






需要对某列进行取mean和std,计算时发现抱错,原来时该列数据中质量不行,含有特定字符串,需要删除后再进行计算
frame = pd.DataFrame({'Y': [41, None, 'ABC', 70, 21.3], 'N': [131, 244, None, 1, 3]})
frame 
Y列中含“ABC”在运算前需剔除该数据再进行计算。
第一步使用str.contains来锁定异常行
y = frame["Y"].str.contains("ABC")
print(y)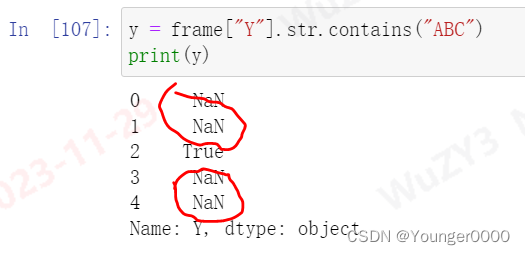
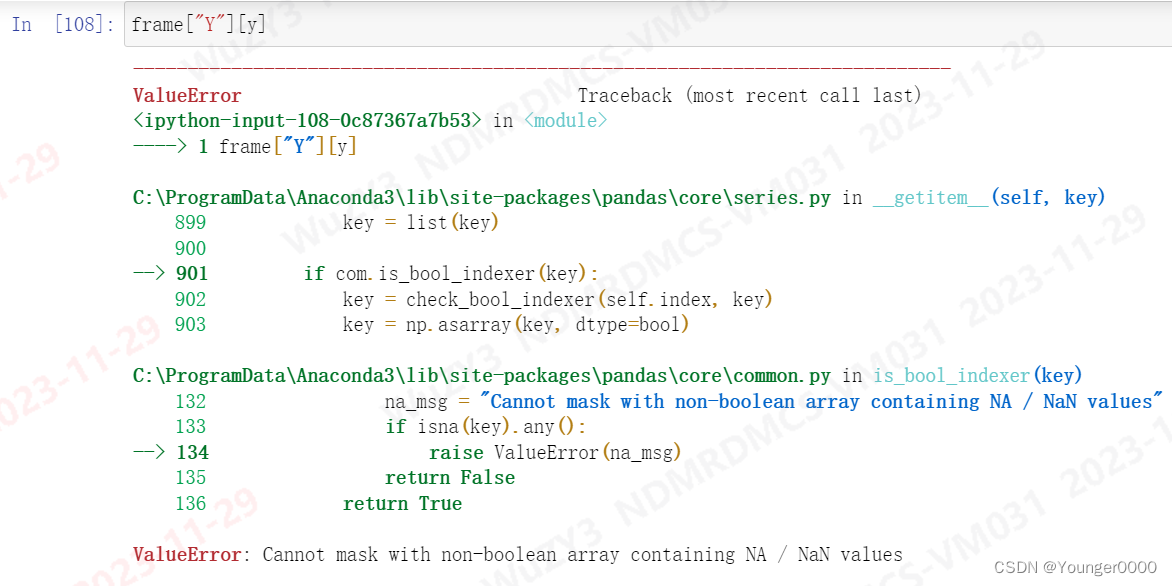
注意上图,锁定的行为True,其他行为int,nan与字符串“ABC"判定为NaN,所以无法输出的结果直接作为索引去进行选取行,否则会报错。
所以我这里将NaN在做一个.isna()判断,输出一个bool列,就可以直接使用了
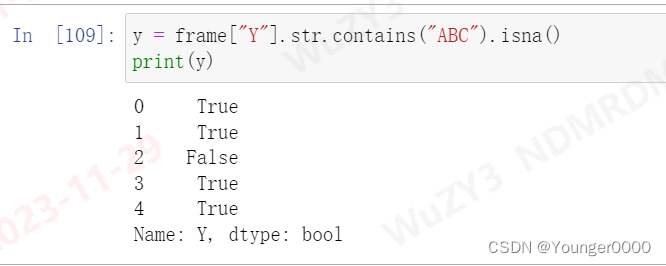
这里我们最终要使用的是index 2行,所以再取个反,就是我们真正需要的索引了,如下图

最后使用drop和.index来删除我们选取的行
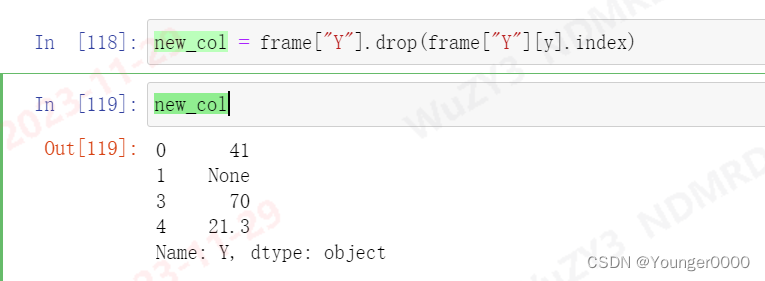
大功告成!可以进行计算了

一样可以也把None删除了再进行,
(1)空值类型的None。
(2)字符串类型的None,是真实存在的。
第一种直接使用dropna()可以删除
#axis=0: 删除包含缺失值(NaN)的行
#axis=1: 删除包含缺失值(NaN)的列
# how=‘any’ :要有缺失值(NaN)出现删除
# how=‘all’: 所有的值都缺失(NaN)才删除
第二种,直接replace为pandas可读取的空值,如nan,然后再用dropna()去掉即可。
df = df.replace(to_replace='None', value=np.nan).dropna()















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









