







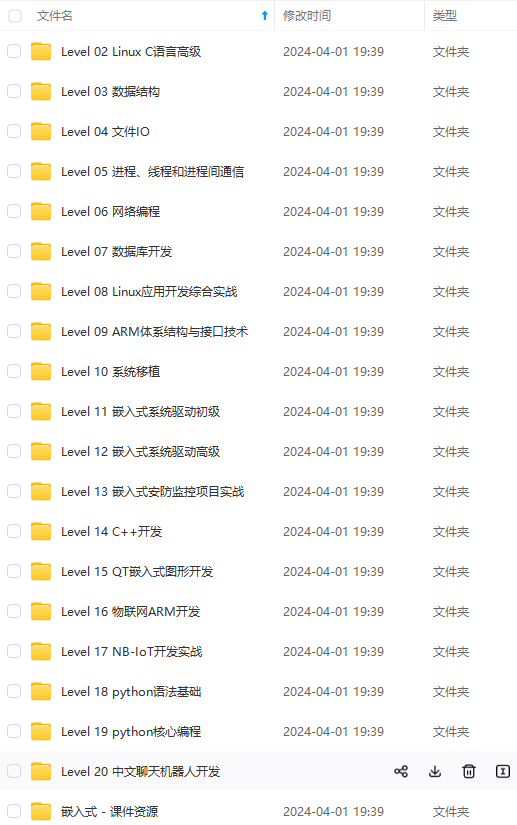
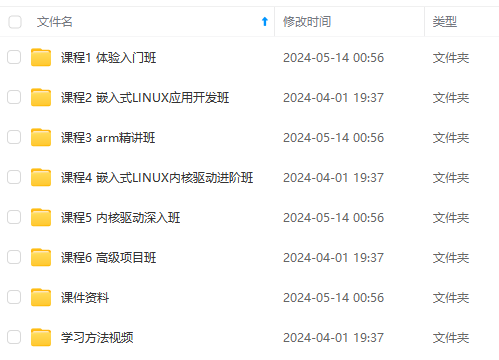
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
def main():
job_list = []
key = "数据挖掘"
dqs = ["010", "020", "050020", "050090", "030", "060080", "040", "060020", "070020", "210040", "280020", "170020"]
new_key = urllib.parse.quote(key, 'utf-8')
for item in dqs:
url = "https://www.liepin.com/zhaopin/?key="+new_key+"&dqs="+item
print(url)
# 获取职位列表链接
job_html = get_job_html(url)
# 解析网页分析网页得到链接
link_list = get_job_link(job_html)
# 把链接储存到数组中
for i in link_list:
job_list.append(i)
# 保存职位链接到表格中
save_link(job_list)
2. 获取网页
- 这里获取网页调用一个包:(from fake_useragent import UserAgent)
- 需要在pip中安装:pip install fake_useragent
- 首先要构造一个请求头:猎聘网的反爬虫不是很强大,不用登录就可以访问,调用UserAgent().random 可以随机生成浏览器标识,这样就不会被阻止
- 如果网站的反扒做的很好就要在网页的请求头上添加相应的参数,参考如下图

参考代码:
def get\_job\_html(url):
print("-------爬取job网页-------")
html = ""
head = {
"User-Agent": UserAgent().random
}
"""
head:模拟浏览器头部信息
"User-Agent":浏览器标识
"""
request = urllib.request.Request(url=url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except Exception as e:
return None
return html
3. 解析网页
- 分析网页元素获取数据

- 由于每一个页
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









