






导师让我复现一下《TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis》的代码,下面是论文和代码的链接:
链接:https://openreview.net/pdf?id=ju_Uqw384Oq
代码:https://github.com/thuml/TimesNet
时序算法库:https://github.com/thuml/Time-Series-Library
省流不看版:每个sh脚本的第一行是export CUDA_VISIBLE_DEVICES,它的值代表了启用哪一块GPU,个人电脑就改成export CUDA_VISIBLE_DEVICES=0,服务器就根据需求改。
简简单单下个包,然后开始配置环境。接触了不少文章、代码,才知道配置环境可以这么简单:

随包下载的requirements文件里已经设好了环境,pycharm里只需执行这一语句,就能自动配置完环境,真不错(默认的torch是CPU版的,这边是我自己改的)。
einops==0.4.1
matplotlib==3.4.3
numpy==1.22.4
pandas==1.1.5
patool==1.12
reformer_pytorch==1.4.4
scikit_learn==1.2.1
scipy==1.8.0
sktime==0.4.1
sympy==1.11.1
torch==1.13.1
tqdm==4.64.0
准备运行程序的时候发现是bash和.sh,试了一下,果然cmd不能直接运行,需要安装Git,整一个Linux编译器。
附上学习Git安装的链接:Git 详细安装教程(详解 Git 安装过程的每一个步骤)_git安装_mukes的博客-CSDN博客

然后就是噩梦的开始,整了好久,运行的都是CPU版,仔细阅读代码找到关键语句,试了一下果然问题在这里(available哪儿出了问题,当然上面的GPU也有问题):
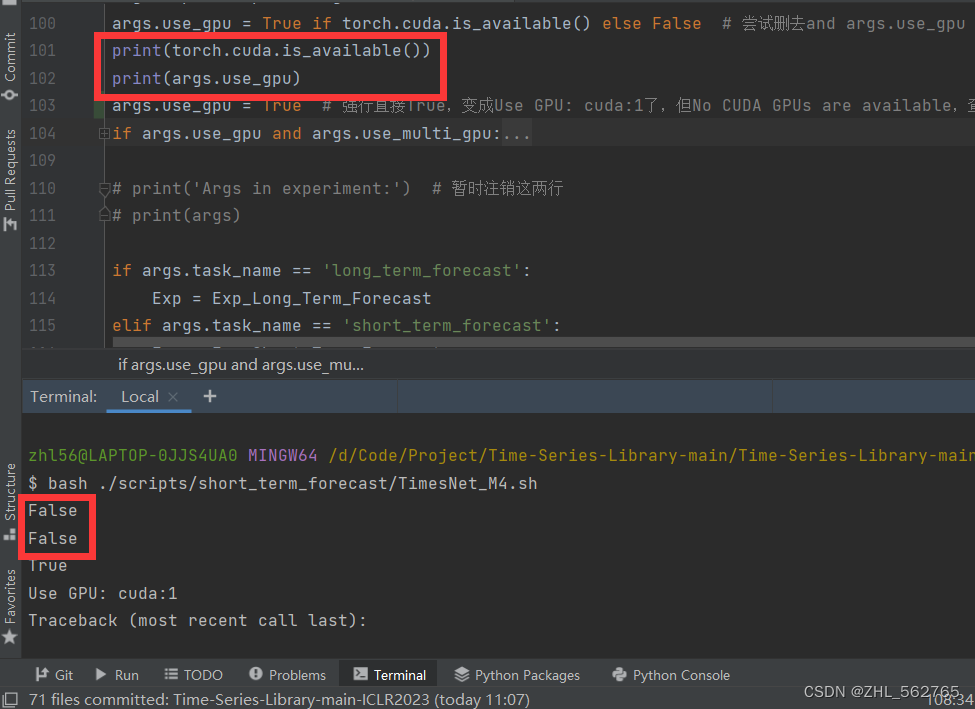
在cmd和console都试了一下,都没有问题。

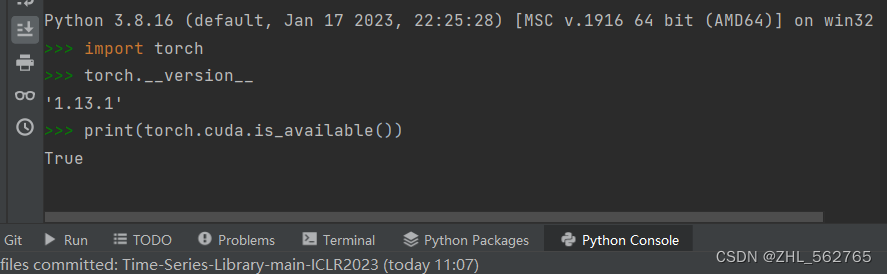
也检查了显卡和CUDA,GeForce RTX 3050最多支持11.8,目前装的是11.7,pytorch也是按照官网安装的pytorch1.13.1,cmd和console显示版本也都没问题。

所以目前头很大,到底问题出在了哪里???(后续会继续更新解决措施)
用bash运行了一下bash ./scripts/short_term_forecast/TimesNet_M4.sh,发现问题在于找不到torch,所以解决方向应该在“在git里找到torch”。
弄了好久的bash语句,突然意识到,pytorch是由Linux版的……
肥肠抱歉,Linux版的下载链接和Windows版的是一样的,而且比别的帖子里写的Linux的torch的验证方法依旧是导入->输出版本号,依旧没问题。
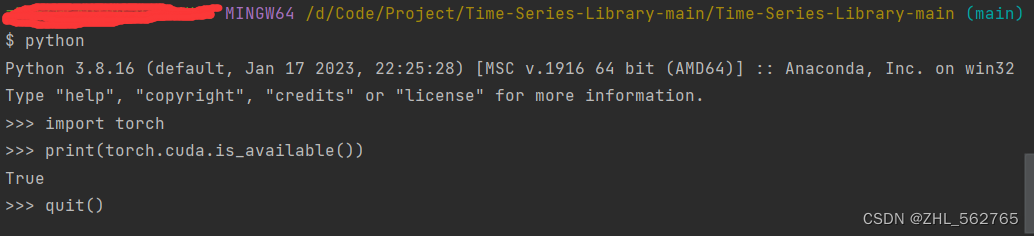

看到这篇文章还以为有救了,结果terminal明明白白地告诉我,环境就是python3.8,进入Python后,torch就是有的,嗐~Linux服务器上运行py文件,出现ImportError: No module named torch问题_m0_46429066的博客-CSDN博客
现在的问题在于,在Linux环境用bash执行.sh文件,里面的Python不会import torch,但文件里明明是有的。
过了一晚上,冷静了一些,想到会不会GitHub的提问区有类似的问题。

开幕雷击,前两天Issues还是[2],今天咋就一个不剩了?点进去看才发现,原来这边的数字只会显示Open的问题,自动隐藏Closed。
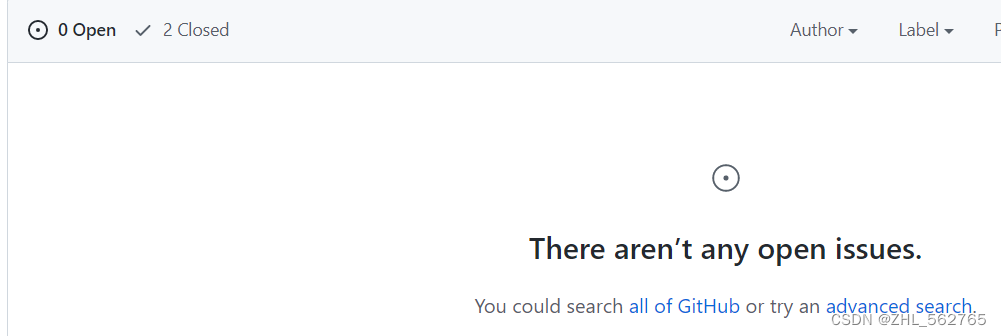
不出所料,2个Closed就是前两天的提问,带着这个好消息,又去看了看这个项目的源码。
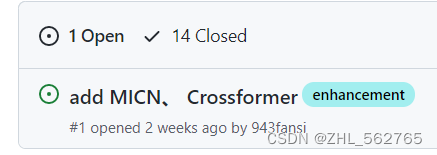
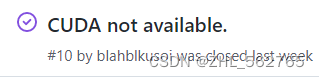
好家伙14个Closed,而且十分幸运,恰好有一个问题和我一样。

这可能是因为你使用的个人电脑只有一个可用的GPU。在这种情况下,你应该设置
export CUDA_VISIBLE_DEVICES=0
在每个脚本的第一行。

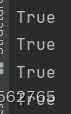
这告诉我们尽量不要在个人pc上跑GPU代码,不然就容易出现服务器根本遇不到的问题(笑)。改完以后果然没有再出现“ No CUDA GPUs are available”,清一色全是True。
再补充一点,根据这篇文章,和我自己电脑的情况,笔记本似乎一般只有一个GPU,比如我的3050,完全没有独显,台式电脑可能不同,实际的显卡数还是需要按nvidia-smi上的数据来。
调用GPU进行训练时出现 CUDA error : invalid device ordinal 核心已转储的错误 解决方案_weixin_43767344的博客-CSDN博客
不过也出现了新的问题。

CUDA错误:无效的设备序数
CUDA内核错误可能会在其他API调用中异步报告,因此下面的堆栈跟踪可能是不正确的。
对于调试,可以考虑传递CUDA_LAUNCH_BLOCKING=1。

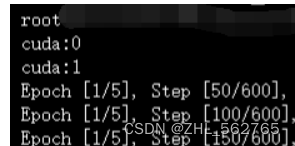
根据图里的情况,多显卡模式没有开启,又发现别人2张卡cuda是0和1,应该是在某个没注意的地方偷偷启用了第二张卡。

尴尬了,原来是我自己偷偷启用卡1,赶紧改回卡0再试试。nice,能跑了!!!
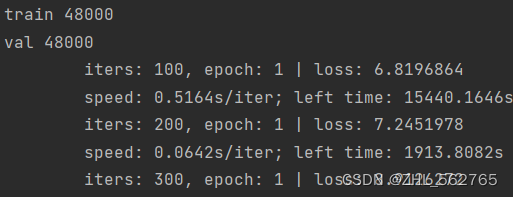
成功了, 本文至此告一段落,虽然感觉很快就会出现【奇葩问题】2.
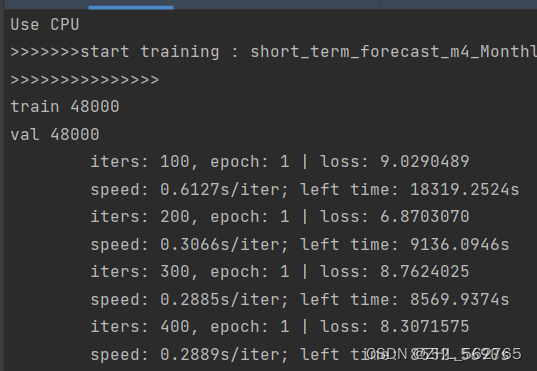
补一点:因为最初是CPU跑的,但我只注意CPU了,没记住left time,刚又整了一个CPU环境看了一下时长,简单跑了一下,稳定以后应该是8500s,CPU占有率基本拉满,预计耗时是GPU的四倍,感觉也不是不能接受。不过,半个小时一个和两个小时一个,感觉差距还是挺大的。
PS.自己电脑总是能出现很多网上查不到的问题,一样的报错,解决方法一点用都没有,终于想到自己也可以整理一个【奇葩问题】的合集,感觉还挺有趣的。















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









