







前言
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成**.Net、Java、Perl**等不同语言的测试脚本。
一、自动填充查询关键字
1.网页分析
前往百度搜索,打开浏览器调试功能

查看输入框id、以及输入的位置
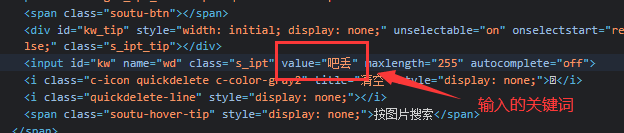
查看点击按钮


2.代码编辑
1)谷歌浏览器驱动下载
https://npm.taobao.org/mirrors/chromedriver/
2)引入库与打开网站
from selenium import webdriver
driver = webdriver.Chrome("D:\GoogleDownload\chromedriver.exe")
driver.get("https://www.baidu.com/")
3)输入框键入关键字
search=driver.find_element_by_id("kw")
search.send_keys("御神楽的学习记录")
4)点击
send_button=driver.find_element_by_id("su")
send_button.click()
5)测试效果

二、动态网页爬取
1.名言爬取
1)网页分析
http://quotes.toscrape.com/js/
需要爬取的内容如下
名言和作者

2)代码实现
#库引入与浏览器打开网页
from selenium import webdriver
driver = webdriver.Chrome("D:\GoogleDownload\chromedriver.exe")
driver.get("http://quotes.toscrape.com/js/")
# 表头
csvHeaders = ['作者','名言']
# 所有数据
subjects = []
# 单个数据
subject=[]
# 获取所有含有quote的标签
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
subject.append(tmp.find_element_by_class_name("author").text)
subject.append(tmp.find_element_by_class_name("text").text)
print(subject)
subjects.append(subject)
subject=[]
3)爬取效果

2.京东书籍爬取
1)网页分析
输入框


按钮

书籍列表

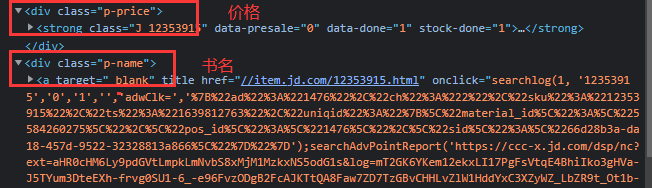
价格和书名

翻页按钮

2)代码实现
#库引入与浏览器打开网页
from selenium import webdriver
import time
import csv
driver = webdriver.Chrome("D:\GoogleDownload\chromedriver.exe")
driver.set_window_size(1920,1080)
driver.get("https://www.jd.com/")
# 输入需要查找的关键字
key=driver.find_element_by_id("key").send_keys("python编程")
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
# 获取所有窗口
windows = driver.window_handles
# 切换到最新的窗口
driver.switch_to.window(windows[-1])
time.sleep(1)
# js语句
js = 'return document.body.scrollHeight'
# 获取body高度
max_height = driver.execute_script(js)
max_height=(int(max_height/1000))*1000
# 当前滚动条高度
tmp_height=1000
# 所有书籍的字典
res_dict={}
# 需要爬取的数量
num=100
while len(res_dict)<num:
# 当切换网页后重新设置高度
tmp_height = 1000
while tmp_height < max_height:
# 向下滑动
js = "window.scrollBy(0,1000)"
driver.execute_script(js)
tmp_height += 1000
# 书籍列表
J_goodsList = driver.find_element_by_id("J_goodsList")
ul = J_goodsList.find_element_by_tag_name("ul")
# 所有书籍
res_list = ul.find_elements_by_tag_name("li")
# 把没有记录过的书籍加入字典
for res in res_list:
# 以书名为键,价格为值
# 两种方式获取指定标签值
res_dict[res.find_element_by_class_name('p-name').find_element_by_tag_name('em').text] \
= res.find_element_by_xpath("//div[@class='p-price']//i").text
if len(res_dict)==num:
break
time.sleep(2)
if len(res_dict) == num:
break
# 下一页按钮所在父标签
J_bottomPage=driver.find_element_by_id("J_bottomPage")
# 下一页按钮
next_button=J_bottomPage.find_element_by_class_name("pn-next").click()
# 切换窗口
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(3)
# 表头
csvHeaders = ['书名','价格']
# 所有书籍
csvRows=[]
# 书籍
row=[]
# 字典转列表
for key,value in res_dict.items():
row.append(key)
row.append(value)
csvRows.append(row)
row=[]
# 保存爬取结果
with open('./output/jd_books.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(csvRows)
3)爬取文件如下

总结
对动态网页进行内容爬取时,首先最重要的是对网页的内容,即需要爬取的内容进行定位,分析,然后使用python selenium工具进行爬取即可。前期分析工作做好了,那么编写代码就十分明确,事半功倍!















 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









