







上一节课介绍了 Pandas 的基本用法,这一章节我们通过对 “泰坦尼克号” 幸存者进行数据分析,来进一步的学习 pandas。
titanic_train.csv
网盘链接:链接:https://pan.baidu.com/s/1hGc19QAGV6H-hDtOdz-GpQ 提取码:sgu8
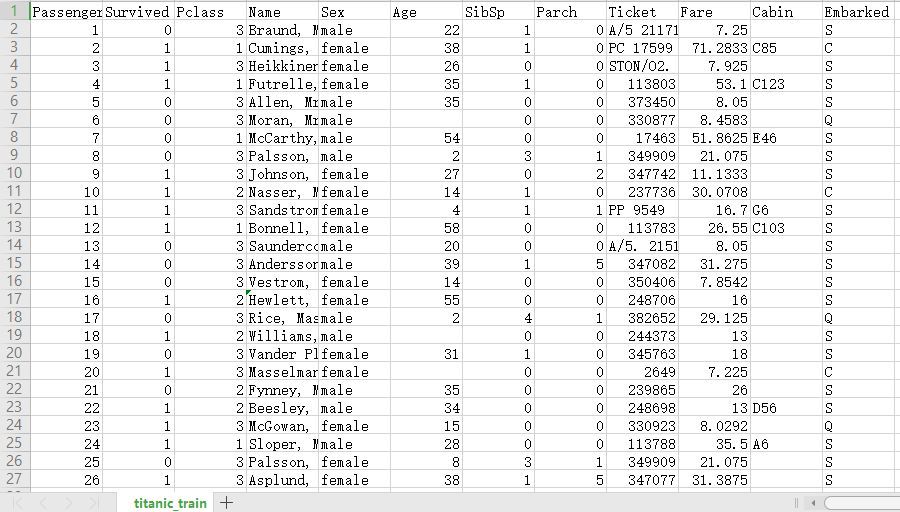
数据简介:
-
PassengerId:乘客ID -
Survived:是否获救,用1和Rescued表示获救,用0或者not saved表示没有获救 -
Pclass:乘客等级,“1”表示Upper,“2”表示Middle,“3”表示Lower -
Name:乘客姓名 -
Sex:性别 -
Age:年龄 -
SibSp:乘客在船上的配偶数量或兄弟姐妹数量) -
Parch:乘客在船上的父母或子女数量 -
Ticket:船票信息 -
Fare:票价 -
Cabin:是否住在独立的房间,“1”表示是,“0”为否 -
embarked:表示乘客上船的码头距离泰坦尼克出发码头的距离,数值越大表示距离越远
首先读入 数据
import pandas as pd
import numpy as np
titanic_survival = pd.read_csv("titanic_train.csv")
titanic_survival.head() #查看前几行数据

在 pandas 中,使用 NaN 表示数据为空,表示数据缺失
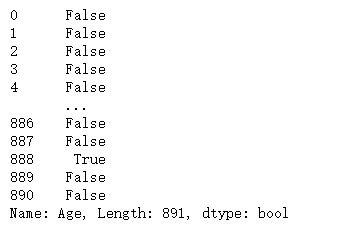
使用 .isnull()函数判断一列数据是否为空
age = titanic_survival["Age"]
age_is_null = pd.isnull(age)
print(age_is_null)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









