






报错:
HIVE跑了一个比较复杂的SQL,根据某字段插入分区表中,结果每次到 Reduce 78% 时就会降到 0%,最终运行失败。查看日志发现是这个DataXceiver类报错
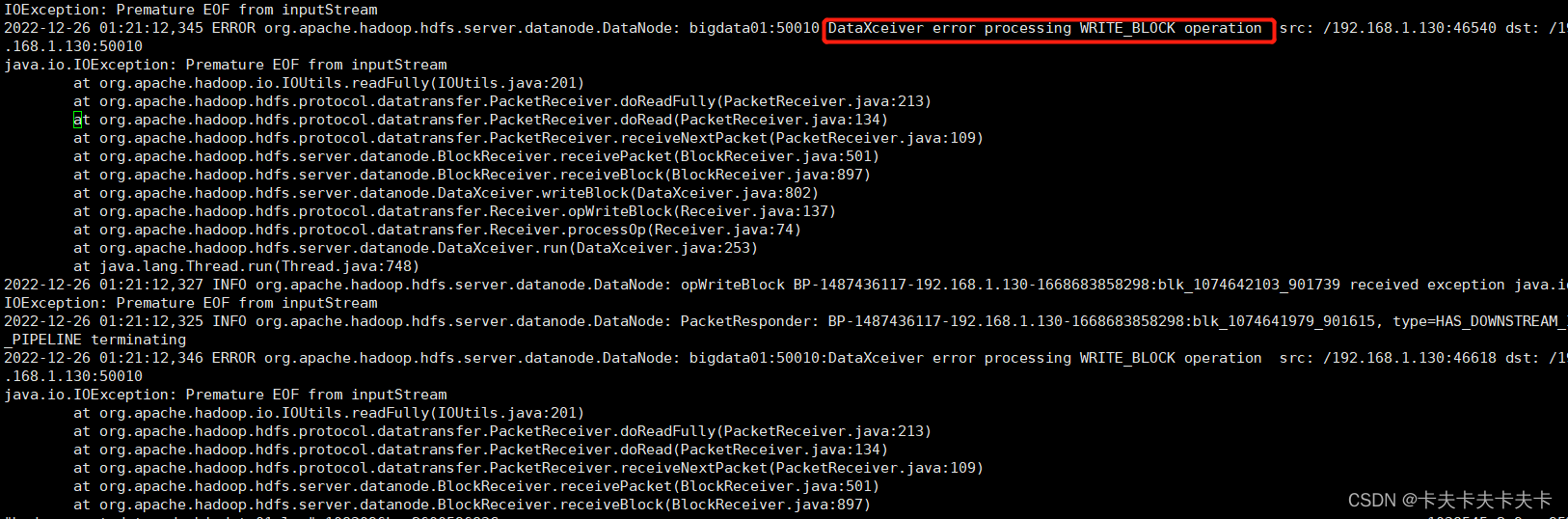
报错原因:
文件操作超租期,实际上就是data stream操作过程中文件被删掉了。之前也遇到过,通常是因为Mapred多个task操作同一个文件,一个task完成后删掉文件导致。
解决方法:
1.避免高并发读取同一文件,可减少分区数
2.调整参数,提高HDFS写入的上限。在hdfs-site.xml文件中追加以下内容(该参数默认为256)
2.x版本:
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>it
</property>1.x版本
<property>
<name>dfs.datanode.max.xcievers</name>
<value>10240</value>
</property>
拷贝到各datanode节点并重启datanode便可
运行结果















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









