







es入门
概述
Elasticsearch基于Lucene(搜索引擎库)的开源搜索引擎,对外提供一系列基于Java和HTTP的API, 目的是通过简单的RESTful API来隐藏Lucene的复杂性。
具有以下特点:
-
支持全文检索
-
分布式的实时文件存储,每个字段都被索引并可被搜索
-
分布式的实时分析搜索引擎
可以对照数关系型据库来理解Elasticsearch的有关概念。
| 关系型数据库(Relational DB) | Elasticsearch(搜索引擎) |
|---|---|
| 数据库(Databases) | Indices |
| 表(Tables) | Types |
| 行(Rows) | Documents |
| 字段(Columns) | Fields |
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
索引
索引只是一个把一个或多个分片分组在一起的逻辑空间。可以把索引看成关系型数据库的表。 然而,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。
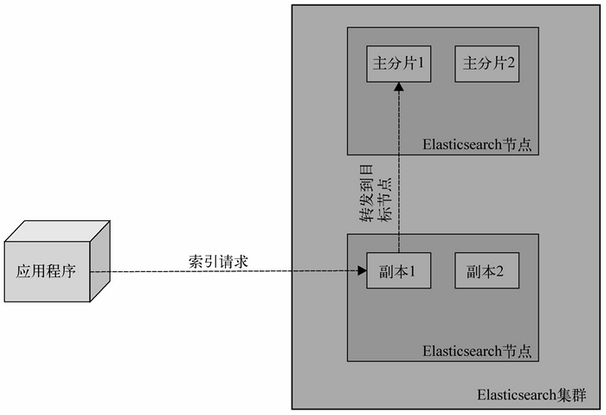
Elasticsearch 可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。发送一个新的文档给集群时,你指定一个目标索引并发送给它的任意一个节点。这个节点知道目标索引有多少分片,并且能够确定哪个分片应该用来存储你的文档。可以更改Elasticsearch的这个行为。现在你需要记住的重要信息是,Elasticsearch使用文档的唯一标识符来计算文档应该被放到哪个分片中。索引请求发送到一个节点后,该节点会转发文档到持有相关分片的目标节点中。
一次索引操作

检索
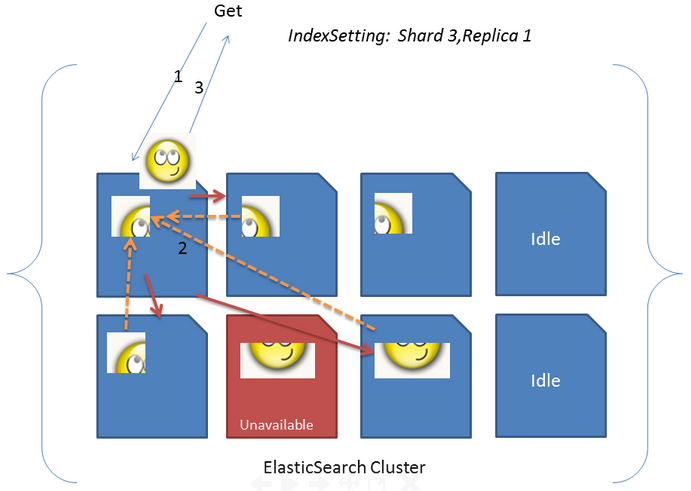
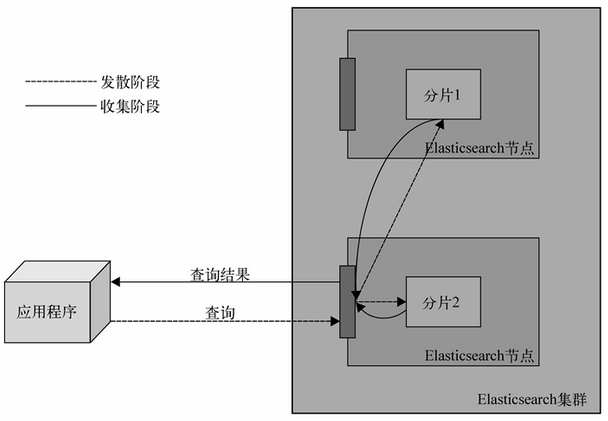
尝试用文档标识符来获取文档时,发送查询到一个节点,该节点使用同样的路由算法来决定持有文档的节点和分片,然后转发查询,获取结果,并把结果发送给你。另一方面,查询过程更为复杂。除非使用了路由,查询将直接转发到单个分片,否则,收到查询请求的节点会把查询转发给保存了属于给定索引的分片的所有节点,并要求获取查询匹配的文档的最少信息(默认情况下是标识符和得分)。这个过程称为发散阶段(scatter phase)。收到这些信息后,该聚合节点(收到客户端请求的节点)对结果排序,并发送第2个请求来获取结果列表所需的文档(除了标识符和得分以外的所有信息)。这个阶段称为收集阶段(gather phase)。这个阶段执行完毕后,结果返回到客户端。
一次查询请求:
curl -X GET http://localhost:9200/megacorp/employee/1?
文档
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。相同字段必须有相同类型,文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。每个字段有类型,如文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。字段类型在Elasticsearch中很重要,因为它给出了各种操作(如分析或排序)如何被执行的信息。幸好,这可以自动确定,然而,我们仍然建议使用映射。与关系型数据库不同,文档不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。当然,可以用模式强行规定文档结构。 从客户端的角度看,文档是一个JSON对象(关于JSON格式的更多内容,参见http://en.wikipedia.org/wiki/JSON)。每个文档存储在一个索引中并有一个Elasticsearch自动生成的唯一标识符和文档类型。文档需要有对应文档类型的唯一标识符,这意味着在一个索引中,两个不同类型的文档可以有相同的唯一标识符。
文档类型
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论。 文档类型让我们轻易地区分单个索引中的不同对象。每个文档可以有不同的结构,但在实际部署中,将文件按类型区分对数据操作有很大帮助。当然,需要记住一个限制,不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引中的所有文档类型中,一个叫title的字段必须具有相同的类型
映射
模式映射(schema mapping,或简称映射)用于定义索引结构。Elasticsearch在映射中存储有关字段的信息。每一个文档类型都有自己的映射,即使我们没有明确定义。映射在文件中以JSON对象传送。所以,创建一个映射文件来匹配上述需求,称之为mapping.json。其内容如下:
{
"mappings": {
"post": {
"properties": {
"id": {"type":"long", "store":"yes",
"precision_step":"0" },
"name": {"type":"string", "store":"yes",
"index":"analyzed" },
"published": {"type":"date",
"store":"yes",
precision_step":"0" },
"contents": {"type":"string",
"store":"no",
"index":"analyzed" }
}
}
}
}使用上述文件创建posts索引,运行命令:
curl -XPOST 'http://localhost:9200/posts' -d @mapping.json
分片
当有大量的文档时,由于内存的限制、硬盘能力、处理能力不足、无法足够快地响应客户端请求等,一个节点可能不够。在这种情况下,数据可以分为较小的称为分片(shard)的部分(其中每个分片都是一个独立的Apache Lucene索引)。每个分片可以放在不同的服务器上,因此,数据可以在集群的节点中传播。 当你查询的索引分布在多个分片上时,Elasticsearch会把查询发送给每个相关的分片,并将结果合并在一起,而应用程序并不知道分片的存在。此外,多个分片可以加快索引。
副本
为了提高查询吞吐量或实现高可用性,可以使用分片副本。副本(replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。换句话说,Elasticsearch可以有许多相同的分片,其中之一被自动选择去更改索引操作。这种特殊的分片称为主分片(primary shard),其余称为副本分片(replica shard)。在主分片丢失时,例如该分片数据所在服务器不可用,集群将副本提升为新的主分片。
es-head简介
elasticsearch有很多的插件来丰富它的功能。此处,我们推荐使用elasticsearch-head。
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到es(首选方式),也可以安装成一个独立webapp。
操作
-
显示集群的拓扑,并且能够执行索引和节点级别操作
-
搜索接口能够查询集群中原始json或表格格式的检索数据
-
能够快速访问并显示集群的状态
-
有一个输入窗口,允许任意调用RESTful API。 这个接口包含几个选项,可以组合在一起以产生有趣的结果; 1. 请求方法(get、put、post、delete),查询json数据,节点和路径 2. 支持JSON验证器 3. 支持重复请求计时器 4. 支持使用javascript表达式变换结果 5. 收集结果的能力随着时间的推移(使用定时器),或比较的结果 6. 能力图表转换后的结果在一个简单的条形图(包括时间序列)
github
https://github.com/mobz/elasticsearch-head
es-head查看
在浏览器打开127.0.0.1:9200/_plugin/head/,查看到界面表示安装成功。
寄语
es在我上家公司的应用,是搭建了一个单节点的es服务,用于实现全站搜索功能,他可以按照自定义的查询条件和匹配程度给我数据集合,安装简单,有es-head,使用方便,使用restful方式。
es在各大互联网公司还是很常见的一门技术,所以推荐大家学习下,我个人的es实战积累不多。所以列下清单,一起成长。















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









