






一、安装labelimg
pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ labelimg二、使用labelimg标记图片
1.新建文件夹
1. 在yolov7目录下新建一个名为VOCData的文件夹

2. 在VOCData文件夹下创建 Annotations 和 images 文件夹

[说明]:
-
Annotations 文件夹用于存放使用labelimg标记后的图片(XML格式)
-
images 文件夹用于存放用于标记的图片
(【注意】:images 文件夹下直接放图片,内部不要嵌套有文件夹,否则之后训练可能会出现 No label found 的错误)
[为什么]:
在 yolov7 的 utils 文件夹打开 dataloaders.py文件后,搜索define,便可以找到这样的一段代码:

该段代码的作用是由images文件夹的地址直接推出labels文件夹的位置,所以我们存储图片的文件必须叫做images,同时labels文件必须和images文件必须在同一目录下
2.标记图片
-
在cmd窗口下输入
labelimg或者运行labelimg.py文件进入labelimg的可执行程序(注:在虚拟环境下安装的labelimg记得先激活虚拟环境) -
分别设置需要标注图片的文件夹和存放标记结果的文件夹的地址

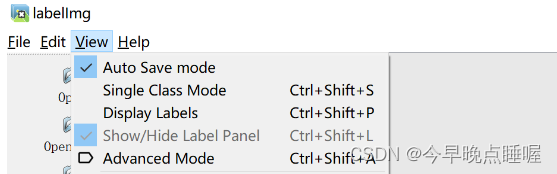
3. 推荐设置自动保存
4. 标记图片快捷键:w:标记 a:上一张图片 d:下一张图片
5. 在Annotations文件夹下可以看到我们标记好的XML文件

三、 划分数据集以及配置文件修改
1. 划分训练集、验证集、测试集
在VOCData目录下创建程序 split_train_val.py 并运行以下代码。代码可以不做任何修改
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.9 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()运行结束后会在生成一个名为 ImageSets 的文件夹:

[说明]:
训练集是用来训练模型的,通过尝试不同的方法和思路使用训练集来训练不同的模型
验证集使用交叉验证来挑选最优的模型,通过不断的迭代来改善模型在验证集上的性能
测试集用来评估模型的性能
2.XML格式转yolo_txt格式
在VOCData目录下创建程序 xml_to_yolo.py 并运行以下代码,注意:
-
将classes改为自己标注时设置的类名(我这里叫"fall")
-
将各个绝对路径修改为自己的
-
\ 是 python中的转义字符,所以表示地址时要使用 \取消转义,或者/
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["fall"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('E:/AI/yolov7/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('E:/AI/yolov7/VOCData/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('E:/AI/yolov7/VOCData/labels/'):
os.makedirs('E:/AI/yolov7/VOCData/labels/')
image_ids = open('E:/AI/yolov7/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('E:/AI/yolov7/VOCData/dataSet_path/'):
os.makedirs('E:/AI/yolov7/VOCData/dataSet_path/')
# 这行路径不需更改,这是相对路径
list_file = open('dataSet_path/%s.txt' % image_set, 'w')
# 图片格式为jpg则设置为 .jpg, 如果为png则设置为 .png。否则会出现路径找不到的问题
for image_id in image_ids:
list_file.write('E:/AI/yolov7/VOCData/images/%s.jpg\n' % image_id)
convert_annotation(image_id)
list_file.close()运行后会生成如下图所示的 dataSet_path和 labels文件夹。dataSet_path下会有三个数据集的txt文件,labels下存放各个图像的标注文件
其中 labels 中为不同图像的标注文件。每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式,这种即为 yolo_txt格式


3.配置文件
在 yolov7 的 data 文件夹下创建一个名为 myvoc.yaml,模板如下,根据自己实际情况填写: 【注意】:注意冒号后面是有空格的
train: E:/AI/yolov7/VOCData/dataSet_path/train.txt
val: E:/AI/yolov7/VOCData/dataSet_path/val.txt
# number of classes
nc: 1
# class names
names: ["fall"]4.聚类获得先验框
-
获取anchors yolov7可以在
utils文件夹下找到autoanchor.py文件,它的作用是自动获取anchors,因此我们不需要额外的操作。

2. 在 cfg 文件夹下找到 training/yolov7x.yaml(如果使用这个权重模型训练的话),将其中的 nc 改为实际上标注类的数量,和 myvoc.yaml一样(记得保存)。

3. 修改train.py文件


四、使用CPU训练
-
在cmd窗口下激活相应虚拟环境后 cd 到 yolov7 文件夹后,输入下列指令即可开始训练
python train.py --weights yolov7x.pt
--cfg cfg/training/yolov7x.yaml
--data data/myvoc.yaml --epoch 200
--batch-size 8 --img 640 --device cpu[参数说明]:
--weights :权重文件所在的相对路径
--cfg:存储模型结构配置文件的相对路径
--data:存储训练、测试数据的文件的相对路径
--epoch:训练过程中整个数据集将被迭代(训练)了多少次
--batch-size:训练完多少张图片才进行权重更新
--img:自适应缩放输入图片的尺寸为指定大小。在YOLOv5中,输入图像的大小需要是正方形,并且是 32 的倍数
--device:选择用CPU或者GPU训练
【注意】:在指定路径的时候需要注意,在python中,\是转移字符,如果我们想要表示路径,则需要使用/或者\取消转义
(开始训练)
2. 运行error
错误1:
定位在71行:在run_id = torch.load(weights)中加上,map_location='cpu'

错误2:
可能是标记的数据没有加载到文件夹。这里我重新运行VOCData的.py文件,即可成功运行

3. 可以在E:\AI\yolov7\runs\train\exp10文件夹中查看训练相关的信息

4. 预测与测试
训练得到的模型保存在runs/train/exp/weights里面,使用best.pt模型,其余模型可以删除,
修改detect.py

使用下面的命令,其中,weights使用最满意的训练模型即可,source则提供一个包含所有测试图片的文件夹路径即可。
python detect.py --weights runs/exp10/weights/best.pt
--source VOCData/images/ --device cpu五、训练可视化
训练时或者训练后可以利用 tensorboard 查看训练可视化
tensorboard --logdir=runs六、 连接本地摄像头
-
在E:\AI\yolov7\utils\datasets.py代码下

-
在E:\AI\yolov7\utils\general.py代码下修改


-
在E:\AI\yolov7\detect.py下修改

-
最后,运行detect.py文件
刚开始打不开相机,以为是权限问题,后来发现系统的也打不开,开始以下操作:
打开注册表设置 (1)打开cmd命令行,输入regedit,按下回车打开注册表; (2)在注册表中依次展开:(注意双击哟)HKEY_LOCAL_MACHINE~SOFTWARE~Microsoft~Windows Media Foundation~Platform; 在右边空白处点击右键,新建DWORD(32位)值; (4)直接输入命名为 EnableFrameServerMode 点击确定即可; (5)退出,重新打开相机
















 2552
2552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









