







前言
首先给大家放出完整代码,然后下面就是用jupyter写的代码。实际上在写的时候用的是jupyter写的,因为感觉jupyter写的时候更加的流畅,每一步运行的细节都能保存下来,更方便学习理解。
完整代码:
import os
import requests
import parsel
import re
url = 'http://www.xueshut.com/bijiaojj/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
response_decoded = response.text.encode('iso-8859-1').decode('gbk')
selector = parsel.Selector(response_decoded)
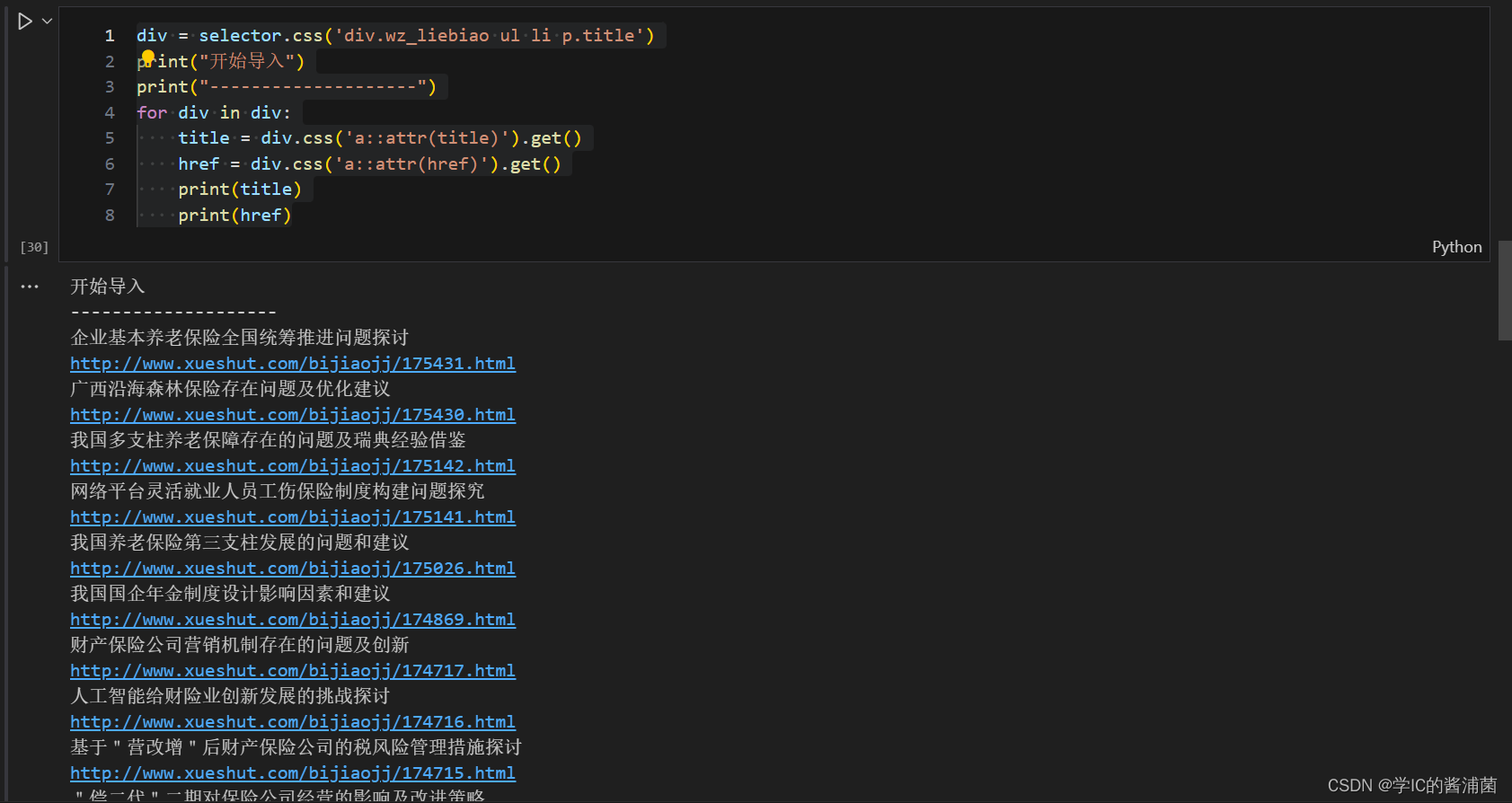
div = selector.css('div.wz_liebiao ul li p.title')
print("开始导入")
print("--------------------")
for div in div:
title = div.css('a::attr(title)').get()
href = div.css('a::attr(href)').get()
url_lunwen = href
response_lunwen = requests.get(url=url_lunwen,headers=headers).text.encode('iso-8859-1').decode('gbk')
selector_lunwen = parsel.Selector(response_lunwen)
title_lunwen = selector_lunwen.css('title').get()
keywords_lunwen = selector_lunwen.css('meta[name=keywords]::attr(content)').get()
content_lunwen = selector_lunwen.css('meta[name=description]::attr(content)').get()
print(f'开始下载:{title}')
if not os.path.exists(title):
with open(title,'a',encoding='utf-8') as f:
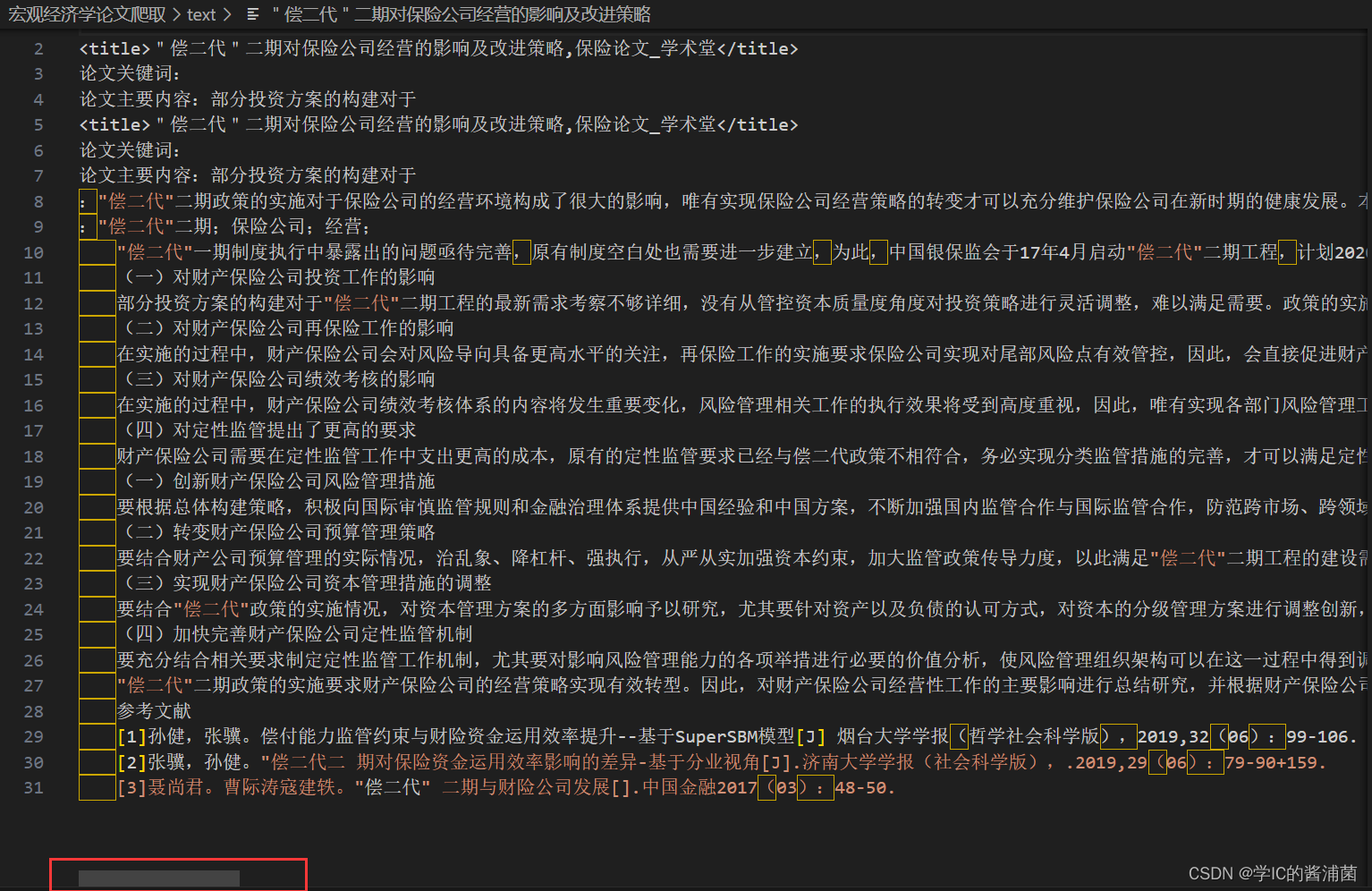
f.write('\n' + title_lunwen)
f.write('\n论文关键词:' + keywords_lunwen)
f.write('\n论文主要内容:' + content_lunwen)
if os.path.exists(title):
with open(title,'a',encoding='utf-8') as f:
f.write('\n' + title_lunwen)
f.write('\n论文关键词:' + keywords_lunwen)
f.write('\n论文主要内容:' + content_lunwen)
p = selector_lunwen.css('p::text')
for p in p:
with open(title,'a',encoding='utf-8') as f:
f.write('\n' + p.get())下面是jupyter上面运行的结果:
这里先用encode和decode编码和进行解码,因为直接拿到的响应体是乱码的一个状态
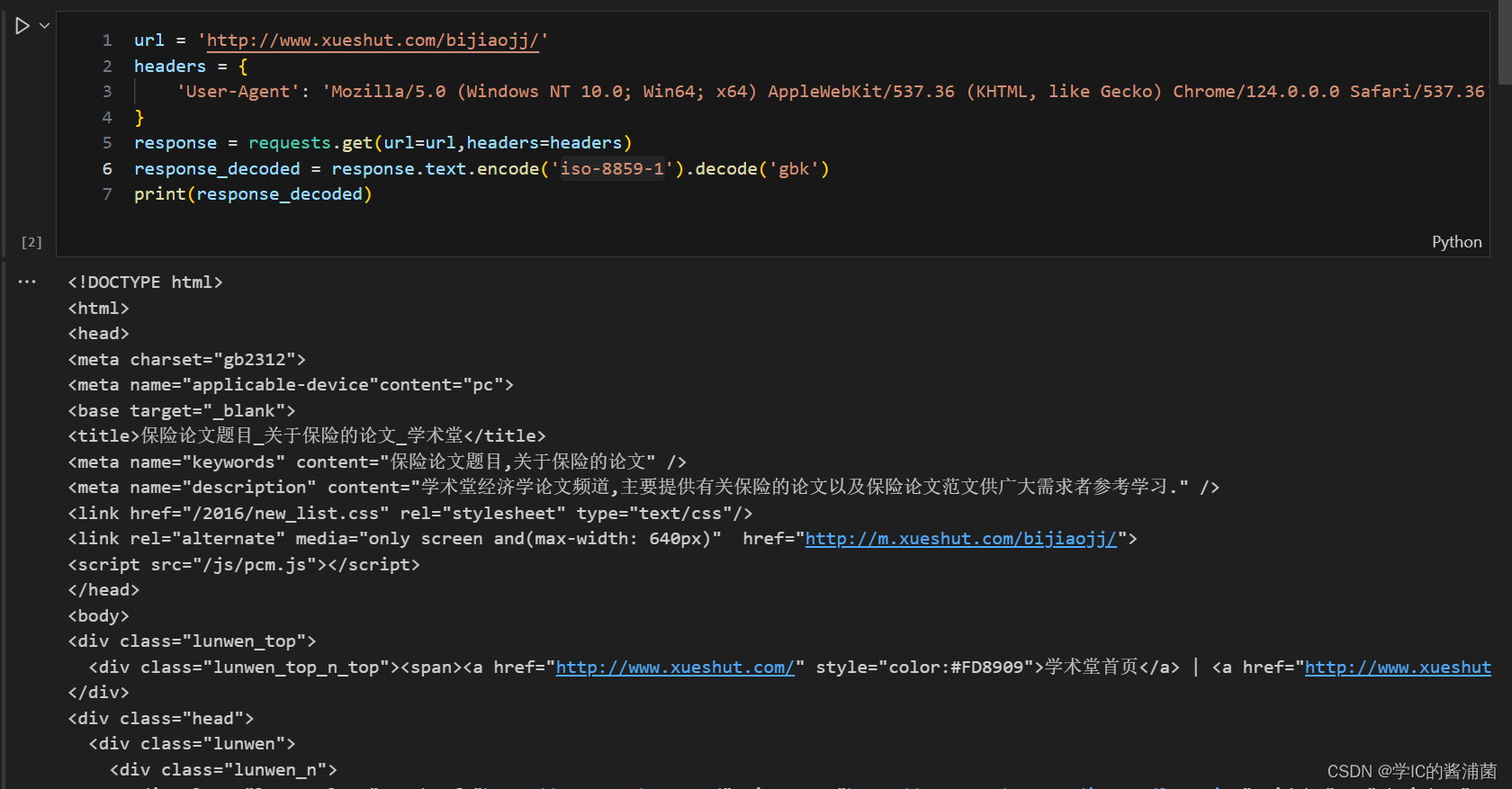
这里先打印论文的相关信息看一下,然后再进行爬取。

这里直接获取论文标题和链接 ,这里先用css选择器选择div标签,css选择器里面标签后面加点,表明的是某个属性的标签。比如说title属性的p标签,wz_liebiao属性的div标签。
然后再爬取论文链接的响应体。 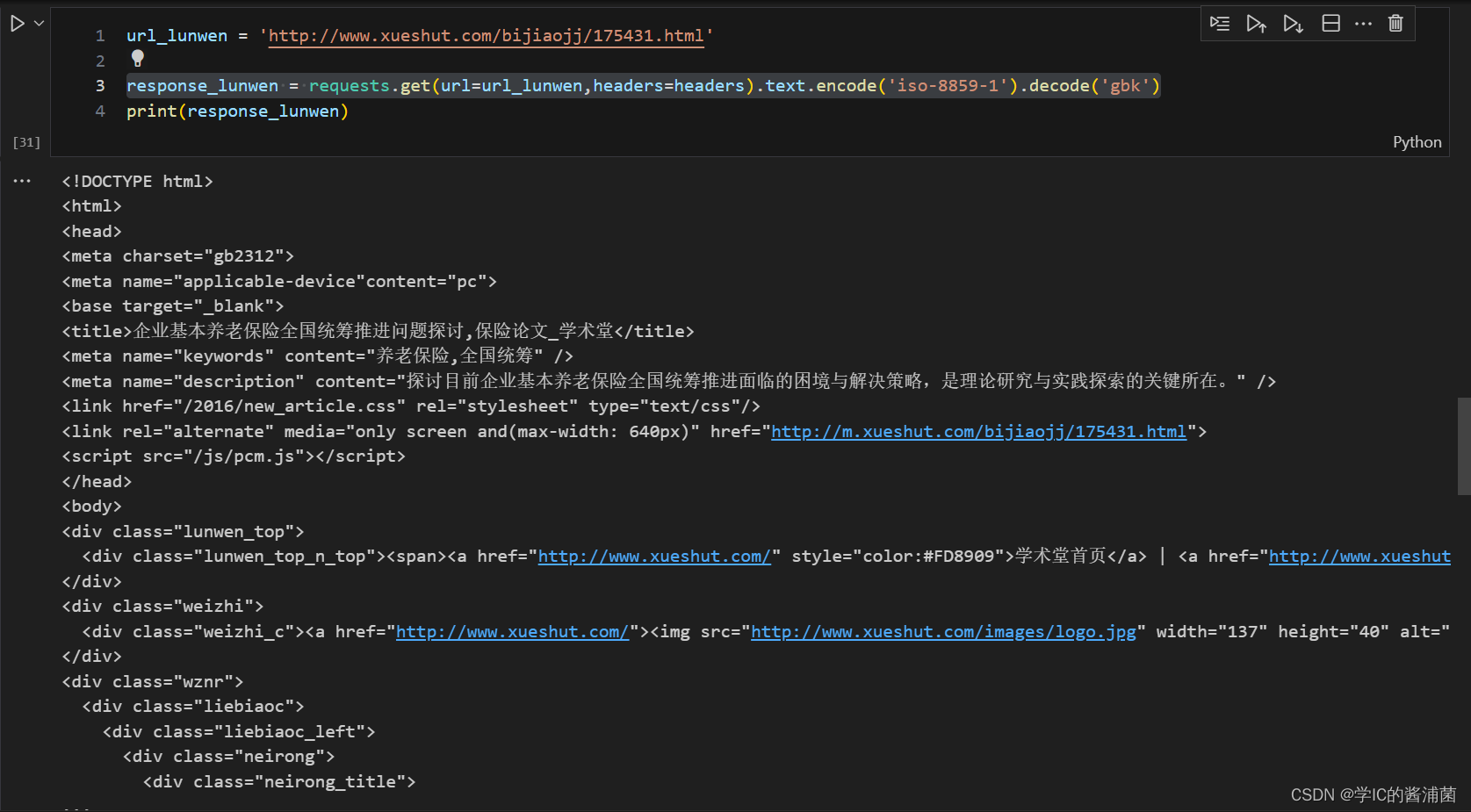
然后就是用with open来写入数据到text文件里面,进行保存。

项目的整个结构以及爬取的效果如下:
















 7457
7457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









