







[基于树莓派]深入剖析Kubernetes
上篇的续集
15.自己编写存储插件
FlexVolume…
CSI…
16.容器网络
# 声明该运行的容器直接使用宿主的网络栈
# 通过该方式,我们可以直接在宿主机上进行不同容器间的通信,因为所有容器都使用的为宿主机的网络;
docker run –d –net=host --name nginx-host nginx
16.1.Veth Pair虚拟设备
Veth Pair被创建后会以两张虚拟网卡的形式成对出现;从一张网卡发出的数据包,会直接出现在与它对应的另一张网卡上,哪怕这两张网卡在不同Network Namespace中;
# 如下图,我们可以看到该运行的容器的默认网卡为 eth0
docker run -it --rm busybox /bin/sh
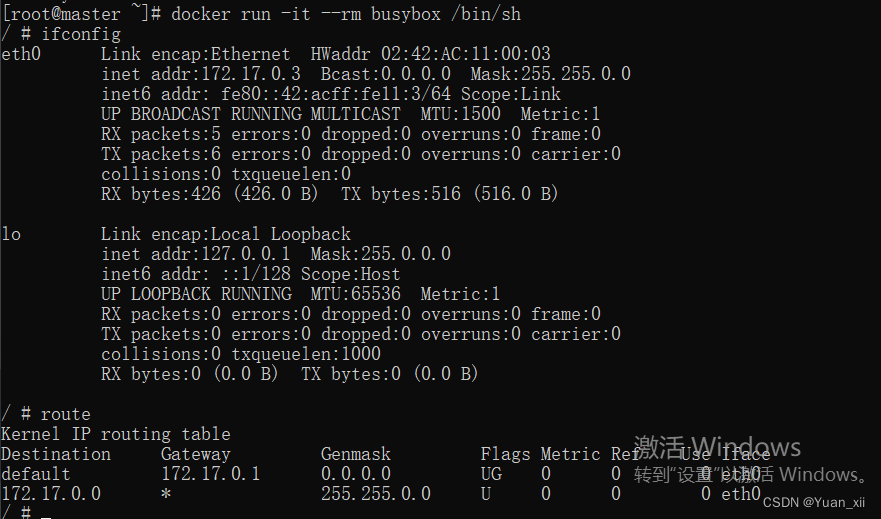
该网卡eth0为Veth Pair形式,其另一端为宿主机的docker0网卡
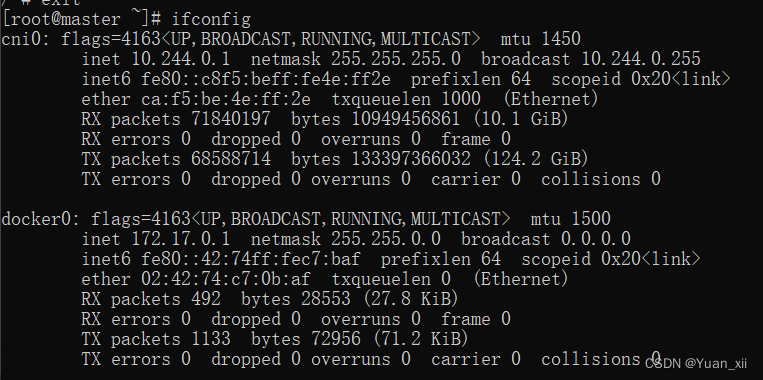
16.2.同一主机容器间通信
由docker0充当网桥
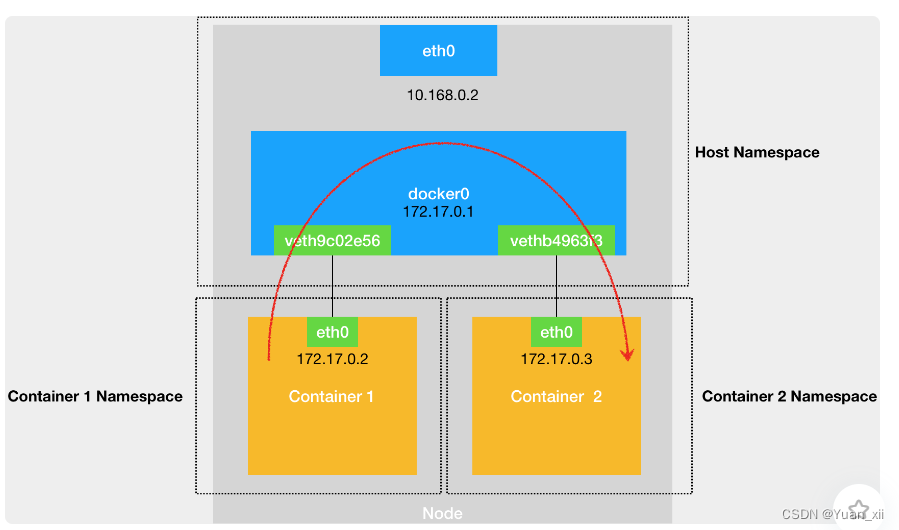
两个容器间是如何通信的呢?
- (1) 容器0 ping 容器1
- (2) 按照容器0的路由表,会将该包转发至默认网关 172.17.0.1

- (3) 由于该虚拟网卡为Veth Pair形式,因此该包会被转发至在宿主机生成的对应的网卡上
- (4) 由于该虚拟网卡插入到了docker0网桥上,因此该数据包会被转发至docker0网桥上
- (5)docker0扮演二层交换机角色,将ARP广播转发到其他被插在docker0上的虚拟网卡上
- (6)容器1响应该请求,将自己的MAC地址回复给容器0;
16.2. 不同主机容器间通信
由overlay虚拟网络层充当网桥
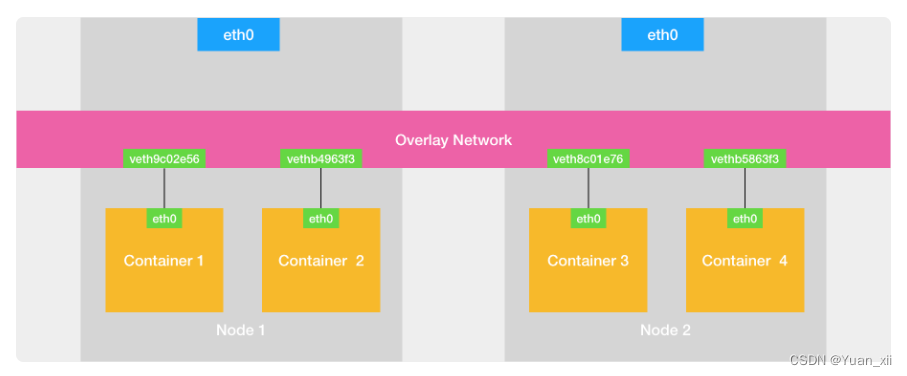
16.2.1.Flannel UDP模式
| node | container | ip | docker0 |
|---|---|---|---|
| node 1 | container 1 | 192.168.31.175 | 172.17.0.1/16 |
| node 2 | container 2 | 192.168.31.174 | 172.17.0.1/16 |
- (1) container1 ping container2

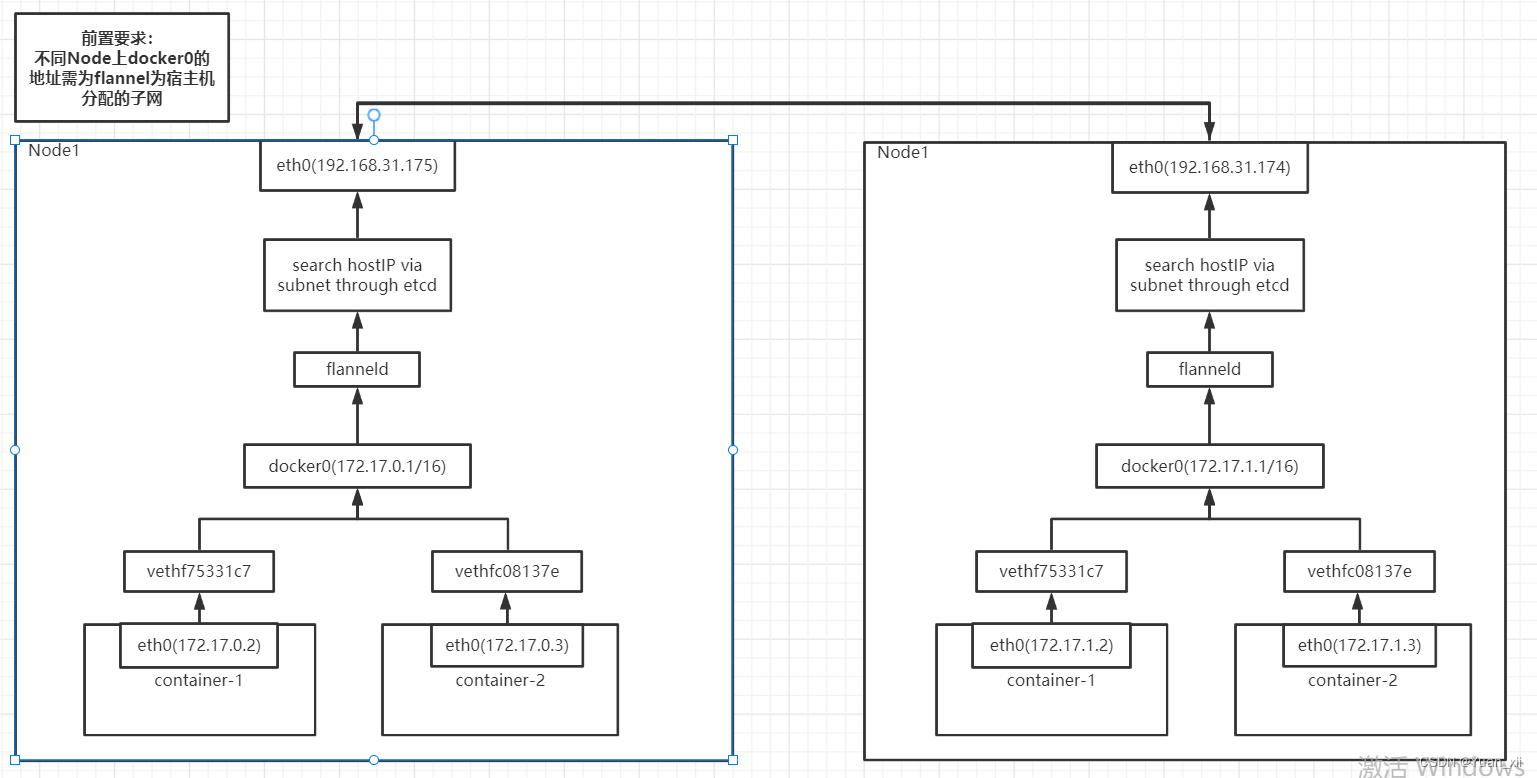
- TIP: 不同Node上docker0的地址需为flannel分配的子网
FLANNEL_SUBNET=10.244.0.1/24
dockerd --bip=$FLANNEL_SUBNET
flannel UDP模式为一个三层Overlay网络;
Flannel UDP模式效率低下,尽管采用该模式仅仅多了UDP封装这一步,但完成这一步进行了三次用户态与内核态之间的数据拷贝;
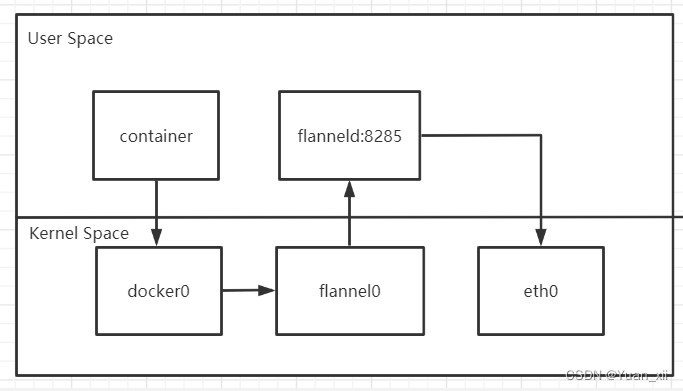
系统编程:减少用户态和内核态之间切换的次数,并将核心处理逻辑放在内核态中进行;
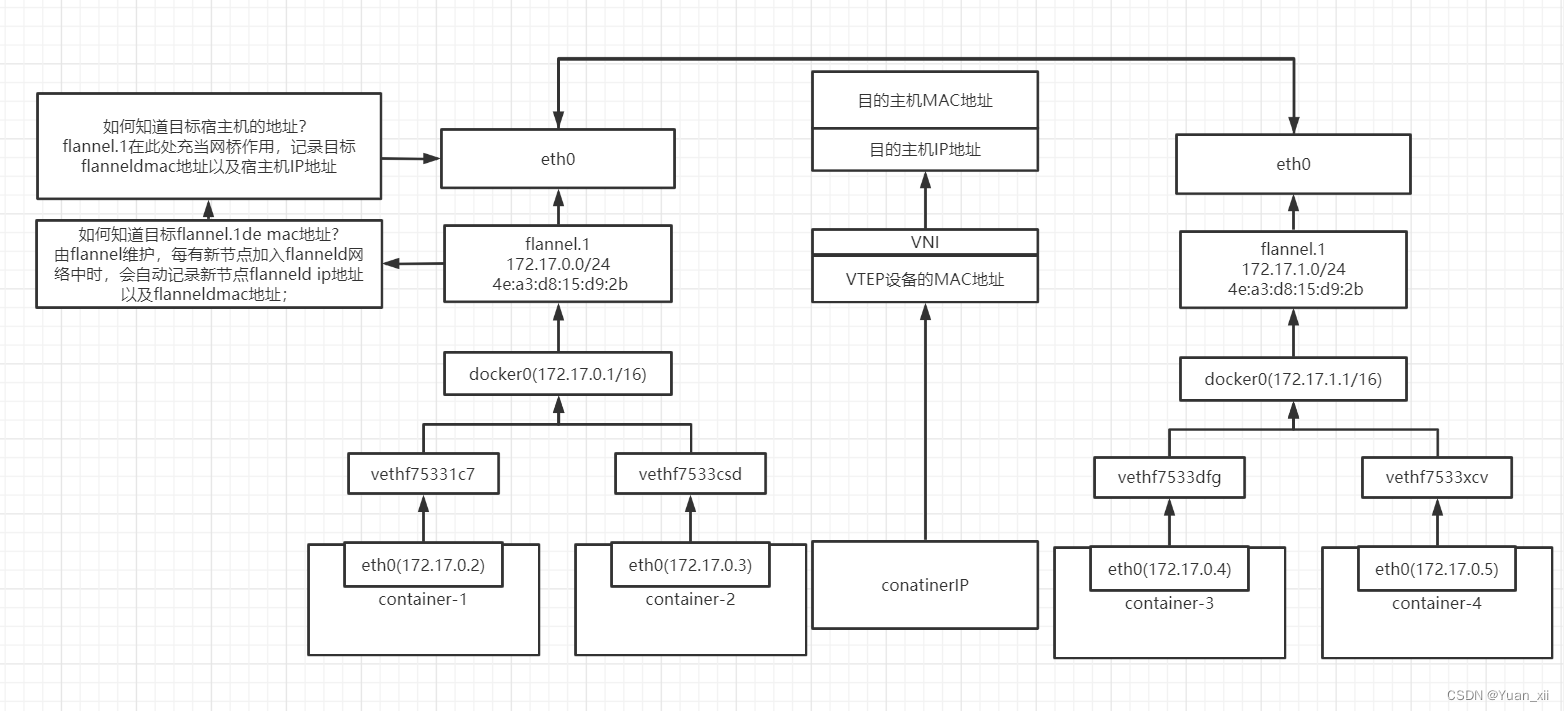
16.2.2.Virtual Extensible LAN
在现有的三层网络之上,覆盖一层由内核VXLAN模块负责的二层网络,使得连接在这个VXLAN二层网络上的主机之间,可以像在同一个局域网中自由通信。
VXLAN会在宿主机上设置一个特殊的网络设备作为隧道的两端,VTECP (VXLAN Tunnel End Point)
16.2.3.CNI网络插件
网络插件的目的是将不同宿主机上的特殊设备连通,实现宿主机之间的通信。
# 查看cni插件所需的基础可执行文件
ls -al /opt/cni/bin
16.2.3.1.Main插件
用于创建具体网络设备的二进制文件,如bridge,ipvlan,loopback,macvlan,ptp,vlan;
16.2.3.2.IPAM(IP Address Management)插件
负责分配IP地址的二进制文件;如dhcp
16.2.3.3.内置CNI插件
| 插件 | 解释 |
|---|---|
| flannel | 专门为flannel项目提供的CNI插件 |
| tuning | 通过sysctl调整那个网络设备参数的二进制文件 |
| portmap | 通过iptables配置端口映射的二进制文件 |
| bandwidth | 使用token bucket filter来进行限流的二进制文件 |
# flanneld启动后会为每台宿主机生成CNI配置文件
cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
处理网络相关的逻辑并不在kubelet主干代码里执行,而是会在具体的CRI(Container Runtime Interface)中实现;
对于Docker项目的的CRI为dockershim
16.3. 若出现容器连不通外网
- 检查能否ping通docker0网桥
- 检查和docker0和Veth Pair设备相关的iptables路由规则
16.3. Kubernetes三层网络模型
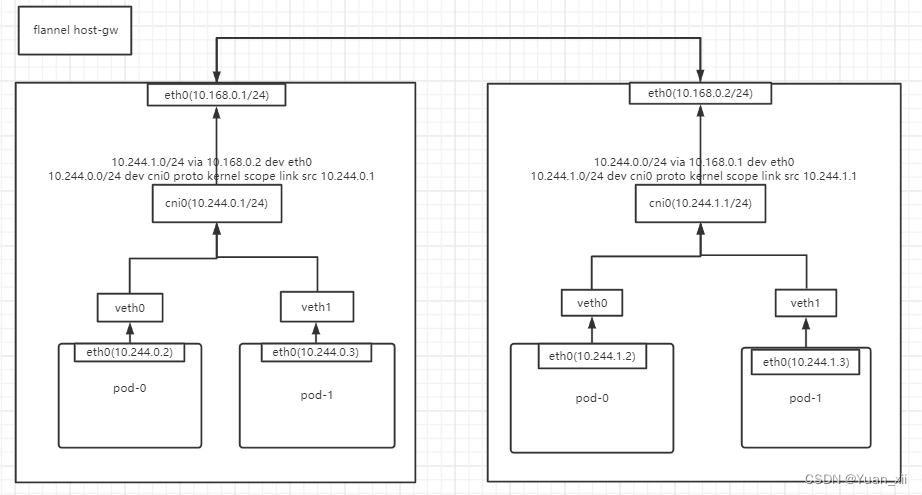
16.3.1.Flannel host-gw 模式
host-gw 是将每个flannel子网的下一跳地址设置为该子网对应的宿主机的IP地址;这些子网和主机的信息都保存在etcd种;flannel会watch这些数据并实时更新路由表;
16.3.2.Calico
Calico实现原理和flannel host-gw 几乎一样,不同之处在于Calico使用BGP在集群中分发维护路由信息;
BGP(Border Gateway Protocol): 边界网关协议,为linux内核原生支持,专门用于大规模数据中心维护不同自治系统之间的路由信息的,无中心的路由协议;
边界网关: 将若干个自治系统连接在一起的路由器;
Calico共分为3个部分,CNI插件,Felix,BIRD;
- CNI插件:在宿主机上为每个容器的Veth Pair设备配置路由规则;
- Felix:DaemonSet,通过FIB维护节点路由规则;
- BIRD:BGP客户端,负责在集群中分发路由规则信息;
calico BGP 协议会自动维护同一集群内所有节点的路由规则,自动为所有节点添加路由到其他节点的下一跳地址规则 ,见下图
目标子网网段/24 via 目标节点ip地址 eth0
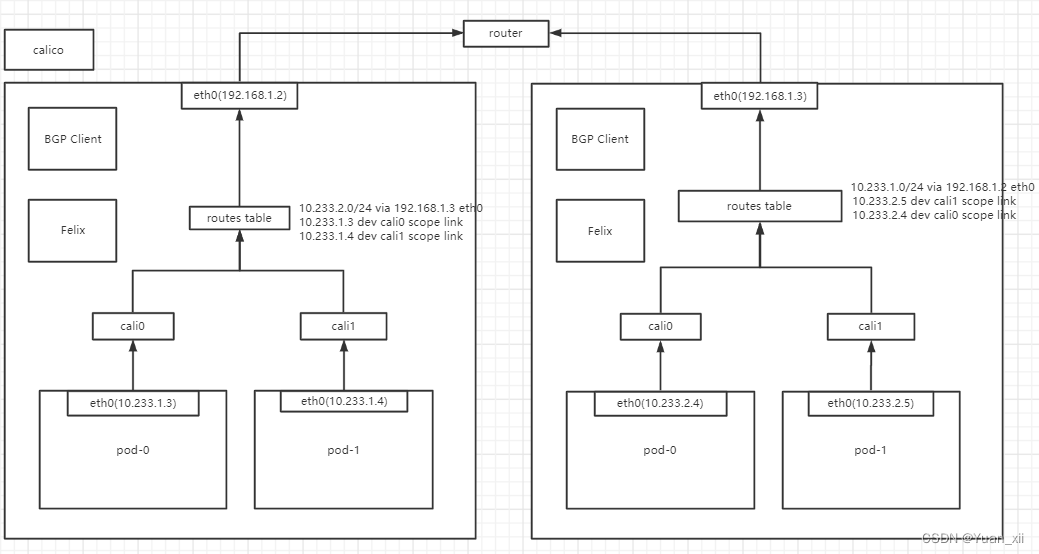
按照上述理论,Calico将集群里所有的节点都当做边界路由器来处理,各个边界路由器之间通过BGP协议交换路由规则。
在默认配置下,Calico维护的BGP模式为 Node-to-Node Mesh,每台宿主机上的BGP Client都需跟其他所有节点的BGP Client相互交换信息,交换链路共有 (n(n-1))/2; n为集群的节点数量;
若节点数量大于100,通常使用Route Reflector模式,在该模式下,Calico会专门会指定一个或几个专门的节点来负责为所有节点建立BGP连接从而学习到路由规则;
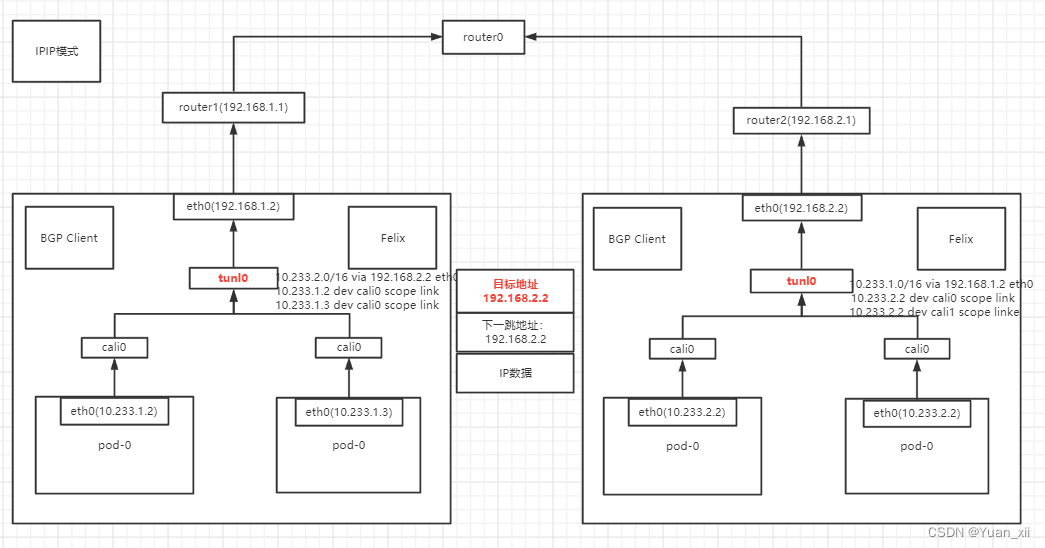
16.3.2.1.IPIP模式
flannel host-gw 和 Calico默认情况下要求集群宿主机之间是2层连通的,即如上图所示,这些节点处在同一个局域网网段内;假设有这样一种情况;
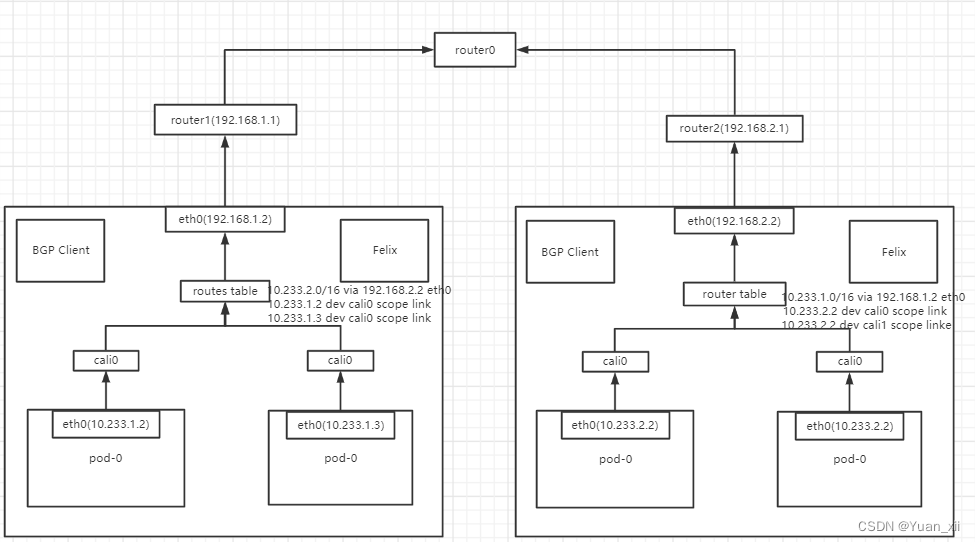
# pod-0(10.233.1.2)需要传输数据到pod-0(10.233.2.2)
# 目前路由表有的规则为
10.233.2.0/16 via 192.168.2.2 eth0
10.233.1.2 dev cali0 scope link
10.233.1.3 dev cali0 scope link
# 按照路由规则 10.233.2.0/16 via 192.168.2.2 eth0
# pod-0(10.233.1.2) -> 192.168.2.2,下一跳地址应该是 192.168.2.2, 但由于宿主机从eth0(192.168.1.1)无法找到该路由目标,因此会舍弃该包
IPIP模式:Felix会将上述
10.233.2.0/16 via 192.168.2.2 eth0
规则修改为
10.233.2.0/16 via 192.168.2.2 tunl0
tunl0是一个IP隧道设备,通过该设备,会将该包直接封装在一个宿主机网络的IP包中,通过网络传输给目标地址;
16.3.容器网络隔离
kubernetes里的Pod默认都是允许所有"Accept All",即对Pod的网络通信没有任何限制;Kubernetes使用NetworkPolicy来实现不同Pod之间的网络隔离;
| qosClass | 解释 |
|---|---|
| Guaranteed | Pod里每一个Contaniner同时都被设置了requests和limits,且requests和limits值相等 |
| Burstable | Pod至少一个Container设置了requests |
| BestEffort | Pod既没设置requests,也没设置limits |
cgroup cpuset: 为Pod绑定到某个固定的CPU核上,减少 CPU上下文切换的次数;
实现方式:将requests.cpu和limits.cpu 设置为相同的值;
kubernetes 调度器
调度器用户为新创建的Pod寻找一个最合适的节点;
Informer Path: 监听Etcd种Pod,Node,Service等API对象的变化,并将这些资源加入Priority Queue种;
Scheduling Path: 持续从Priority Queue中取出资源,执行Predicates算法过滤出一组Node节点,然后调用Priorities算法为为这些Node进行打分,取出分值最高的Node作为当前资源将要被调度的结果;
Predicates
过滤出所有符合Pod的节点;
(1) GeneralPredicates - PodFitsResources: 检查宿主机CPU和内存资源是否足够
(2) GeneralPredicates - PodFitsHostPorts: 检查Pod的spec.NodeName 和 spec.nodePort;
(3) GeneralPredicates - PodMatchNodeSelector: 检查Pod的nodeSelector, nodeAffinity指定的节点是否匹配;
(4) NoDiskConflict: 检查多个Pod声明挂载的持久化Volume是否有冲突;
(5) MaxPDVolumeCountPredicate: 检查节点声明的Volume数目是否超过一定数目;
(6) VolumeZonePredicate: 检查Volume的Zone标签是否和节点的Zone标签匹配;
(7) VolumeBindingPredicate: 检查Pod对应的PV的nodeAffinity字段是否和某个节点的标签匹配;
(8) NodeMemoryPressurePredicate: 检查当前节点的内存是否充分;
(9) PodAffinityPredicate: 检查当前Pod和Node上的Pod之间的亲密和反亲密关系是否符合;
Priorities
为Predicates中过滤出的所有节点进行打分;
# LeastRequestedPriority
# 选出剩余memory和cpu最多的宿主机
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
# BalancedResourceAllocation
#选出某个资源使用量最均匀的节点
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
https://time.geekbang.org/column/article/70519















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









