









自动微分采用一套与常规机器学习和深度学习不同的符号体系,我们只有熟悉了这个符号体系,才能比较轻松的看懂自动微分的文章。本篇博文将向大家介绍自动微分中使用的符号体系。
我们以下面这个函数为例,讲解一下自动微分的符号表示法:
y=f(x1,x2)=logx1+x1x2−sinx2
y
=
f
(
x
1
,
x
2
)
=
log
x
1
+
x
1
x
2
−
sin
x
2
对自动微分采用一种比较特别的符号表示法,与Bingio的《Deep Learning》书中MLP章节中的表示法类似,采用三段表示法。
- 输入向量
我们假设自变量维度为n,在这个例子中n=2,我们用 v v 来表示自变量:,以本例为例,我们用 v−1 v − 1 表示 x1 x 1 ,用 v0 v 0 表示 x2 x 2 。 - 中间变量
我们同样用 v v 表示中间变量,假设共有个中间变量,表示为: vi,i=1,2,...,l v i , i = 1 , 2 , . . . , l - 输出向量
我们用 y y 来表示输入向量,假设输出向量维度为,表示为: yk−i=vl−i,i=k−1,...,0 y k − i = v l − i , i = k − 1 , . . . , 0 ,还以本例为例,输出向量只有1维,则 k=1 k = 1 ,则 y1=vl y 1 = v l 。
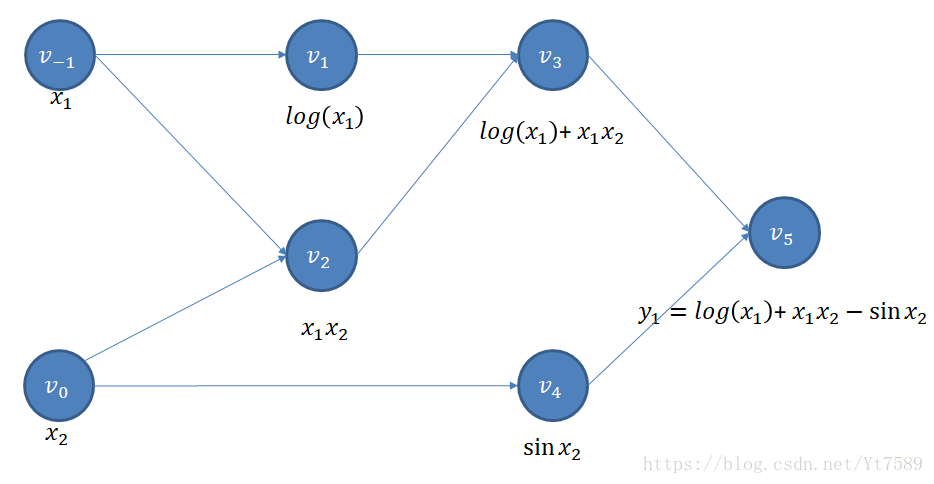
我们先来讲前向模式,这种模式即可求出计算图的输出,同时也可以求出导数值。但是如果以深度学习的角度来看,前向模式就只需要完成计算出计算图中各节点的值就可以了。而求导数则由反向模式来实现。
我们首先给输入节点赋值: v−1=x1 v − 1 = x 1 和 v0=x2 v 0 = x 2
接着我们计算 v1 v 1 节点: v1=logv−1=logx1 v 1 = log v − 1 = log x 1
我们再计算 v2 v 2 节点: v2=v−1v0=x1x2 v 2 = v − 1 v 0 = x 1 x 2
我们再来计算 v3 v 3 节点: v3=v1+v2=logx1+x1x2 v 3 = v 1 + v 2 = log x 1 + x 1 x 2
计算 v4 v 4 节点: v4=−sinv0=−sinx2 v 4 = − sin v 0 = − sin x 2
计算输出节点 v5 v 5 : y1=v5=v3+v4=logx1+x1x2−sinx2 y 1 = v 5 = v 3 + v 4 = log x 1 + x 1 x 2 − sin x 2
至此我们就计算出了计算图中所有节点的值。
下面我们来介绍在正向模式下导数的计算。假设我们想求 ∂y∂x1 ∂ y ∂ x 1 的值,我们也是由输入开始计算。
对 v−1 v − 1 节点: ∂v−1∂x1=1 ∂ v − 1 ∂ x 1 = 1 ,因为 v−1=x1 v − 1 = x 1
对 v0 v 0 节点: ∂v0∂x1=0 ∂ v 0 ∂ x 1 = 0 ,因为 v0=x2 v 0 = x 2 其与 x1 x 1 无关。
对 v1 v 1 节点: ∂v1∂x1=∂∂x1logx1=1x1 ∂ v 1 ∂ x 1 = ∂ ∂ x 1 log x 1 = 1 x 1
对 v2 v 2 节点: ∂v2∂x1=∂∂x1x1x2=x2 ∂ v 2 ∂ x 1 = ∂ ∂ x 1 x 1 x 2 = x 2
对 v3 v 3 节点: ∂v3∂x1=∂v1∂x1+∂v2∂x1=1x1+x2 ∂ v 3 ∂ x 1 = ∂ v 1 ∂ x 1 + ∂ v 2 ∂ x 1 = 1 x 1 + x 2
对 v4 v 4 节点: ∂v4∂x1=∂∂x1sinx2=0 ∂ v 4 ∂ x 1 = ∂ ∂ x 1 sin x 2 = 0
对 v5 v 5 节点: ∂v5∂x1=∂v3∂x1−∂v4∂x1=1x1+x2 ∂ v 5 ∂ x 1 = ∂ v 3 ∂ x 1 − ∂ v 4 ∂ x 1 = 1 x 1 + x 2
由上面的计算可以看出,我们每次前向计算,只能计算输入向量一维的导数,如果输入向量有 n=2 n = 2 维,则需要计算两次,当 n n 很大时,这种方法的效率就会比较低了。
对于深度学习问题,我们通常会研究Jacobian矩阵,假设输入向量,而输出向量用 y∈Rk y ∈ R k ,则Jacobian矩阵定义为:
J=⎡⎣⎢⎢⎢∂y1∂x1...∂yk∂x1∂y1∂x2...∂yk∂x2.........∂y1∂xn...∂yk∂xn⎤⎦⎥⎥⎥ J = [ ∂ y 1 ∂ x 1 ∂ y 1 ∂ x 2 . . . ∂ y 1 ∂ x n . . . . . . . . . . . . ∂ y k ∂ x 1 ∂ y k ∂ x 2 . . . ∂ y k ∂ x n ]
我们可以看出,一次前向计算,可以求出Jacobian矩阵的一列数据。
为了讨论方便,我们这里假设 x1=2 x 1 = 2 且 x2=5 x 2 = 5 ,我们首先按照前向模式计算出各节点的值,如下图所示:
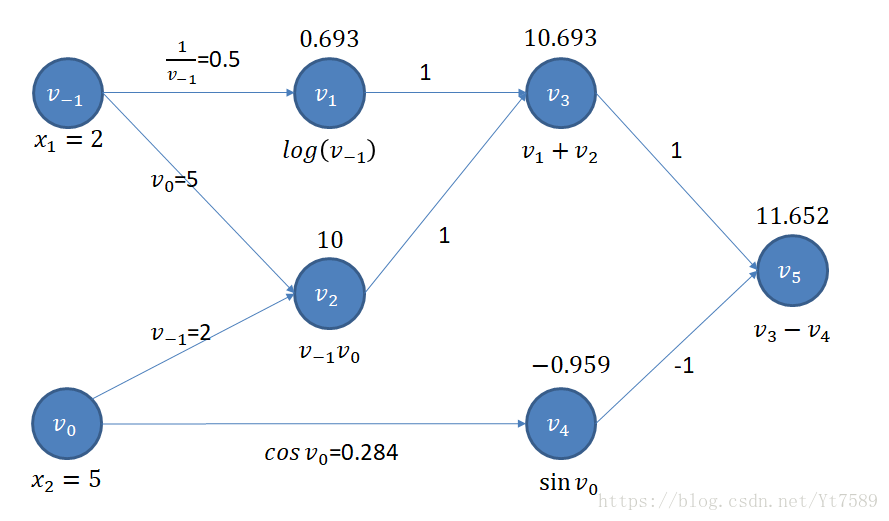
我们再来看导数部分。
对 v5 v 5 节点有 v5=v3−v4 v 5 = v 3 − v 4 ,我们首先求 ∂v5∂v3=∂(v3−v4)∂v3=1 ∂ v 5 ∂ v 3 = ∂ ( v 3 − v 4 ) ∂ v 3 = 1 ,将结果写在 v3 v 3 指向 v5 v 5 的边上。
我们再来求 ∂v5∂v4=∂(v3−v4)∂v4=−1 ∂ v 5 ∂ v 4 = ∂ ( v 3 − v 4 ) ∂ v 4 = − 1 ,将结果写在 v4 v 4 指向 v5 v 5 的边上。
我们再来求 ∂v4∂v0=∂sinv0∂v0=cosv0=0.284 ∂ v 4 ∂ v 0 = ∂ sin v 0 ∂ v 0 = cos v 0 = 0.284 ,将结果写在 v0 v 0 指向 v4 v 4 的边上。
我们再来求 ∂v3∂v1=∂(v1+v2)∂v1=1 ∂ v 3 ∂ v 1 = ∂ ( v 1 + v 2 ) ∂ v 1 = 1 ,将结果写在 v1 v 1 指向 v3 v 3 的边上。
我们再来求 ∂v3∂v2=∂(v1+v2)∂v2=1 ∂ v 3 ∂ v 2 = ∂ ( v 1 + v 2 ) ∂ v 2 = 1 ,将结果写在 v2 v 2 指向 v3 v 3 的边上。
我们再来求 ∂v1∂v−1=∂logv−1∂v−1=1x1=0.5 ∂ v 1 ∂ v − 1 = ∂ log v − 1 ∂ v − 1 = 1 x 1 = 0.5 ,将结果写在 v−1 v − 1 指向 v1 v 1 的边上。
我们再来求 ∂v2∂v−1=∂(v−1v0)∂v−1=v0=5 ∂ v 2 ∂ v − 1 = ∂ ( v − 1 v 0 ) ∂ v − 1 = v 0 = 5 ,将结果写在 v−1 v − 1 指向 v2 v 2 的边上。
我们再来求 ∂v2∂v0=∂(v−1v0)∂v0=v−1=2 ∂ v 2 ∂ v 0 = ∂ ( v − 1 v 0 ) ∂ v 0 = v − 1 = 2 ,将结果写在 v0 v 0 指向 v2 v 2 的边上。
至此我们已经求出了所有步的偏导数的值,我们计算 ∂y1∂x1 ∂ y 1 ∂ x 1 就是从 y1 y 1 开始,反向走回 x1 x 1 节点,可能有多条路径,对每一条路径,将每个边上的值连乘,最后将多条路径的值相加,即可求出 ∂y1∂x1 ∂ y 1 ∂ x 1 的值。 ∂y1∂x2 ∂ y 1 ∂ x 2 的值与此类似。
如图所示,从 y1 y 1 走到 x1 x 1 共有两条路径,分别为:
v5→v3→v1→v−1 v 5 → v 3 → v 1 → v − 1 : 1∗1∗0.5=0.5 1 ∗ 1 ∗ 0.5 = 0.5
v5→v3→v2→v−1 v 5 → v 3 → v 2 → v − 1 : 1∗1∗5=5.0 1 ∗ 1 ∗ 5 = 5.0
所以 ∂y1∂x1=0.5+5.0=5.5 ∂ y 1 ∂ x 1 = 0.5 + 5.0 = 5.5 。
用同样的方法我们可以计算 ∂y1∂x2 ∂ y 1 ∂ x 2 的值。由 y1 y 1 ∂y1∂x2 ∂ y 1 ∂ x 2 到 x2 x 2 的路径也有两条:
v5→v3→v2→v0 v 5 → v 3 → v 2 → v 0 : 1∗1∗2=2.0 1 ∗ 1 ∗ 2 = 2.0
v5→v4→v0 v 5 → v 4 → v 0 : (−1)∗0.284=−0.284 ( − 1 ) ∗ 0.284 = − 0.284
所以 y1 y 1 ∂y1∂x2=2.0+(−0.284)=1.716 ∂ y 1 ∂ x 2 = 2.0 + ( − 0.284 ) = 1.716 。
相对于正向模式而言,反向模式可以通过一次反向传输,就计算出所有偏导数,而这对于深度学习中的如多层感知器(MLP)模型来说,非常方便,而且中间的偏导数计算只需计算一次,减少了重复计算的工作量,当然这是以增加存储量需求为代价的。
在本篇博文中,我们详细讲解了自动微分概念,自动微分概念是一个比较老的概念,但是将其引入深度学习领域,还是一个新鲜事务,这就是最近Yann Lecun提到的“深度学习已死,可微分编程永生”中的技术。在下一篇博文中,我们将向大家介绍自动微分在深度学习中的应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









