






声明:本教程不收取任何费用,欢迎转载,尊重作者劳动成果,不得用于商业用途,侵权必究!!!
目录
一、HashMap和HashTable异同点
(1)继承实现异同
如下源码中,二者都实现了Map接口
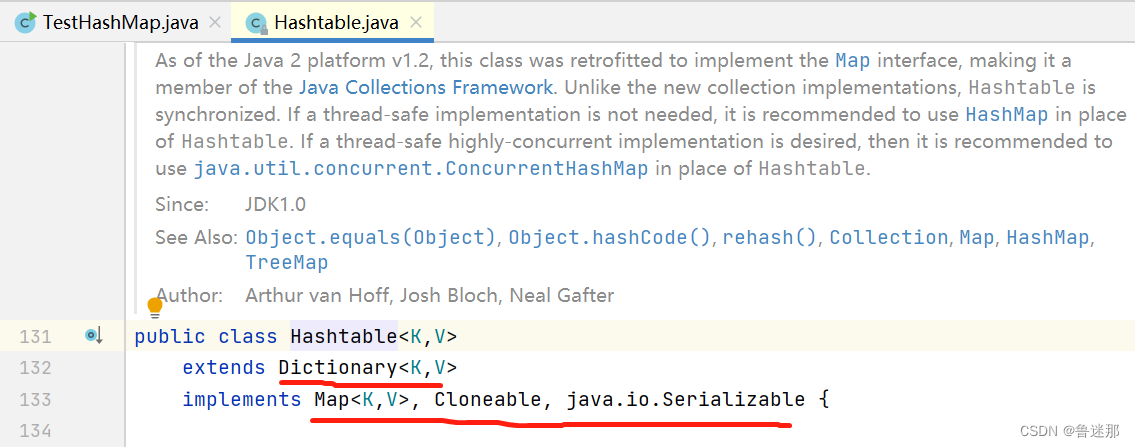
HashMap继承于AbstractMap,HashTable继承于Dictionary

(2)线程安全性、效率不同
HashMap是线程不安全的,HashTable是线程安全的。
HashTable其中里面的方法是Synchronize修饰的,在多线程并发的情况下可以直接使用。
所以HashMap 效率比 HashTable 的要高,因为线程安全的问题
(3)是否提供contains方法
HashMap只有containsKey和containsValue方法;
HashTable有containsKey和containsValue、contains三个方法,其中contains和containsValue方法功能相同。
(4)key和value是否允许null值
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键,所对应的值为null。
Hashtable中,key和value都不允许出现null值。
(5)数组初始化和扩容机制
1>HashMap在不指定容量的情况下的默认容量为16,而HashTable为11
2>HashMap要求底层数组的容量一定为2的整数次幂,Hashtable不要求一定为2的整数次幂
3>HashMap扩容时,将容量变为原来的2倍,而Hashtable扩容时,将容量变为原来的2倍加1
二、底层实现
为大家带来HashMap它的底层的一些原理,以及为什么在面试过程中我们经常被问到,但是呢,
我发现很多同学,对这个HashMap的底层了解的不够透彻,就是它的知识体系的无法形成一个数。
就可能只会知道哪几个点,但是真正你往深里面去问的时候呢,很多同学他是答不上来的!
比如我想问大家一个点,比如说我们的HashMap 1.7和1.8,他们有什么区别,那为什么呢?
也就是说大家应该也知道jdk1.8新增了红黑树,那jdk1.8之后为什么会增加红黑树?
包括我们的HashMap,它的1.7和1.8,它底层的实现?
它底层的实现为什么要去改变它底层的实现,它底层实现原理是什么?
它为什么要改变,这一切其实你都要能知道为什么,就是我们经常讲,
我们学一个知识点要知其然,知其所以然,就是这个道理!
所以带着这样的一些问题,带着这样的疑惑!我们慢慢讲解。。。
HashMap能考的点很多,就是能考它的一些算法,一个能考它的一些数据结构,
也包括能考你这个人,到底是不是一个科班出身的,还是一个培训出来的,
都能问出来,就通过这个HashMap!
它们都是 数组+链表 实现的
在jdk1.7中由数组+链表实现,
在jdk1.8中由数组+链表+红黑树实现
好了,具体底层实现,第二篇咱们再详说
请别只做拿来主义者,如果觉得写的不错、对你有用,留下你的足迹:点赞、评论、收藏支持下!
一直被模仿从未被超越,你们的支持是我们这些写博客博主们的动力!我们将继续分享干货!
















 1382
1382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











