







文章目录
一、项目简介
1.项目背景
目前搜索引擎技术已经是非常成熟了,很多网站,应用等都有属于自己搜索引擎。但是哪一个的性能好,哪一个用户用着舒服,就说不定了。搜索引擎虽然只是做搜索的,但是在各个地方都有用到,是许多系统必不可少的功能。而且搜索时间短,匹配度高,满足用户心意的搜索引擎才是最重要的。鉴于此,我也想做一个搜索引擎,锻炼自己的业务能力,加深自己对这方面技术的掌握程度。
2.项目描述
本项目主要实现了在前端输入框内输入需要搜索的Java API文档的关键字,对后端发出请求,后端将处理后的结果返回给前端,按照一定的权重排序展示若干个搜索结果,每个搜索结果包含了标题,描述,展示URL,可点击标题跳转,查看文档的详细内容。
3.项目条件
- 开发环境:IDEA、Tomcat 9、Maven、JDK1.8
- 相关技术:正排索引、倒排索引、分词技术、过滤器、Servlet、Json、Ajax
- 文档资源:我用的是jdk源码文件包解压之后的Java API文档,下载地址:点击这里
二、项目设计
1.数据库设计
(1)创建数据库“searcher”,在该数据库下创建正排索引表,包括文档id(docid)、标题(title)、url、文档内容(content),用于保存项目构建的正排索引;
CREATE TABLE `searcher`.`forward_indexes` (
`docid` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) NOT NULL,
`url` varchar(200) NOT NULL,
`content` longtext NOT NULL,
PRIMARY KEY (`docid`)
) COMMENT='正排索引';
(2)创建倒排索引表,包括字段id、关键词(word)、文档id(docid)、单词权重(weight),用于保存构建的倒排索引;
CREATE TABLE `searcher`.`inverted_indexes` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(100) NOT NULL,
`docid` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`)
) COMMENT='倒排索引';
2.保存数据的实体类
(1)Document:
每一个 api 文档的 html 文件都对应一个该类,在该类中主要有四个属性字段,分别是:
docId:类似于数据库的主键可以对应单独一个文档
title:文档的文件名
url:Oracle 官网上的 api 文档下 html 的 url 地址
content:文档的正文部分
public class Document {
@Getter @Setter
private Integer docId;
@Getter
private final String title;
@Getter
private final String url;
@Getter
private final String content;
(2)InvertedRecord:
该类表示的是某个关键词在某个文档中的权值,在该类中主要有三个属性字段,分别是:
word:关键词
docId:该关键词对应的文档的id
weight:该关键词在该文档中的权值
public class InvertedRecord {
private final String word;
private final int docId;
private final int weight;
}
(3)Result:
该类表示的是将搜索内容进行分词后,会得到多个关键词,每个关键词会对应多个文档,而其中不乏出现重复的文档,这时就需要对重复文档进行合并,用文档 ID 作为唯一标识,将 ID 相同的文档的权值根据关键字先后顺序不同进行加权操作,最终所有会匹配到的文档都是唯一的,根据权值对其进行排序后返回前端展示。在该类中主要有三个属性字段,分别是:
title:该文档的标题
url:该文档的 url
decs:该文档的描述
public class Result {
private final String title;
private final String url;
private final String desc;
}
3.构建索引
索引构建程序原则上只执行一次即可,所以我们单独创建一个项目包indexer,存放构建索引的业务代码。下面是具体实现:
(1)遍历 api 文档存储的目录,对每个 html 文件进行读取解析,去掉多余的标签,并且将需要的信息提取出来并且封装到实体类 Document中,然后将所有提取到的信息持久化到本地的 文件中。具体实现:
public class DocumentBuilder {
private static final String SUFFIX = ".html";
private final IndexProperties properties;
@Autowired
public DocumentBuilder(IndexProperties properties) {
this.properties = properties;
}
public Document build(File rootFile, File docFile) {
String title = parseTitle(docFile);
String url = parseUrl(rootFile, docFile);
String content = parseContent(docFile);
return new Document(title, url, content);
}
@SneakyThrows
private String parseTitle(File file) {
String name = file.getName();
return name.substring(0, name.length() - SUFFIX.length());
}
@SneakyThrows
private String parseUrl(File rootFile, File docFile) {
String rootPath = rootFile.getCanonicalPath().replace('\\', '/');
String docPath = docFile.getCanonicalPath().replace('\\', '/');
String relativePath = docPath.substring(rootPath.length());
if (properties.getUrlPrefix().endsWith("/")) {
return properties.getUrlPrefix() + relativePath.substring(1);
} else {
return properties.getUrlPrefix() + relativePath;
}
}
@SneakyThrows
private String parseContent(File file) {
StringBuilder contentBuilder = new StringBuilder();
try (InputStream is = new FileInputStream(file)) {
try (Scanner scanner = new Scanner(is, "ISO-8859-1")) {
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
contentBuilder.append(line).append(" ");
}
}
}
return contentBuilder.toString()
.replaceAll("<script.*?>.*?</script>", " ") // 去掉 <script ...>...</script>
.replaceAll("<[^>]*>", " ") // 去掉所有标签 <...>
.replaceAll("&.*?;", " ") // 去掉 HTML 转义符
.replaceAll("\\s+", " ") // 合并空白字符
.trim(); // 去掉首尾空白字符
}
}
(2)首先加载本地文件内容,加载到正排索引的集合中,根据正排索引构建倒排索引(标题权重10,内容权重1),具体实现如下:
首先有一个 Map<String,Integer> 集合表示一个关键词对应多个 api 文档,然后遍历存储所有 DocInfo 类的 List,对于每一个 Doc都分别对标题和内容进行分词。
所以这里引入分词技术,分词技术使用的是一个开源的分词工具 Ansj,可以很高效的将句子进行分词处理。我们将分词之后的关键词加入 Map 集合,关键词作为键,Weight类作为值,用来保存每个关键词在对应的每个 api 文档中的权值。对于权值的计算,我们自定义的认为如果出现在标题中那么权值 乘10,如果出现在文章中,那么权值 +1,从而构建好倒排索引。具体代码实现如下:
public class docunment{
@Getter @Setter
private Integer docId;
@Getter
private final String title;
@Getter
private final String url;
@Getter
private final String content;
private final Map<String, Integer> titleWordCountMap = new HashMap<>();
private final Map<String, Integer> contentWordCountMap = new HashMap<>();
public Document(String title, String url, String content) {
this.title = title;
this.url = url;
this.content = content;
}
public Map<String, Integer> segWordAndCalcWeight() {
segTitleWord();
segContentWord();
Set<String> wordSet = new HashSet<>(titleWordCountMap.keySet());
wordSet.addAll(contentWordCountMap.keySet());
Map<String, Integer> wordToWeight = new HashMap<>();
for (String word : wordSet) {
int weight = calcWeight(word);
wordToWeight.put(word, weight);
}
return wordToWeight;
}
private int calcWeight(String word) {
int countInTitle = titleWordCountMap.getOrDefault(word, 0);
int countInContent = contentWordCountMap.getOrDefault(word, 0);
return countInTitle * 10 + countInContent;
}
private static final Set<String> ignoredNatureStrSet;
static {
ignoredNatureStrSet = new HashSet<>();
ignoredNatureStrSet.add("w");
}
private void segContentWord() {
segAndCount(title, titleWordCountMap);
}
private void segTitleWord() {
segAndCount(content, contentWordCountMap);
}
private void segAndCount(String s, Map<String, Integer> map) {
Result result = ToAnalysis.parse(s);
List<Term> termList = result.getTerms();
List<String> wordList = termList.stream()
.filter(term -> !ignoredNatureStrSet.contains(term.getNatureStr()))
.map(Term::getName)
.collect(Collectors.toList());
for (String word : wordList) {
int count = map.getOrDefault(word, 0);
map.put(word, count + 1);
}
}
}
4.存放索引
将构建好的索引插入到提前创建好的数据库表中,方便查找。这里用到多线程的知识,是因为文档数据太过庞大,存放到数据库中,插入速度太慢,采用线程,提升性能,缩短时间。
public class IndexManager {
private final IndexProperties properties;
private final ExecutorService executorService;
private final IndexDatabaseMapper mapper;
@Autowired
public IndexManager(IndexProperties properties, ExecutorService executorService, IndexDatabaseMapper mapper) {
this.properties = properties;
this.executorService = executorService;
this.mapper = mapper;
}
//向数据库中插入正排索引
@SneakyThrows
public void addForwardIndex(List<Document> documentList) {
int batchSize = properties.getForwardIndexBatchInsertSize();
int listSize = documentList.size();
int countDown = (int) Math.ceil(listSize * 1.0 / batchSize);
log.info("保存正排索引需要提交 {} 批任务。", countDown);
CountDownLatch latch = new CountDownLatch(countDown);
AtomicInteger complete = new AtomicInteger(0);
for (int i = 0; i < listSize; i += batchSize) {
int from = i;
int to = from + batchSize;
Runnable runnable = () -> {
List<Document> subList = documentList.subList(from, to);
int count = mapper.batchInsertForwardIndex(subList);
int c = complete.addAndGet(count);
// log.info("插入正排索引 {} 个,一共 {} 个。", c, listSize);
latch.countDown();
};
executorService.submit(runnable);
}
latch.await();
}
//插入倒排索引
@SneakyThrows
public void addInvertedIndex(List<Document> documentList) {
int batchSize = properties.getInvertedIndexBatchInsertSize();
int groupSize = properties.getInvertedIndexBatchInsertGroupSize();
int listSize = documentList.size();
int countDown = (int) Math.ceil(listSize * 1.0 / groupSize);
log.info("保存正排索引需要提交 {} 批任务。", countDown);
CountDownLatch latch = new CountDownLatch(countDown);
for (int i = 0; i < listSize; i += groupSize) {
int from = i;
int to = from + groupSize;
Runnable runnable = () -> {
List<Document> subList = documentList.subList(from, to);
List<InvertedRecord> list = new ArrayList<>();
for (Document document : subList) {
Map<String, Integer> wordToWeight = document.segWordAndCalcWeight();
Set<Map.Entry<String, Integer>> entries = wordToWeight.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
String word = entry.getKey();
int weight = entry.getValue();
InvertedRecord record = new InvertedRecord(word, document.getDocId(), weight);
list.add(record);
if (list.size() == batchSize) {
mapper.batchInsertInvertedIndex(list);
// log.info("提交一次倒排索引记录,一共 {} 个。", list.size());
list.clear();
}
}
}
mapper.batchInsertInvertedIndex(list);
// log.info("提交一次倒排索引记录,一共 {} 个。", list.size());
list.clear();
latch.countDown();
};
executorService.submit(runnable);
}
latch.await();
}
}
5.搜索功能
这一部分是需要多次执行的,所以需要重新创建项目包web,用于存放搜索模块的代码。
首先接收前端发来的请求信息(搜索内容),使用分词技术对搜索内容进行分词操作,会得到多个关键词,根据先后排序有不同的权重,从第一个关键词开始查找,可以得到单个分词的 Weight 集合,里面包括包含该分词的所有文档及其权值。但是对于多个分词而言,可能出现一个文档包含多个分词的情况,所以这样就会出现文档重复的情况,这时需要对搜索到的文档进行合并操作。具体实现如下:
@Controller
public class QueryController {
private final ResultBuilder resultBuilder;
private final DatabaseMapper mapper;
@Autowired
public QueryController(ResultBuilder resultBuilder, DatabaseMapper mapper) {
this.resultBuilder = resultBuilder;
this.mapper = mapper;
ToAnalysis.parse("预热分词");
}
@GetMapping("/web")
public String query(String query, @RequestParam(value = "page", required = false) String pageStr, Model model) {
if (query == null) {
return "redirect:/";
}
query = query.trim();
if (query.isEmpty()) {
return "redirect:/";
}
int limit = 20;
int offset = 0;
int page = 1;
if (pageStr != null) {
try {
page = Integer.parseInt(pageStr);
offset = (page - 1) * limit;
} catch (NumberFormatException ignored) {}
}
List<String> queryList = ToAnalysis.parse(query)
.getTerms()
.stream()
.parallel()
.map(Term::getName)
.filter(s -> !s.trim().isEmpty())
.collect(Collectors.toList());
if (queryList.isEmpty()) {
return "redirect:/";
}
query = queryList.get(0);
final String word = query;
List<Result> resultList = mapper.query(query, offset, limit)
.stream()
.parallel()
.map(doc -> resultBuilder.build(doc, word))
.collect(Collectors.toList());
model.addAttribute("query", query);
model.addAttribute("docList", resultList);
model.addAttribute("page", page);
return "query";
}
}
在使用过滤器初始化的时候,完成正排索引和倒排索引的构建,设置的字符集要根据文档本身内容的编码来定义,我用的是JDK的文档,所以它的编码是“ISO-8859-1”,数据响应格式是Json格式。
6.前端页面设计及渲染
(1)HTML前端静态搜索页
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文档搜索</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="container">
<i class="fa-brands fa-windows item"></i>
<div class="search-box">
<input type="text" class="search-btn" placeholder="搜索">
</div>
<i class="fa-solid fa-magnifying-glass item search-submit"></i>
</div>
<div class="time-box"></div>
<div class="poem">
<p>「夜阑卧听风吹雨,铁马冰河入梦来。」</p>
<p class="author">—— 陆游</p>
</div>
<div class="background"></div>
<script src="https://kit.fontawesome.com/44e73cd2d1.js" crossorigin="anonymous"></script>
<script>
const search = (query) => {
window.open('/web?query=' + encodeURIComponent(query), '_blank')
}
const oSearch = document.querySelector('.search-btn')
oSearch.addEventListener('focus', () => {oSearch.placeholder = ''})
oSearch.addEventListener('blur', () => {oSearch.placeholder = '搜索'})
oSearch.addEventListener('keydown', (event) => {
if (event.keyCode === 13 && oSearch.value.trim().length !== 0) {
search(oSearch.value.trim())
oSearch.value = ''
oSearch.blur()
}
})
document.querySelector('.search-submit').addEventListener('click', () => {
if (oSearch.value.trim().length !== 0) {
search(oSearch.value.trim())
oSearch.value = ''
}
})
const oTimeBox = document.querySelector('.time-box')
const updateTime = () => {
let now = new Date()
let hour = now.getHours()
let minute = now.getMinutes()
if (hour < 10) {
hour = '0' + hour
}
if (minute < 10) {
minute = '0' + minute
}
oTimeBox.textContent = `${hour}:${minute}`
let second = now.getSeconds()
let r = 60 - second
setTimeout(updateTime, r * 1000)
}
updateTime()
</script>
</body>
</html>
(2)搜索展示页
<!DOCTYPE html>
<html lang="zh-hans" xmlns:th="https://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title th:text="${query} + ' - 文档搜索'"></title>
<link rel="stylesheet" href="query.css">
</head>
<body>
<div class="header">
<div class="brand"><a href="/">文档搜索</a></div>
<form class="input-shell" method="get" action="/web">
<input type="text" name="query" th:value="${query}">
<button>文档搜索</button>
</form>
</div>
<div class="result">
<div class="result-item" th:each="doc : ${docList}">
<a th:href="${doc.url}" th:text="${doc.title}"></a>
<div class="desc" th:utext="${doc.desc}"></div>
<div class="url" th:text="${doc.url}"></div>
</div>
</div>
<div class="pagination">
<a th:href="'/web?query=' + ${query} + '&page=' + ${page - 1}">上一页</a>
<a th:href="'/web?query=' + ${query} + '&page=' + ${page + 1}">下一页</a>
</div>
</body>
</html>
(3)页面渲染
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
width: 100vw;
height: 100vh;
display: flex;
align-items: center;
justify-content: center;
position: relative;
overflow: hidden;
}
.container {
z-index: 1;
height: 60px;
background-color: rgba(255, 255, 255, .7);
padding: 0 8px;
border-radius: 30px;
backdrop-filter: blur(4px);
box-shadow: 0 0 5px 1px gray;
display: flex;
align-items: center;
justify-content: space-around;
}
.time-box {
z-index: 1;
position: absolute;
background-color: transparent;
height: 40px;
top: 40%;
line-height: 40px;
font-size: 40px;
text-align: center;
color: #fff;
text-shadow: 0 0 4px #000;
}
.search-box {
width: 200px;
transition: all .3s ease-in-out;
}
.container:hover .search-box,
.container:focus-within .search-box {
width: 440px;
}
.container .item {
margin: auto 20px;
font-size: 20px;
opacity: 0;
transition-delay: .3s;
transition: all .3s ease;
}
.container:focus-within .item {
opacity: 1;
}
.container .search-submit {
display: inline-block;
height: 40px;
width: 40px;
text-align: center;
line-height: 40px;
border-radius: 50%;
cursor: pointer;
}
.container .search-submit:hover {
background-color: rgba(255, 255, 255, .6);
}
.container .search-btn {
width: 100%;
border: none;
outline: none;
text-align: center;
background: inherit;
font-size: 20px;
transition: all .5s ease-in-out;
}
.container .search-btn::placeholder {
color: rgba(230, 230, 230, .9);
text-shadow: 0 0 4px #000;
transition: all .2s ease-in-out;
}
.container:hover .search-btn::placeholder,
.container:focus-within .search-btn::placeholder {
color: rgba(119, 119, 119, .9);
text-shadow: 0 0 4px #f3f3f3;
}
.background {
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
background-image: url(./bg.gif);
background-repeat: no-repeat;
background-size: cover;
background-position: center;
object-fit: cover;
transition: all .2s ease-in-out;
}
.container:focus-within ~ .background {
filter: blur(20px);
transform: scale(1.2);
}
.poem {
z-index: 1;
position: absolute;
top: 70%;
color: #ddd;
text-shadow: 0 0 2px #000;
opacity: 0;
transition: all .2s ease-in-out;
padding: 12px 32px;
border-radius: 8px;
line-height: 2;
}
.poem .author {
opacity: 0;
text-align: center;
transition: all .2s ease-in-out;
}
.container:focus-within ~ .poem {
opacity: 1;
}
.container:focus-within ~ .poem:hover {
background-color: rgba(255, 255, 255, .3);
opacity: 1;
}
.container:focus-within ~ .poem:hover .author {
opacity: 1;
}
整个前端搜索页的设计完全是仿照青柠搜索页编写的,没有创新点,能够实现搜索框输入关键字,点击搜索即可。
三、效果测试
(1)首先启动运行项目indexer,这一部分只运行一次,是不需要web服务的,所以只需查看命令行中的日志打印,索引构建好,并存放在数据库中之后,日志打印结束,此时就可以退出了。
(2)然后启动项目web的服务器,在浏览器中输入本地服务器地址,回车,可以 看到如下效果:
点击搜索框,
输入搜索词,回车
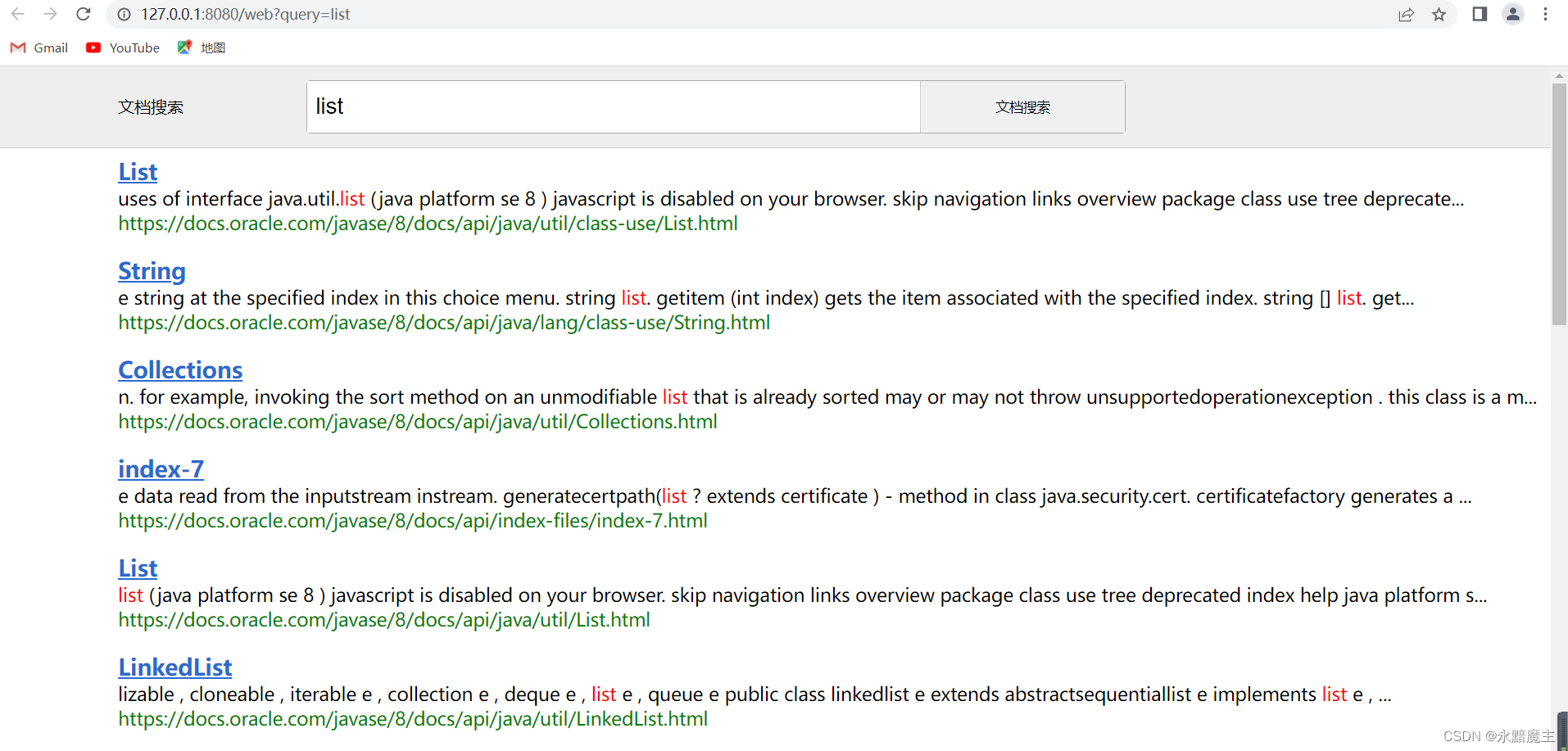
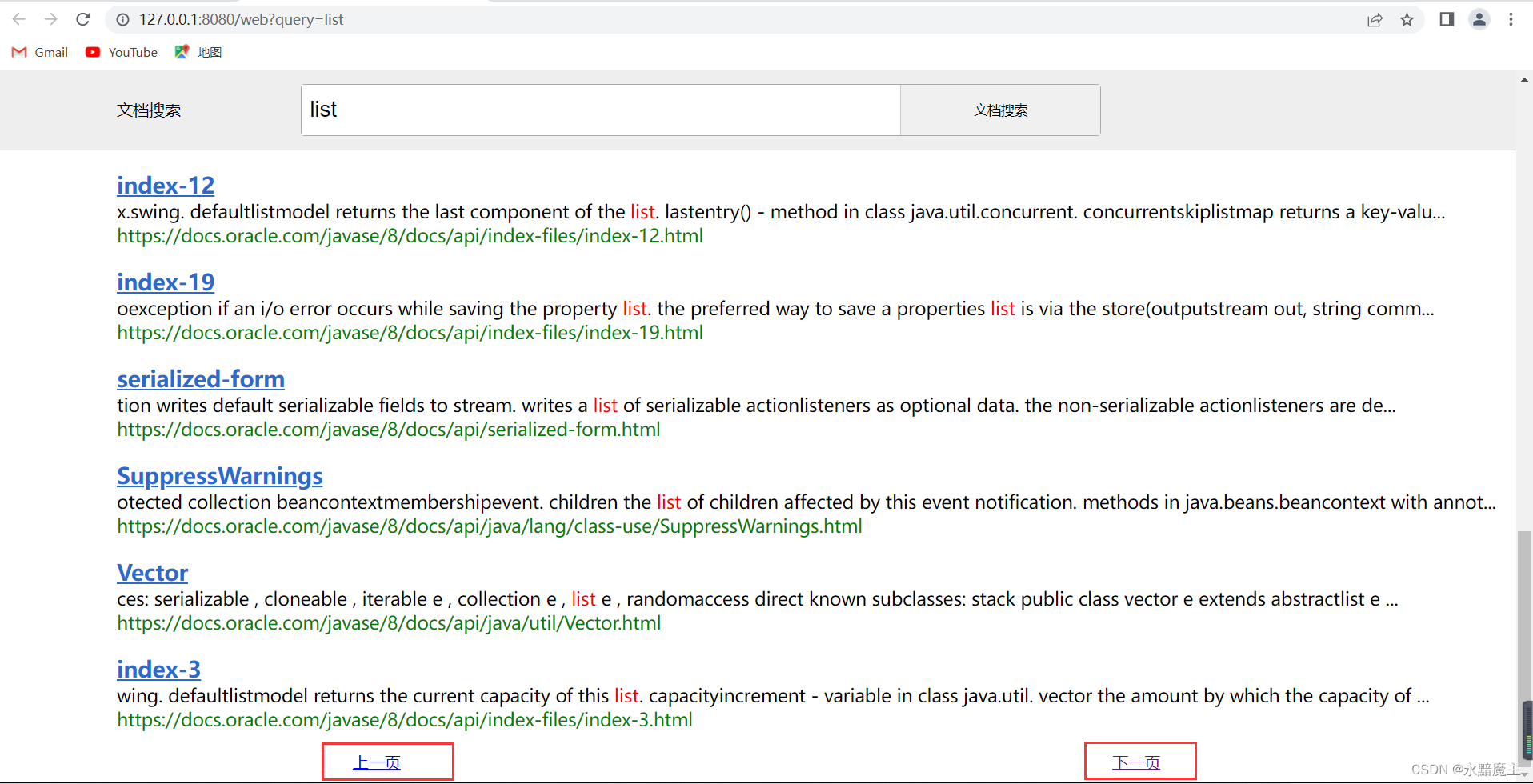
分页功能:
点击文章标题,比如,点击List,跳转到Oracle 官网的 API 文档链接:
可以看到,搜索功能目前已经实现了。
四、项目优化(改进)
(1)采用缓存操作,加快搜索速度。
(2)目前对api 文档的解析比较粗糙,会出现将代码解析至内容中的情况,所以后续还可以对解析方法进行优化。
(3)还有就是搜索词与文档的匹配度不够,尤其是在分页功能下,权重值是需要重新计算的,否则重新搜索出来的内容还是按照数据库中原来的顺序展示的。
(4)输入多个关键词,这些词在文档中的出现情况是不合理的,所以需要优化对应的算法,将对应的词高亮展示,匹配到合适的文档。
五、项目总结
(1)项目整体就分为两个部分,主要在于索引构建这块,有很多细节需要注意,特别是分词技术的使用和存放索引这一块,需要理清思路,结合业务逻辑编写代码,才不会混乱。
(2)索引构建功能编写完成之后,需要第一时间进行测试,既是测试功能的实现情况,也是测试逻辑的合理性。
(3)代码已经提交到Gitee上:项目源码














 1324
1324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









