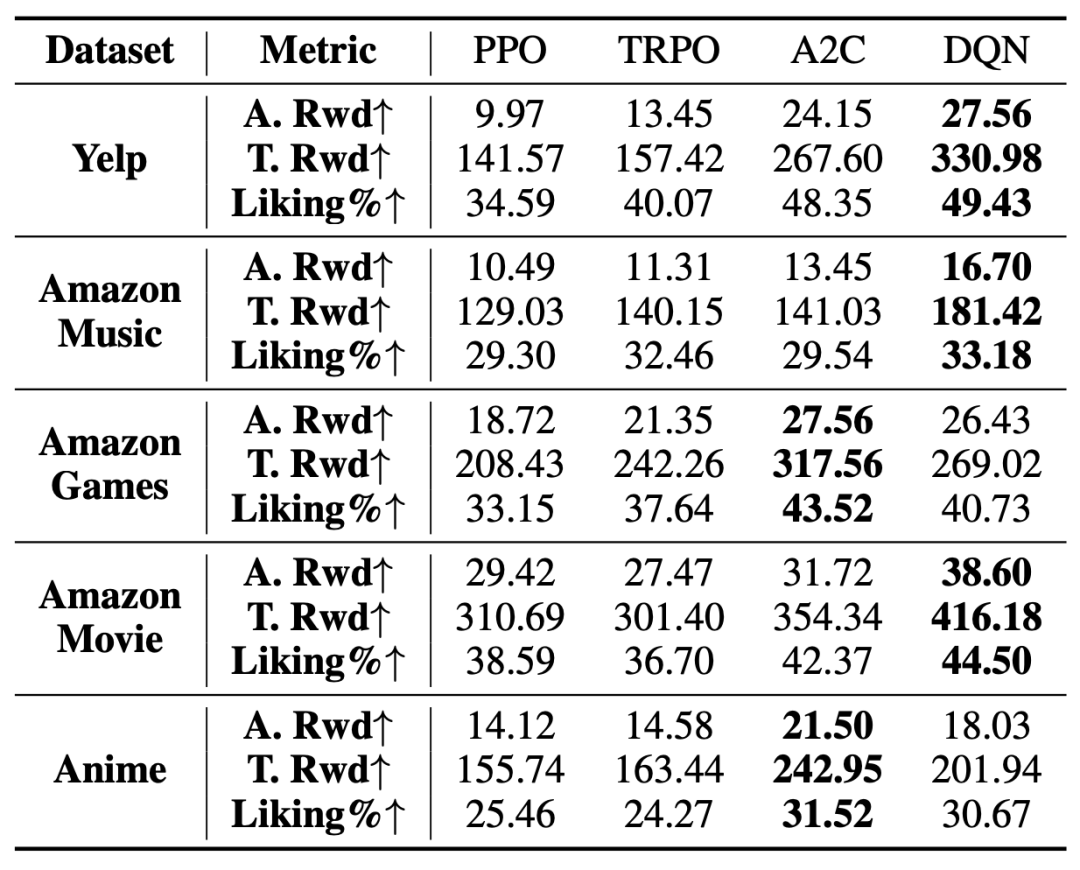
强化学习推荐系统性能比较
实验结果显示,DQN 算法在平均奖励、总奖励等关键指标上表现突出,优于其他强化学习算法。这主要归因于 DQN 算法在处理离散动作空间任务方面具有独特的优势,其能够更有效地估计每个动作的预期回报,并且通过经验回放和目标网络等技术进一步提升了性能。同时,各算法在推荐的喜好比例上均表现出较好的水平,这表明所提出的用户模拟器能够为不同算法提供稳定且可靠的交互环境,有效模拟用户的行为偏好。
3.3 Case study
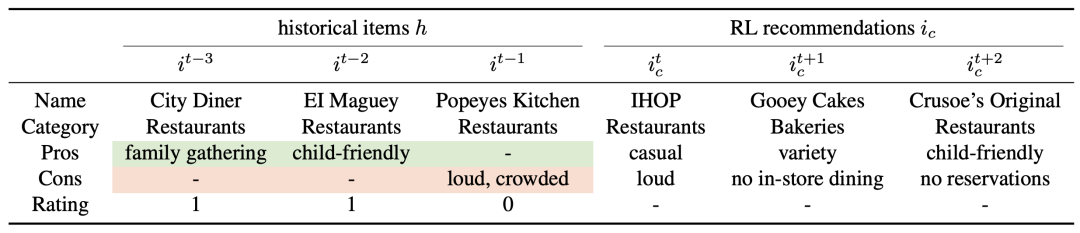 以 DQN 算法在 Yelp 数据集上的推荐过程为例进行详细分析。在具体案例中,展示了组合模型中各个模型对推荐商品的推断细节,如对于某些推荐商品,关键词匹配模型()通过对比其与历史商品的关键词匹配情况给出相应的判断结果,相似度计算模型()则依据语义嵌入向量的相似度进行推断。特别在面对新类型商品时,虽然逻辑模型可能在精度上受到一定影响,但统计模型能够发挥其基于历史数据学习的优势进行补充,充分体现了组合模型的协同作用和优势。
以 DQN 算法在 Yelp 数据集上的推荐过程为例进行详细分析。在具体案例中,展示了组合模型中各个模型对推荐商品的推断细节,如对于某些推荐商品,关键词匹配模型()通过对比其与历史商品的关键词匹配情况给出相应的判断结果,相似度计算模型()则依据语义嵌入向量的相似度进行推断。特别在面对新类型商品时,虽然逻辑模型可能在精度上受到一定影响,但统计模型能够发挥其基于历史数据学习的优势进行补充,充分体现了组合模型的协同作用和优势。
4 总结与展望
文章提出了一种基于大型语言模型的用户模拟器,用于强化学习驱动的推荐系统。该模拟器通过明确建模用户偏好和交互逻辑,利用LLM分析项目特征和用户情感,构建了逻辑模型和统计模型相结合的集成模型,以高保真度模拟用户行为。
尽管用户模拟器在实验中表现稳定,但仍存在一些局限性,如目前仅能模拟二元的“喜欢”或“不喜欢”交互。未来的工作可以考虑整合更多的交互信号,如持续时间、评分和留存等,以进一步丰富用户模拟器的应用场景和提高其模拟精度
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









