







1. 概念
1.1 字符集
- 字符集是一个系统支持的所有字符的集合。字符包括各国家文字、标点符号、图形符号、数字、字母等。
- 常见的字符集有ASCII字符集、GBK字符集、Unicode字符集等。
1.2 字符编码
- 字符编码
Character Encoding: 就是一套自然语言的字符与二进制数之间的对应规则。 - 规定了哪个字符用哪个二进制数表示。(例: 二进制0110 0001 对应字符 a )
1.3 编码表
- 记录二进制与字符对应关系的表格,方便查看。
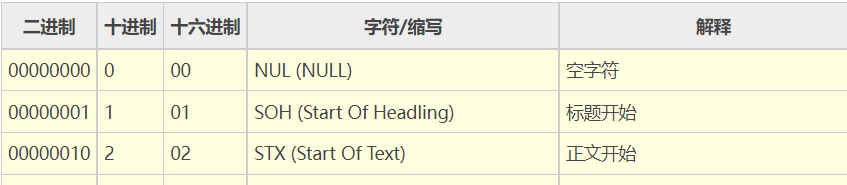
2. 产生的原因
- 计算机底层存储的是二进制(0 1),为了存储英文、数字、汉字、标点符号等字符,需要将它们转换为二进制形式。为了实现这一目的,产生了这三种概念:
- 字符集:统计了所有字符的集合。
- 字符编码:一个动作,制定对应规则。
- 编码表:代码说明表格。
3. 常见字符集

3.1 ASCII字符集
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。
- ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
3.2 ISO-8859-1字符集
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-5559-1使用单字节编码,兼容ASCII编码。
3.3 GBxxx字符集
- GB 国标(guobiao)缩写,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
3.4 Unicode字符集
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。8、16、32指的是表示一个字符最少使用的字节数。
- UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
4. Java代码验证
- 编码:将字符转为二进制代码称为编码。
- 解码:将二进制代码转为字符称为解码。
- 常见中文乱码的原因:编码和解码使用的规则不一致导致的。
4.1 Java代码验证编码、解码
package encode_decode_test;
import java.io.UnsupportedEncodingException;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
/*
代码验证编码解码
*/
public class Demo02 {
public static void main(String[] args) throws UnsupportedEncodingException {
//1.编码 使用GBK
//String类中的 getBytes() 默认使用操作系统的字符集(windows gbk)进行编码,将结果存储字节数组中。
byte[] b1 = "中".getBytes();
System.out.println("字节数组长度" + b1.length); //out: 2 gbk一个中文两个字节
System.out.println("字节数组内容" + Arrays.toString(b1));//[-42, -48]
System.out.println("===============================");
//2.编码 使用UTF-8
byte[] b2 = "中".getBytes(StandardCharsets.UTF_8);
System.out.println("字节数组长度" + b2.length); //out: 3 utf-8一个中文三个字节
System.out.println("字节数组内容" + Arrays.toString(b2));//out: [-28, -72, -83]
System.out.println("===============================");
//3.解码 GBK
byte[] d1 = {-42,-48};
String gbkStr = new String(d1, "gbk");
System.out.println(gbkStr);
System.out.println("===============================");//out: 中
//4.解码 UTF-8
byte[] d2 = {-28, -72, -83};
String utf8Str = new String(d2, StandardCharsets.UTF_8);
System.out.println(utf8Str);
System.out.println("===============================");//out: 中
}
}
4.2 [-28, -72, -83]解码为汉字"中"过程分析
- [-28, -72, -83] 根据Unicode字符集,utf-8编码规则解码为汉字“中”
- [-28, -72, -83]的二进制补码:1110 0100 1011 1000 1010 1101
- 转为整数是 14989485 ,对应的16进制E4 B8 AD
- 去Unicode字符集查找,根据utf-8 编码规则 可找到 对应Unicode “中”

4.3 用指定编码读写文件
package encode_decode_test;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
public class Test {
public static void main(String[] args) throws IOException {
//writeUTF8();
//readUTF8();
//writeGBK();
//readGBK();
}
public static void writeUTF8() throws IOException {
String path = "D:\\Project\\Java高级387\\day12\\src\\good.txt";
FileOutputStream fos = new FileOutputStream(path);
byte[] outputBuffer = "中国祝福你".getBytes(StandardCharsets.UTF_8);
fos.write(outputBuffer);
fos.close();
}
public static void readUTF8() throws IOException {
InputStream fis = Test.class.getClassLoader().getResourceAsStream("good.txt");
//读的其实是out下的文件good.txt.因为编译时会自动将src下的文件copy一份到out目录下和字节码文件放在一起,先写后读其实是一样的
byte[] inputBuffer = new byte[1024];
int len;
while ((len = fis.read(inputBuffer)) != -1) {
String s = new String(inputBuffer, 0, len, StandardCharsets.UTF_8);
System.out.println(s);
}
fis.close();
}
public static void writeGBK() throws IOException {
String path = "D:\\Project\\Java高级387\\day12\\src\\good.txt";
FileOutputStream fos = new FileOutputStream(path);
byte[] outputBuffer = "中国祝福你".getBytes("gbk");
fos.write(outputBuffer);
fos.close();
}
public static void readGBK() throws IOException {
InputStream fis = Test.class.getClassLoader().getResourceAsStream("good.txt");
byte[] inputBuffer = new byte[1024];
int len = 0;
while ((len = fis.read(inputBuffer)) != -1) {
String s = new String(inputBuffer, 0, len,"gbk");
System.out.println(s);
}
fis.close();
}
}
注
- 用字节输入流来读,即使写读的编码格式一致还是可能会产生中文乱码。
- 因为读的单位是字节,中文编码则是两个字节或三个字节或四个字节,这样有可能把一个汉字截断。
- 除非定义一个超大的字节数组,都读完后再转为字符串。
- 因此处理中文一般使用字符输入流。
注:**IDEA设置编码格式
















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









