node与第三方模块实现网站图片爬取
引入我们的主角模块:
const request=require('request')//没有request模块 需要先行控制台安装 npm i request
const cheerio=require('cheerio')//没有cheerio模块 需要先行控制台安装 npm i cheerio
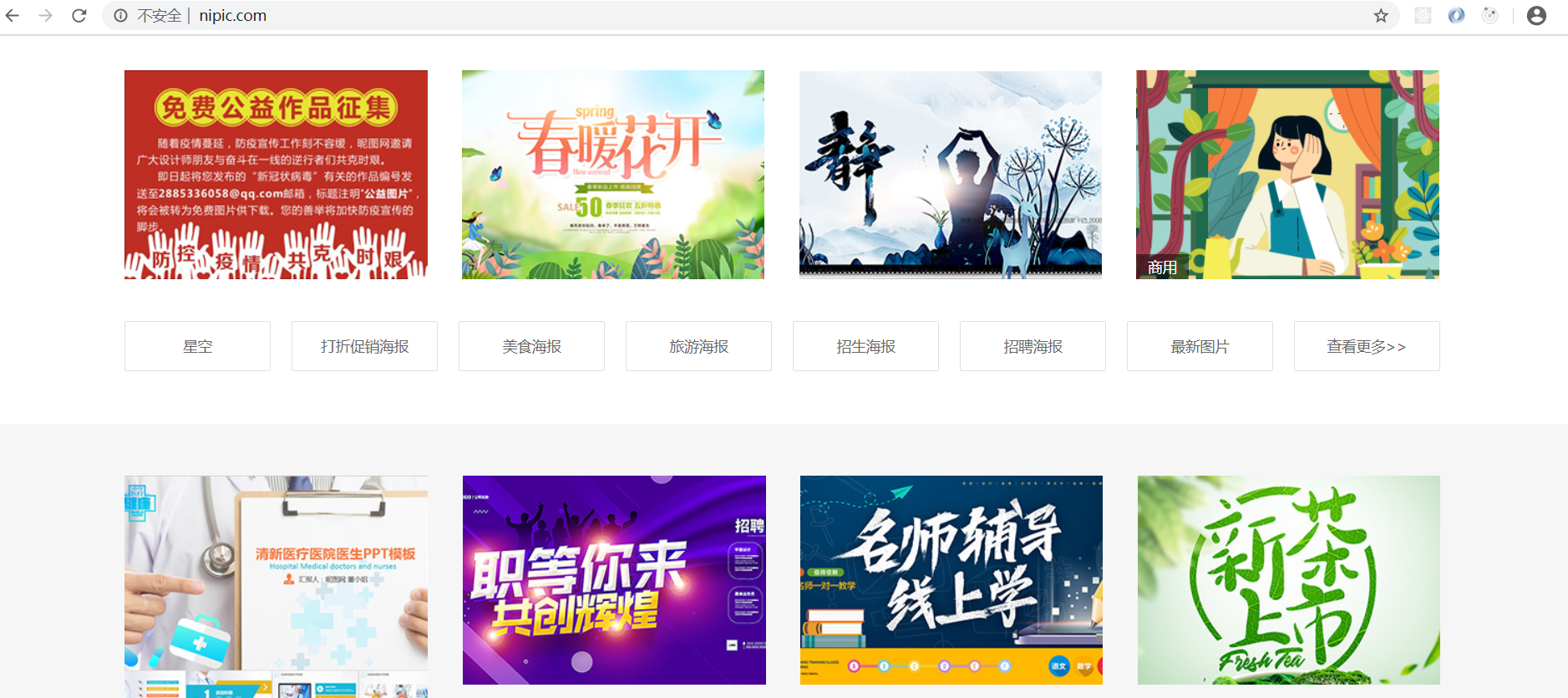
查看我们准备爬取的页面
获取页面dom
request('http://www.nipic.com/',{},function(err,res,body){//body是主页的HTML,{}为请求头
var $=cheerio.load(body)
// console.log(body)//body获取内容为字符串
// console.log($('img'))//获取dom内的img标签
//获取dom内全部的img src
$('img').each(function(index,element){
// console.log($(element).attr('src'))
var imgPath = $(element).attr('src')
requestImg(imgPath) //将图片地址传入封装的函数进行图片写入
})
})
方法1: fs模块写入图片
// 引入node自带模块
const http = require('http')
const url = require('url')
const path = require('path')
const fs = require('fs')
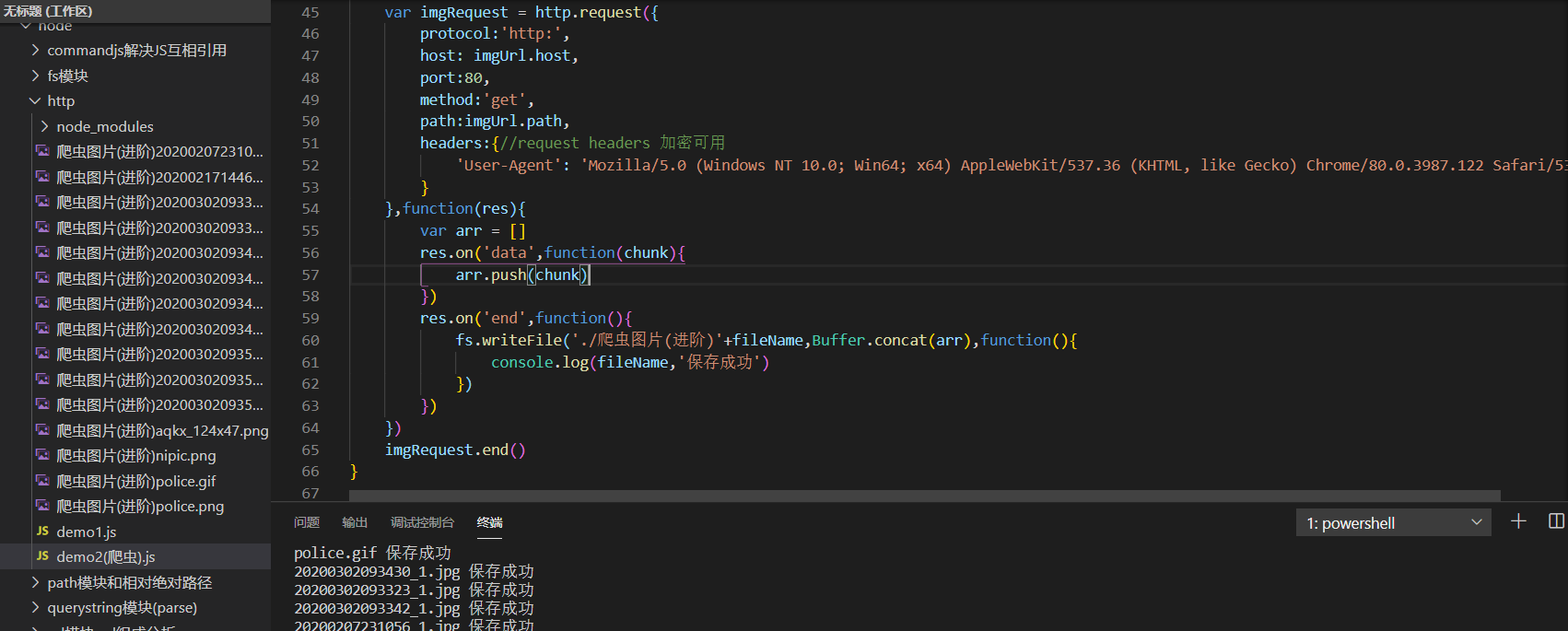
requestImg()函数的封装
var requestImg = function(imgPath){
var imgUrl = url.parse(imgPath)
var fileName = path.parse(imgUrl.path).base
var imgRequest = http.request({
protocol:'http:',
host: imgUrl.host,
port:80,
method:'get',
path:imgUrl.path,
headers:{//request headers 加密可用
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
},function(res){
var arr = []
res.on('data',function(chunk){
arr.push(chunk)
})
res.on('end',function(){
fs.writeFile('./爬虫图片(进阶)' fileName,Buffer.concat(arr),function(){
console.log(fileName,'保存成功')
})
})
})
imgRequest.end()
}
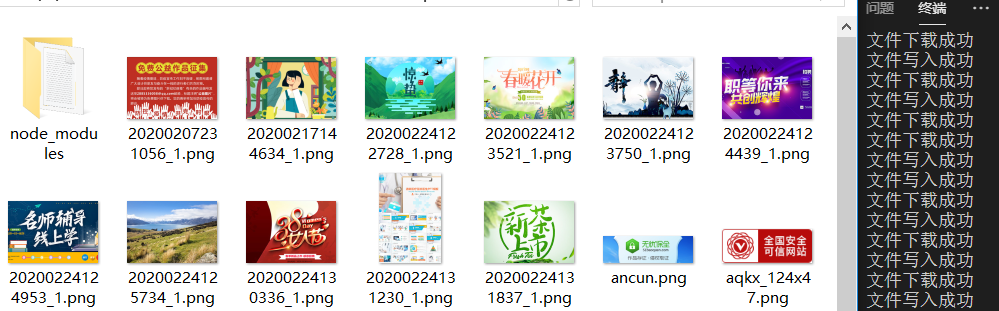
效果展示
方法2: request模块写入图片
// 引入node自带模块
const url = require('url')
const path = require('path')
const fs = require('fs')
requestImg()函数封装的变化
var requestImg = function(imgPath){
var imgUrl = url.parse(imgPath)
var fileName = path.parse(imgUrl.path).name
var writeStream = fs.createWriteStream(fileName '.png');
var src = imgPath;
var readStream = request(src)
readStream.pipe(writeStream);
readStream.on('end', function() {
console.log('文件下载成功');
});
readStream.on('error', function() {
console.log("错误信息:" err)
})
writeStream.on("finish", function() {
console.log("文件写入成功");
writeStream.end();
});
}
效果展示
--END--























 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









