







注意:group by子句一定要与分组函数结合使用,否则没有意义,
因为这是一个不成文的规定:当数据重复的时候分组才有意义,因为一个人也可以一组(没什么意义)
范例:按照部门编号分组,求出每个部门的人数,平均工资
select deptno,count(empno),avg(sal) from emp group by deptno;
范例:按照职位分组,求出每个职位的最高和最低工资
select job, max(sal), min(sal) from emp group by job;
select deptno,count(*) from emp group by deptno having count(*)>3 order by deptno;
1.分组函数可以在没有分组的时候单独使用,但是不能出现其他的查询字段:

2.如果要进行分组的话,则select子句之后,只能出现分组的字段和统计函数,其他的字段不能出现:
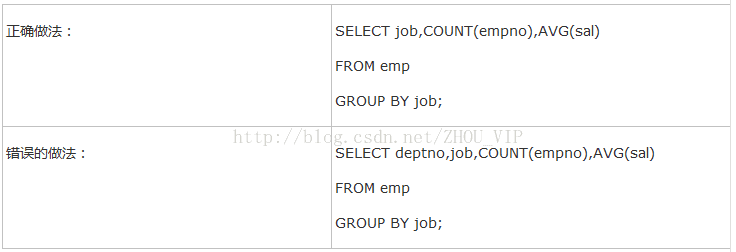
即:如果语句中有group by关键字,那么select后只能跟group by后出现的列,或者是聚合函数--max() min() count(),sum(),avg()
3.不能在WHERE子句中使用统计函数:
where:是在执行group by操作之前进行的过滤,表示从全部数据之中筛选出部分的数据,在where之中不能使用统计函数。
having:是在group by分组之后的再次过滤,可以在having子句中使用统计函数。
错误:
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,NVL(AVG(e.sal),0) myavg
FROM dept d,emp e
WHERE d.deptno=e.deptno(+) AND AVG(e.sal)>2000
GROUP BY d.deptno,d.dname,d.loc;
正确:
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno) mycount,NVL(AVG(e.sal),0) myavg
FROM dept d,emp e
WHERE d.deptno=e.deptno(+)
GROUP BY d.deptno,d.dname,d.loc
HAVING AVG(sal)>2000;
group by后可以接select后没有的列:
正确:
select sum(sal) from emp group by deptno;
select后出现的列,在group by后必须全部出现:
正确:
select job,deptno,sum(sal) from emp group by job,deptno;
错误:
select deptno,avg(sal) from emp group by deptno where deptno>10;
正确:
select deptno,avg(sal) from emp group by deptno having deptno>10;
A: select deptno,sum(sal) from emp where deptno!=30 group by deptno having sum(sal)>5000;
B: select deptno,sum(sal) from emp group by deptno having sum(sal)>5000 and deptno!=30;
性能:能在where能过滤数据不要在having里过滤,A和B都能达到同样的目的,但是A性能相对好一些,
因为A现将deptno=30的数据筛选出来,然后在将筛选的数据放入到临时表空间内进行分组;
而B将全部的数据都读到临时表空间内,然后在临时表空间进行筛选数据,
这样一来B就需要更大的临时表空间进行分组筛选,索引性能较差;
















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











