









1. SSL安全认证
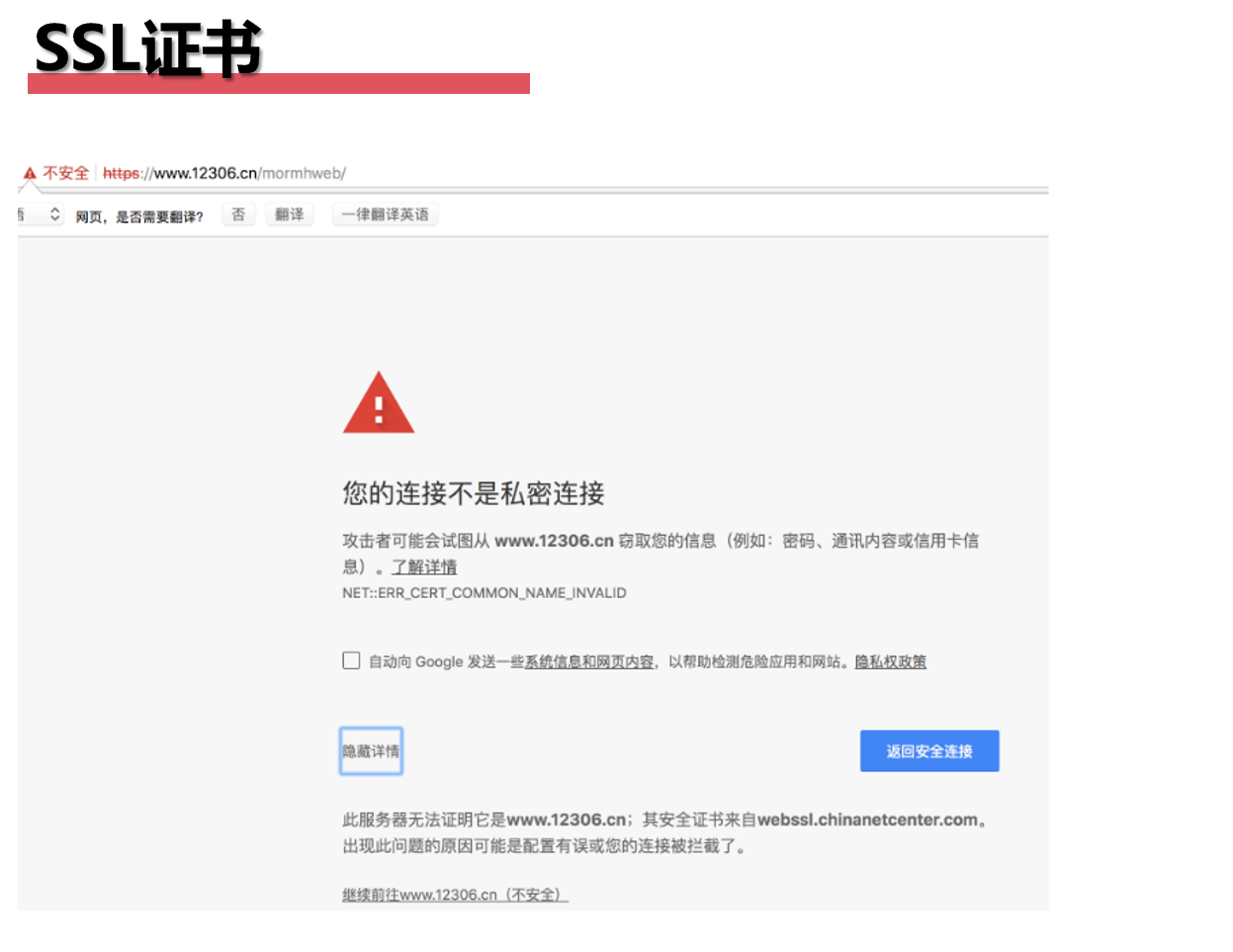
原因:SSL的证书不安全导致 浏览器需要安装证书
"""
爬虫程序:SSLError
request.get(url,header=header,verify=False) 避开难
http协议
https协议 >> http + ssl 加密
"""
2. 代理IP
需求:短时间内多次访问同一个服务器 1s/100次
之前我们学过:
用户代理池:每一次请求都是一个不同的User-Agent,成功地骗过服务器
账户池:每一次请求都是一个不同的Cookie,成功地骗过服务器
2.1 为什么要使用代理
1.让服务器以为不是同一个客户端在请求
2.防止我们的真实地址被泄露,防止被追究
2.2 代理IP分类:
1.透明代理:毫无作用,服务器可以简单的检测到你使用了代理IP,并且知道你的真实IP
2.匿名代理:服务器可以简单的检测到你使用了代理IP,但是它检测不到你的真实IP
3.高匿代理:服务器既检测不到你使用了代理IP,也无法知道你的真实IP
建议付费代理IP 免费的就是不行
2.3 代理IP的使用
使用的是真实IP
import requests
if __name__ == '__main__':
url_ = 'https://www.baidu.com/'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
response_ = requests.get(url_, headers=headers_)
print(response_.text)
使用代理IP
import requests
if __name__ == '__main__':
url_ = 'https://www.baidu.com/'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 构造代理IP字典
# proxies代理IP字典中的键名(协议头) --> 需要跟请求的url协议头类型保持一致
# proxies代理IP字典中的键值--> 协议头类型://IP地址:端口号 (必须是英文输入法状态下的冒号)
proxies_ = {
'http': 'http://1.1.1.1:8888'
}
# # 使用上代理IP,假的代理IP,无法使用的代理IP
response_ = requests.get(url_, headers=headers_, proxies=proxies_)
print(response_.text)
花钱购买的代理IP,也并不是百分之百全部能用的 1000个代理IP,800能用,200不能够使用
requests库的升级
requests库升级前:无法使用的代理IP,会直接报错
requests库升级后:如果代理IP无法使用,它就会使用你的真实IP
坏处是:无法过滤掉无法使用的代理IP
1000个 >> 800
如何处理:
特殊的url:http://myip.ipip.net/
import requests
if __name__ == '__main__':
# 特殊测IP的url
url_ = 'http://myip.ipip.net/'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 使用上代理IP,一个真实有效付费代理
proxies_ = {
'http': 'http://20.210.113.32:80'
}
response_ = requests.get(url_, headers=headers_, proxies=proxies_)
str_data = response_.text
print(str_data)
使用假的代理IP
import requests
if __name__ == '__main__':
# 特殊测IP的url
url_ = 'http://myip.ipip.net/'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 使用上代理IP,假的代理IP
proxies_ = {
'http': 'http://1.1.1.1:8888'
}
response_ = requests.get(url_, headers=headers_, proxies=proxies_)
str_data = response_.text
print(str_data)
一个代理IP池
1000个代理IP 使用循环 每一个代理IP 如果报错,就把它从代理IP池中移除
import requests
import random
if __name__ == '__main__':
# 付费代理IP池
ip_list = ['15.204.161.192:18080', '20.210.113.32:80', '20.111.54.16:8123', '20.24.43.214:80', '20.24.43.214:8123',
'20.111.54.16:80']
ip = random.choice(ip_list)
print(ip)
# 特殊测IP的url
# url_ = 'http://myip.ipip.net/'
# 访问目标网站
url_ = 'https://www.jd.com'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 使用上代理IP,一个真实有效付费代理
proxies_ = {
'http': f'http://{ip}'
}
response_ = requests.get(url_, headers=headers_, proxies=proxies_)
str_data = response_.text
print(str_data)
3. timeout参数的使用
遇到网络波动怎么办?
解决办法:使用超时参数timeout
规定你的响应时间
每一个代理IP的响应时间不一样
1.剔除掉不能够使用的代理IP
2.有些响应时间过长,timeout用来剔除掉响应时间过长的代理IP
import requests
if __name__ == '__main__':
# 特殊测IP的url
url_ = 'http://myip.ipip.net/'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 使用上代理IP,假的代理IP
proxies_ = {
'http':'http://1.1.1.1:8888'
}
response_ = requests.get(url_,headers=headers_,proxies=proxies_,timeout=3) # 设置响应时间,秒为单位
str_data = response_.text
print(str_data)
import requests
import random
if __name__ == '__main__':
# 付费代理IP池
ip_list = ['15.204.161.192:18080', '20.210.113.32:80', '20.111.54.16:8123', '20.24.43.214:80', '20.24.43.214:8123',
'20.111.54.16:80', '000']
while True:
try:
ip = random.choice(ip_list)
print(ip)
# 特殊测IP的url
# url_ = 'http://myip.ipip.net/'
# 访问目标网站
url_ = 'https://www.jd.com'
headers_ = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
# 使用上代理IP,一个真实有效付费代理
proxies_ = {
'http': f'http://{ip}'
}
response_ = requests.get(url_, headers=headers_, proxies=proxies_, timeout=3)
str_data = response_.text
print(f'代理{ip}使用成功~~~~~~~')
print(str_data)
break
except:
print(f'代理{ip}异常,重新使用新的代理!!!!')
4. retrying模块
为什么:
使用超时参数能够加快我们整体的请求速度,但是在正常的网页浏览过成功,如果发生速度很慢的情况,我们会做的选择是刷新页面,那么在代码中,我们是否也可以刷新请求呢?
怎么做:
使用retrying模块提供的retry模块
通过装饰器的方式使用,让被装饰的函数反复执行
"""
如果由瞬间的网络波动,导致请求不成功 0.01s
在这种情况下,多给几次机会发送请求,避免开由于瞬间的网络波动导致的请求不成功
"""
"""
第三方模块 pip install retrying -i https://pypi.doubanio.com/simple
"""
# from retrying import retry
# retry是一个三层函数的嵌套,并且返回了内部函数的引用 闭包
# 三层 >> 有参数的装饰器
import requests
from retrying import retry
class AAAA:
def __init__(self):
self.url_ = 'xxxx.com'
self.num_ = 0
@retry(stop_max_attempt_number=3)
def send_request(self):
self.num_ += 1
print(self.num_)
requests.get(self.url_)
def run(self):
try:
self.send_request()
except Exception as e:
print(e)
if __name__ == '__main__':
a = AAAA()
a.run()
模拟瞬间的网络波动,只会进行一次请求 根据打印结果 1 2 3 就证明发送请求的那部分代码执行了三遍 retry的一个效果















 2133
2133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









