






一、前言
前几天在Python粉丝问了一个Python网络爬虫的问题,这里拿出来给大家分享下。
他自己的代码应该挺久之前的了,暂时还用不了,因为网页结构发生了大变化,所有原来的字段全部都变化了,还好逻辑没怎么变化,一起来看看吧。
import requests
import time
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive",
"From-Domain": "51job_web",
"Origin": "https://we.51job.com",
"Referer": "https://we.51job.com/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35",
"account-id": "",
"partner": "",
"property": "%7B%22partner%22%3A%22%22%2C%22webId%22%3A2%2C%22fromdomain%22%3A%2251job_web%22%2C%22frompageUrl%22%3A%22https%3A%2F%2Fwe.51job.com%2F%22%2C%22pageUrl%22%3A%22https%3A%2F%2Fwe.51job.com%2Fpc%2Fsearch%3Fkeyword%3D%25E9%2587%2591%25E8%259E%258D%26searchType%3D2%26sortType%3D0%26metro%3D%22%2C%22identityType%22%3A%22%22%2C%22userType%22%3A%22%22%2C%22isLogin%22%3A%22%E5%90%A6%22%2C%22accountid%22%3A%22%22%7D",
"sec-ch-ua": "\"Microsoft Edge\";v=\"113\", \"Chromium\";v=\"113\", \"Not-A.Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sign": "aeed648e6141b18dd1c49117a9338bb8c44ce3803b98e0b973d632346da193e8",
"user-token": "",
"uuid": "064dee39ac7e7feee763f449b69faa9a"
}
cookies = {
"guid": "064dee39ac7e7feee763f449b69faa9a",
"sajssdk_2015_cross_new_user": "1",
"sensorsdata2015jssdkcross": "%7B%22distinct_id%22%3A%22064dee39ac7e7feee763f449b69faa9a%22%2C%22first_id%22%3A%221881fb7bd6e278-04937d5dc2e5a98-7b515477-921600-1881fb7bd6f20b%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTg4MWZiN2JkNmUyNzgtMDQ5MzdkNWRjMmU1YTk4LTdiNTE1NDc3LTkyMTYwMC0xODgxZmI3YmQ2ZjIwYiIsIiRpZGVudGl0eV9sb2dpbl9pZCI6IjA2NGRlZTM5YWM3ZTdmZWVlNzYzZjQ0OWI2OWZhYTlhIn0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%24identity_login_id%22%2C%22value%22%3A%22064dee39ac7e7feee763f449b69faa9a%22%7D%2C%22%24device_id%22%3A%221881fb7bd6e278-04937d5dc2e5a98-7b515477-921600-1881fb7bd6f20b%22%7D",
"nsearch": "jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D",
"search": "jobarea%7E%60%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%BD%F0%C8%DA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21",
"acw_tc": "ac11000116841593187302414e00e0549c125d5ad342ec325b0211a4e1ec13",
"uid": "wKhJRWRiO1dsWBM3SVrMAg==",
"JSESSIONID": "00DEC3853A738DF9B12A498C25728575",
"ssxmod_itna": "iq+xyD0Dg7f+DCDzameG=04AKP7KDOWK9QmlYljDBw7T4iNDnD8x7YDvmA5GimDhDnIYKFrWPxi/FOY7LpY8rCpnsGmDB3DEx06ibIDYYCDt4DTD34DYDixib1xi5GRD0KDFF5XUZ9Dm4GWFqGfDDoDY86RDitD4qDBmOdDKqGgFq267mt3puqeoGGcD0tdxBL=tPhcGeaariNexanDHEQDzqHDtutS9Ld3x0PyBMUDx8GaDODoU84NFK4NGDeqGBwdDS4ei2wx3GD344Mx/GxdCt1eDD34iiCjYiD==",
"ssxmod_itna2": "iq+xyD0Dg7f+DCDzameG=04AKP7KDOWK9QmlYlD8TpYcTxeGX=e4GaD=bUoDHYjrKGF0hBIxO5oQBYYNe2xrrXd3+zkgj+gUaDMrYexcLychm1ztZ6deZm65+y2PNlblmqh5KQbV7iHsAay72g+GyYehd=yz5UPCqA7+/iH3zrnmeDrtkhqtkr9TZlOCiZYY1KmIyebNdK3zzBYAWhATwKLLBPex7rK3KtSDKSnXe+T2q=grSxvW6UnRkC3r1zmkP6mCehvueO0=oL5x5rBO1RpgrrPuZjjdwqv1INskegtntfV=9o/win1UyRYuwnqkURgYw1QYO3yBDPR0rDd9rSu4ZvbKyqyBS/cg0hiRYM4o/QOGQgOA7Aj7eVqHtR3g7NGYHnKk8BdNDFFyUmEsjOnQgP+yd5G4ygYygesgbkWN2h0B4H42Kx531wo63aqcbgRDew3ZAY=3HGG7soYQ3iwobWxDKu5SBqR0zGB45xP1AWnP3RqXS=YWx6D7=DYK4eD="
}
url = "https://cupidjob.51job.com/open/noauth/search-pc"
f = open('job.csv', mode='a', encoding='utf-8')
for k, v in dic.items():
# 循环1--35页
for page in range(1, 36):
print(f"正在抓取第{page}页...")
time.sleep(3)
params = {
"api_key": "51job",
"timestamp": "1684159452",
"keyword": f"{v}",
"searchType": "2",
"function": "",
"industry": "",
"jobArea": "000000",
"jobArea2": "",
"landmark": "",
"metro": "",
"salary": "",
"workYear": "",
"degree": "",
"companyType": "",
"companySize": "",
"jobType": "",
"issueDate": "",
"sortType": "0",
"pageNum": f"{page}",
"requestId": "0266bbd1054b9bb1ec7a0066e6e5060c",
"pageSize": "20",
"source": "1",
"accountId": "",
"pageCode": "sou|sou|soulb"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
# print(response.text)
# print(response.json())
rows = response.json()["resultbody"]
# 字典取值
for row in rows["job"]["items"]:
job_name = row["jobName"] # 岗位标题
city = row["jobAreaString"] # 城市
salary = row["provideSalaryString"] # 薪水
# print(job_name, city, salary)
# # 职位要求基本信息完全的才输出:岗位标题+城市+薪水
# if len(row["jobTags"]) != 3:
# print(11)
# continue
education = row["degreeString"] # 学历
company_name = row["fullCompanyName"] # 公司名称
field = row["industryType1Str"] # 领域
# print(education, company_name, field)
working_years = row["workYearString"] # 工作年限
jobwelf_list = "|".join(row["jobTags"]) # 福利
companytype_text = row["companyTypeString"] # 公司性质
companysize_text = row["companySizeString"] # 公司人数
print(working_years, jobwelf_list, companytype_text, companysize_text)
f.write(f"{job_name}, {city}, {salary}, {education}, {company_name}, {field}, "
f"{working_years}, {jobwelf_list}, {companytype_text}, {companysize_text}\n") # 记得加\n
二、实现过程
这里针对之前的代码进行了修改,修改之后就可以跑了,如下所示:
代码运行之后,可以得到预期的数据:
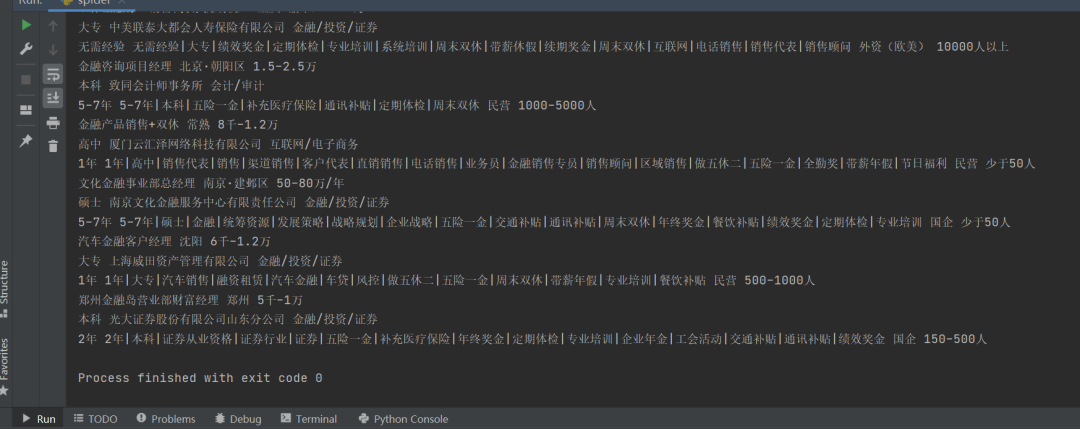
针对一个岗位,大概有几千条数据吧。

在实际测试的时候,如果要爬另外一个岗位,需要更换cookie,原因不详,不然的话,就抓不到对应的信息。
抓到信息后,你可以存入数据库,然后做一些web界面,做一些数据分析等等,一篇小论文就出来啦,当然拿去交大作业,也是可以的。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

最后
我们准备了一门非常系统的爬虫课程,除了为你提供一条清晰、无痛的学习路径,我们甄选了最实用的学习资源以及庞大的主流爬虫案例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
我们把Python的所有知识点,都穿插在了漫画里面。
在Python小课中,你可以通过漫画的方式学到知识点,难懂的专业知识瞬间变得有趣易懂。


你就像漫画的主人公一样,穿越在剧情中,通关过坎,不知不觉完成知识的学习。
02 无需自己下载安装包,提供详细安装教程

03 规划详细学习路线,提供学习视频


04 提供实战资料,更好巩固知识

05 提供面试资料以及副业资料,便于更好就业


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】
















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









