







知识点
requests、BeautifulSoup、csv 等库的简单使用
高德地图 JavaScript API 的使用
1.安装需要的库:
sudo pip3 install --upgrade pip
sudo pip3 install bs4
sudo pip3 install lxml
用到三个文件:crawl.py、rent.csv与index.html,其中:
crawl.py 是一个非常简单的爬取网页的脚本。
rent.csv 由 crawl.py 生成,是房源文件。
index.html 是最重要的显示地图的部分。
实现的流程大致如下:

我为什么不把 js 代码和 css 代码从 index.html 中分出来呢,写脚本怎么顺手怎么来就好。
代码没有难度,主要就是看看几个 API 如何使用,下面给出文档链接:
高德 JavaScript API 帮助文档
高德 JavaScript API 示例中心
Requests: HTTP for Humans
Beautiful Soup 4.2.0 文档
本节将通过实践操作,带领大家利用高德 API 和 Python 解决租房问题。
注意:由于前端页面可能会经常发生变动,大家在这里主要掌握这种分析方法,如果页面发生了变化依然可以按照对应的方法进行爬取。
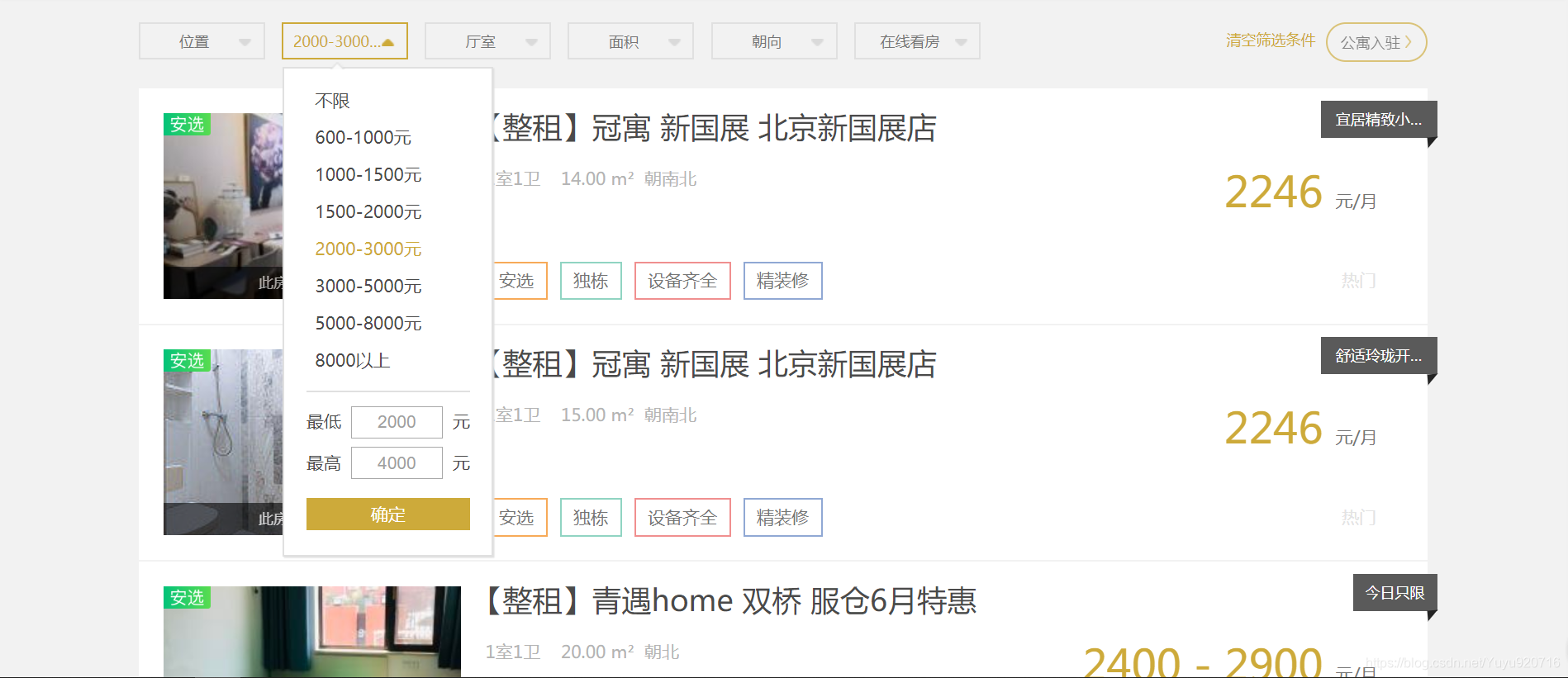
2.分析一下我们需要爬取的页面:https://bj.58.com/pinpaigongyu/。
选择好目标价位:
按 F12 键或右键点击检查分析元素:
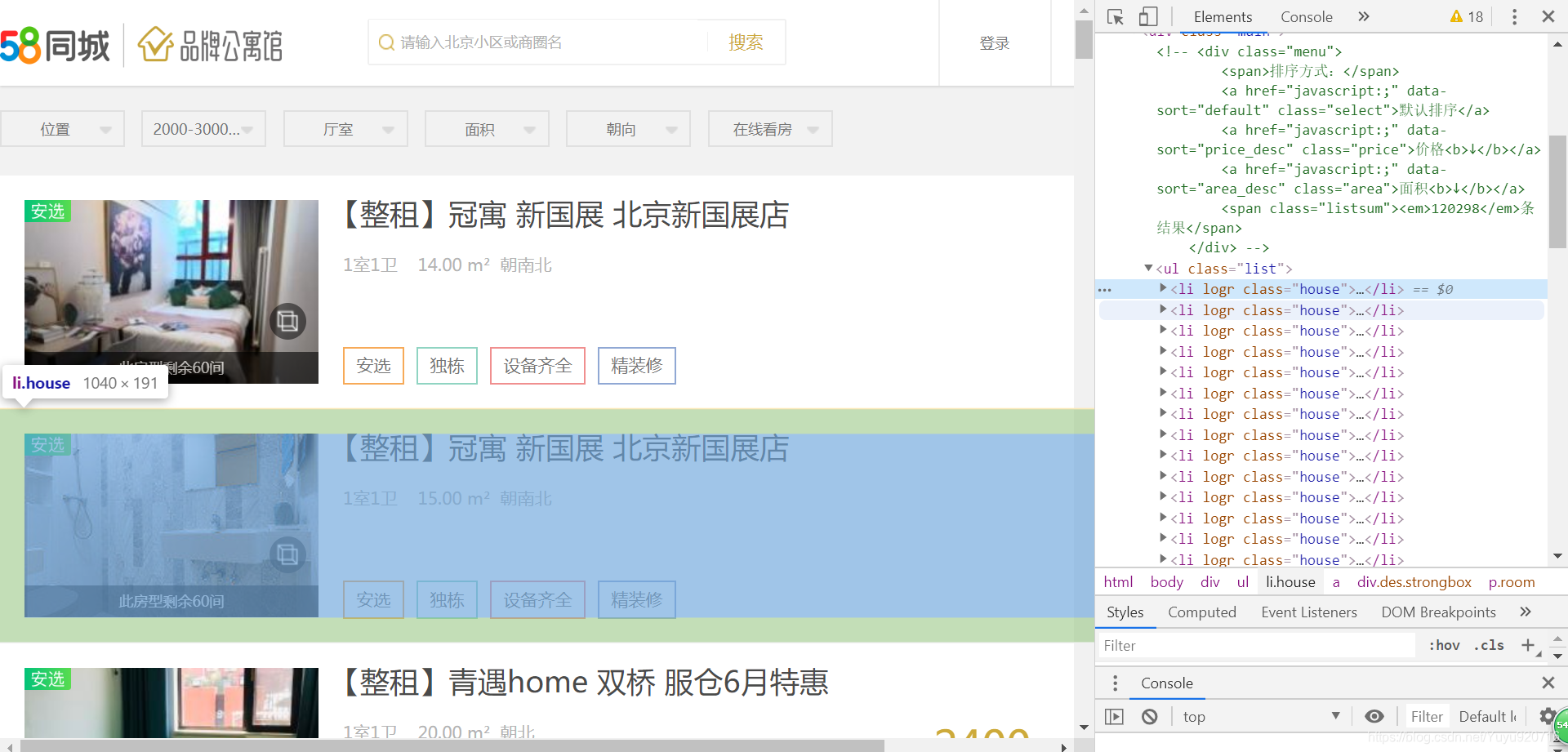
我们发现所有的租房信息都是一个 li 标签,并且都位于 ul 标签下,当我们往下移的时候,相应的标签也会越来越多,所以我们便可以利用有无 list 类来判定是否为租房请求。当然,这是在没有任何条件获取到的全部信息,但很多信息我们是不会看的,既然有租房的意愿,那么我们就有一个大致的心理承受价格,因此我们可以来分析一下该网站的 url 构造形式,大致了解了它的路径规则:/pingpaigongyu/pn/{page}/minprice={min_rent}_{max_rent}。
看一下页面能够提供给我们什么信息:

框框圈出的信息对我们来说已经足够了,点进去后还可以查看其他各类信息:
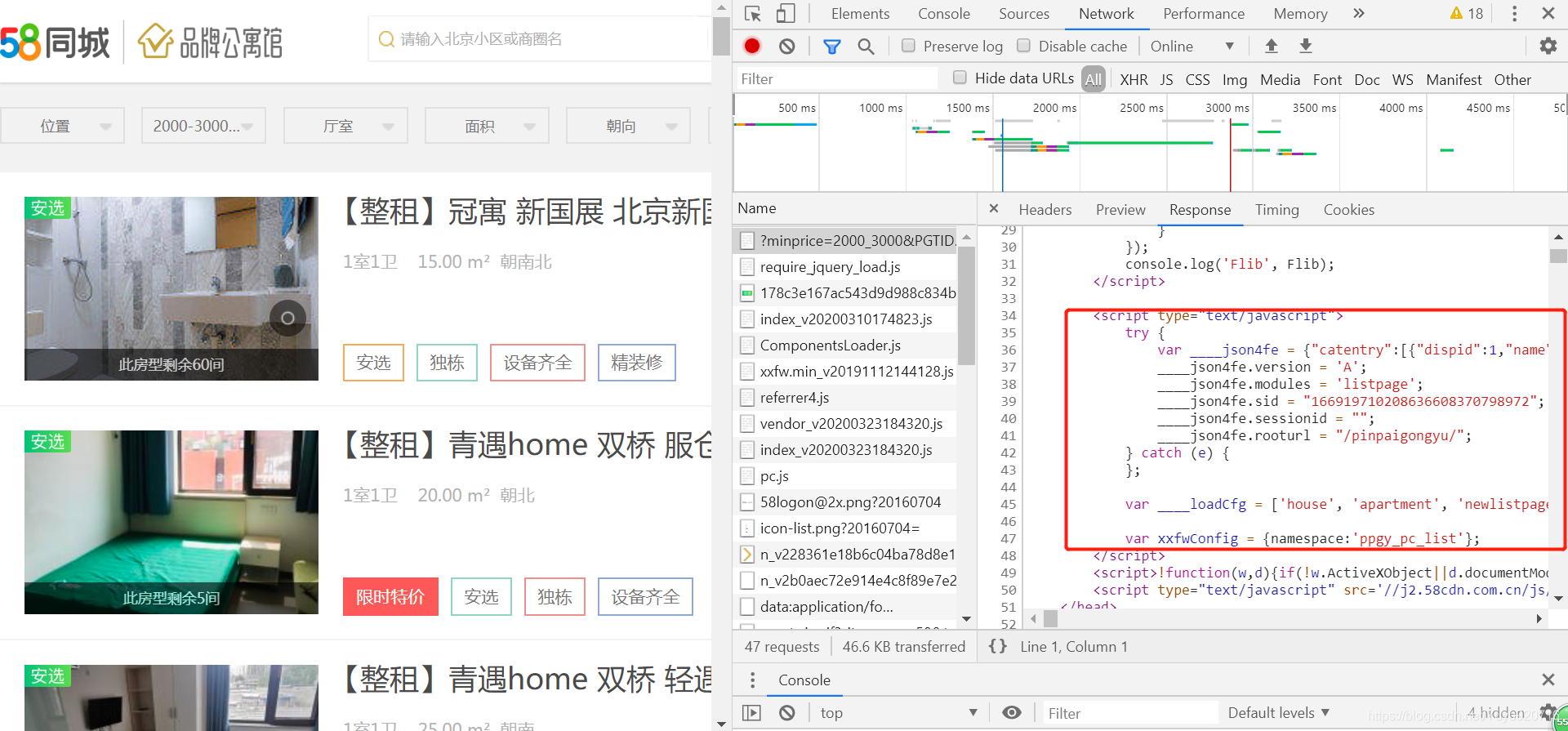
这些信息有些是经过了加密,并不一定准确,然后我们就可以根据以上信息来写一个小的爬虫程序。
创建 crawl.py 文件,这里先直接给出全部代码。
#!/usr/bin/env python3
from bs4 import BeautifulSoup # 网页解析模块
import requests # 网络请求模块
import csv # csv 文件模块
import time
import lxml
# 网址
url = "https://bj.58.com/pinpaigongyu/pn/{page}/?minprice=2000_4000"
# 初始化页码
page = 0
# 打开rent.csv文件,如果没有就创建一个,并设置写入模式
csv_file = open("rent.csv","w",encoding="utf-8")
# 创建writer对象
csv_writer = csv.writer(csv_file, delimiter=',')
# 循环所有页面
while True:
page += 1
print("fetch: ", url.format(page=page))
time.sleep(1)
# 抓取目标页面
response = requests.get(url.format(page=page))
# 设置编码模式
response.encoding = 'utf-8'
# 创建一个BeautifulSoup对象,获取页面正文
html = BeautifulSoup(response.text,features="lxml")
# 获取当前页面的房子信息
house_list = html.select(".list > li")
# 循环在读不到新的房源时结束
if not house_list:
break
# 房子信息
for house in house_list:
# 获取房子标题
house_title = house.select("h2")[0].string
# 获取房子链接地址
house_url = house.select("a")[0]["href"]
# 对标题进行分隔
house_info_list = house_title.split()
# 如果第二列是公寓名则取第一列作为地址
if "公寓" in house_info_list[1] or "青年社区" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string
# 写入一行数据
csv_writer.writerow([house_title, house_location, house_money, house_url])
# 关闭文件
csv_file.close()
鉴于爬的量不大所以就简单处理了。代码中已经给出了大部分注释,这里只对requests、BeautifulSoup、csv 库的使用进行说明:
csv 一般用作表格文件,直接用文本编辑器打开也可读,行与行之间就是换行来隔开,列与列之间就是用逗号(也可指定其它字符)隔开,Python 标准库中的 csv 库就是用来读写 csv 文件的。
requests 是一个对使用者非常友好的 http 库,看一遍 Quickstart 就能基本掌握它的使用。
用到它的地方也就仅仅两句:
# 抓取目标页面
response = requests.get(url.format(page=page))
# 获取页面正文
response.text
Beautiful Soup 是一个用来解析 html 或者 xml 文件的库,支持元素选择器,使用起来也非常方便:
# 创建一个 BeautifulSoup 对象
html = BeautifulSoup(response.text,features="lxml")
# 获取 class=list 的元素下的所有 li 元素
house_list = html.select(".list > li")
# 得到标签包裹着的文本
house.select("h2")[0].string
# 得到标签内属性的值
house.select("a")[0]["href"]
由于该网站设置了反爬虫机制非常容易被屏蔽。因此在每次爬取页面时使用 time.sleep(1),1 代表 1 秒。讲解完毕,运行代码 python3 crawl.py。注意如果是非会员在实验环境中不能联网,执行爬取的操作大家可以在本地进行)。等执行完毕查看目录会发现已经生成了 rent.csv 文件:

因为反爬虫以及数据加密的原因所以数据可能是乱码的,大家可以使用这个文件继续接下来的实验。
wget https://labfile.oss.aliyuncs.com/courses/599/rent.csv

后面我们需要从本地导入这个文件,大家需要下载这个文件到本地。
页面大框架可直接从示例中心复制:高德 JavaScript API 示例中心。
在 /home/project 目录下新建 index.html 复制粘贴下面的设计页面代码:
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta
name="viewport"
content="initial-scale=1.0, user-scalable=no, width=device-width"
/>
<title>毕业生租房</title>
<link
rel="stylesheet"
href="http://cache.amap.com/lbs/static/main1119.css"
/>
<link
rel="stylesheet"
href="http://cache.amap.com/lbs/static/jquery.range.css"
/>
<script src="http://cache.amap.com/lbs/static/jquery-1.9.1.js"></script>
<script src="http://cache.amap.com/lbs/static/es5.min.js"></script> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1669
1669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









