










1.问题介绍
刚开始是由于启动 Hbase 时 HMaster 进程总是出现几秒种后便消失,虽然主机的 namenode 和 slave 的datanode 进程中由显示,但当查看他们的日志时仍然看到了如下错误。
(/usr/local/cluster/hadoop/logs/hadoop-hadoop2-nanenode-out.log 文件)

(/usr/local/cluster/hadoop/logs/hadoop-hadoop2-datanode-out.log)
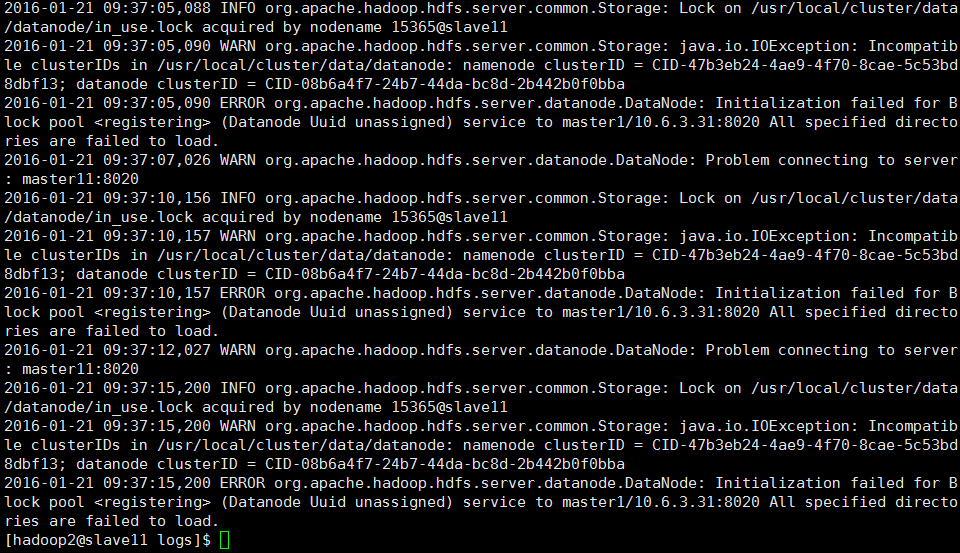
1.1 发现问题
从上图发现很有可能是由于多次 namenode format 会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,所以造成namenode节点上的namespaceID与datanode节点上的namespaceID不一致。启动失败。
2.解决问题
1.按顺序关闭集群,关闭不了的直接 kill 掉
2.删除 hdfs 配置文件所产生的目录文件,其大致有以下两种:
(以下依据自己的配置而定)
master 上
1.删除/usr/local/cluster/data/namenode 中的所有文件slave上
1.删除/usr/local/cluster/data/datanode 中的所有的文件
2./usr/local/cluster/data/journal 中的文件- 重新启动集群即可
3.注意
这种方法带来的一个副作用即是,hdfs上的所有数据丢失。如果hdfs上存放有重要数据的时候,不建议采用该方法。















 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









