







P80 列表常用操作和练习 2024/9/17
- 列表常用操作:[文档]https://docs.python.org/zh-cn/3.11/library/stdtypes.html#list

一、常用操作一览

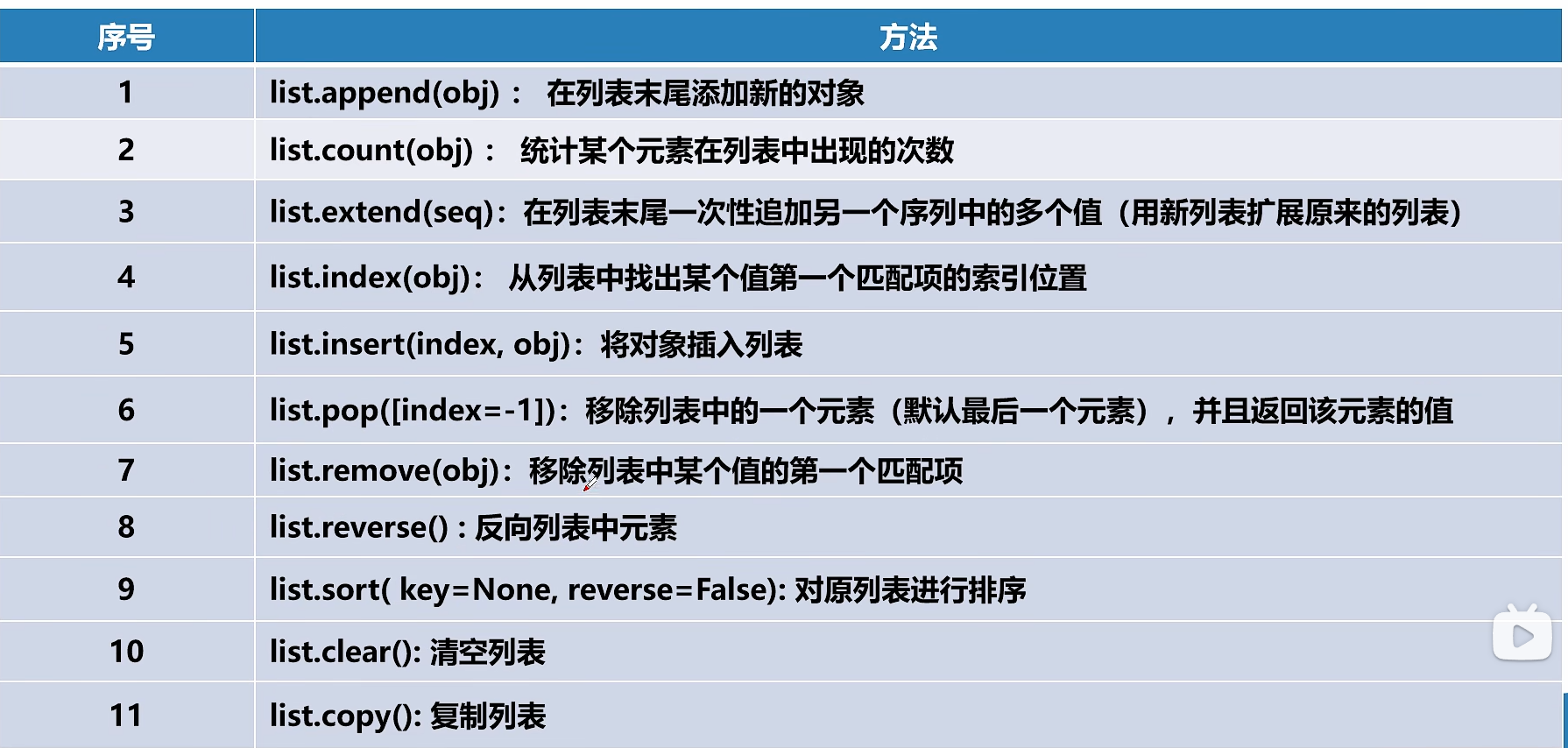
- 演示列表常用操作1:
# @Author :zjc
# @File :07_list_operations.py
# @Time :2024/9/17 21:49
# 1. 演示列表常用操作
list_a = [100, 200, 300, 400, 600]
print("list_a列表元素个数:", len(list_a)) # 5
print("list_a列表最大元素:", max(list_a)) # 600
print("list_a列表最小元素:", min(list_a)) # 100
# 2. list.append(obj) :在列表末尾添加新的对象
# 请在list_a列表后,添加900
list_a.append(900)
list_a.append(100)
print("list_a: ", list_a)
# 3. list.count(obj) :统计某个元素在列表中出现的次数
print("100出现次数是: ", list_a.count(100)) # 2
# 4. list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list_b = [1, 2, 3]
# 将list_b追加到List_a
list_a.extend(list_b)
print("list_a", list_a)
# 5. list.index(obj):从列表中找出某个值第一个匹配项的索引位置#如果找不到,会报错: ValueError
print("300第1次出现在序列的索引是:", list_a.index(300))
# 6. 翻转ist_a, list_a.reverse()
list_a.reverse()
print("list_a: ",list_a) # 逆序了
# 7. list.insert(index, obj):将对象插入列表指定的index位置
# 请实现把666插入到index为1的位置
list_a.insert(1,666)
print("list_a: ", list_a)

二、列表生成式
- 列表生成式就是"“生成列表的公式"
- 基本语法:
[列表元素的表达式 for 自定义变量 in 可迭代对象]实例说明:
[ ele * 2 for ele in range(1,5)]=得到列表==>[2,4,6,8]list1 = [ele * 2 for ele in range(1, 5)] print("list:", list1) # [2,4,6,8]思考题:
[ ele + ele for ele in "韩顺平"]=得到列表==>[?]list2 = [ele + ele for ele in "学习"] print("list2:", list2) # list2: ['学学', '习习']案例:再举一个案例,要求生成一个列表,内容为[1,4,9,16,25,36,49,64,81,100]
# 案例:再举一个案例,要求生成一个列表,内容为[1,4,9,16,25,36,49,64,81,100] # 分析: 1*1 2*2 list3 = [ele * ele for ele in range(1, 11)] print("list3:", list3)
三、课堂练习

# @Author :zjc
# @File :09_list_exercise01.py
# @Time :2024/9/18 22:50
# 1、循环从键盘输入5个成绩,保存到列表,并输出
"""
思路分析:
1. 定义一个空列表保存成绩 scores = []
2. 循环操作5次,接收用户的输入
3. 输出成绩即可
"""
scores = []
for i in range(0, 5):
score = float(input("请输入成绩:"))
scores.append(score)
print("list:", scores)
P81 元组的基本使用 2024/9/25
常用文档:https://docs.python.org/zh-cn/3.11/library/stdtypes.html#tuple
一、基本介绍
1、元组(tuple)可以存放多个不同类型数据,元组是不可变序列
- tuple不可变是指当你创建了tuple时候,它就不能改变了,也就是说它也没有 append(), insert()这样的方法,但它也有获取某个索引值的方法,但是不能重新赋值。
- 后面还有一些细节,还会讨论。
2、元组也是一种数据类型type(tuple)
二、元组的定义
- 创建一阶元组,只要把逗号分隔的不同的数据项,使用圆括号括起来即可,示例如下;
tuple_a = (100, 200, 300, 400, 500)
# 输出元组数据
print(f"元组的内容是{tuple_a}类型是{type(tuple_a)}")

三、元组的使用
- 元组使用语法
元组名[索引]
- 举例说明:
- 比如:你要使用tuple_c元组的第3个值"blue",则通过
tuple_c[2]就可以访问到 - 提示:注意索引是从0开始计算的
- 比如:你要使用tuple_c元组的第3个值"blue",则通过
tuple_c = ('red', 'green', 'blue', 'yellow', 'white', 'black')
# 读取第三个元素
print(f"第三个元素为{tuple_c[2]}")
四、元组的遍历
-
什么是元组的遍历
- 简单的说,就是将元组的每个元素依次取出,进行处理的操作,就是遍历/迭代
-
1、使用while循环遍历
tuple_color = ('red', 'green', 'blue', 'yellow', 'white', 'black')
# 从第一个元素进行遍历
index = 0
while index < len(tuple_color):
print(f"{index + 1}个元素的值{tuple_color[index]}")
index += 1
- 2、使用for循环遍历
tuple_color = ('red', 'green', 'blue', 'yellow', 'white', 'black')
for i in tuple_color:
print(f"元素是{i}")
P82 元组使用注意事项 2024/9/25
一、注意事项
1、如果我们需要一个空元组,可以通过(),或者 tuple()方式来定义。
参考文档:https://docs.python.org/zh-cn/3.11/library/stdtypes.html#tuple
# 1.如果我们需要一个空元组,可以通过(),或者 tuple()方式来定义
tuple_a = ()
tuple_b = tuple()
print(f"tuple_a内容是{tuple_a}类型是{type(tuple_a)}")
print(f"tuple_b内容是{tuple_b}类型是{type(tuple_b)}")

2、元组的元素可以有多个,而且数据类型没有限制(甚至可以嵌套元组),允许有重复元素,并且是有序的。
tuple_c = (100, "jack", 4.5, True, "jack")
print(tuple_c)
# 嵌套元组 ("天龙八部", "笑傲江湖", 300)
tuple_d = (100, "tom", ("天龙八部", "笑傲江湖", 300))
print("tuple_d=", tuple_d)

3、元组的索引/下标是从0开始的
4、元组索引必须在指定范围内使用,否则报: IndexError: tuple index out of range,比如 tuple_d=(1,2.1,‘韩顺平教育’)有效下标为0-2
# 元组索引必须在指定范围内使用,否则报: IndexError: list index out of range,
# 比如 tuple_d = (1,2.1,'韩顺平教育')有效下标为0-2
tuple_d = (1, 2.1, '韩顺平教育')
# 索引越界
print(tuple_d[3])

5、元组是不可变序列(要注意其使用特点)
# 元组的元素是不能修改,会报错TypeError: 'tuple' object does not support item assignment
tuple_e = (1, 2.1, '韩顺平教育')
tuple_e[2] = 'python' # 不能修改

6、可以修改元组内 list的内容(包括修改、增加、删除等)
# 6、可以修改元组内list的内容(包括修改、增加、删除等)
tuple_f = (1, 2.1, '韩顺平教育', ["jack", "tom", "mary"])
# 1.访问元组中list及其元素
print(tuple_f[3]) # ["jack", "tom", "mary"]
print(tuple_f[3][0]) # "jack"
# 2.修改
tuple_f[3][0] = "ZJC"
print(f"'tuple_f 内容是{tuple_f}")
# 这样是不允洗修改的,相当于将整个元祖中的列表进行了替换
# tuple_f[3] = [10, 20] 元组是不可变类型
# 3.删除
del tuple_f[3][0]
print(f"tuple_f内容是{tuple_f}") # 删除"ZJC"
# 4.增加
tuple_f[3].append("smith")
print(f"tuple_f内容是{tuple_f}") # 相当于增加了Smith

7、索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,以此类推
tuple_g = (1, 2.1, 'ZJC', ["jack", "tom", "mary"])
print(tuple_g[-2]) # ZJC
8、定义只有一个元素的元组,需要带上逗号,否则就不是元组类型
# 只有一个元素的时候一定是要带逗号的
tuple_h = (100,)
# 这里加","号了才能保证是元组
print(type(tuple_g))
tuple_i = (100)
# 后面不加",",类型就会变成int类型
print(type(tuple_i))

二、元组和列表的区别
- 老师说明:既然有了列表,python设计者为什么还提供元组这样的数据类型呢?
- 在项目中,尤其是多线程环境中,有经验的程序员会考虑使用不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误;另一方面一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。可以方便的被共享访问)。所以,如果不需要对元素进行添加、删除、修改的情况下,可以考虑使用元组
- 元组在创建时间和占用的空间上面都优于列表
- 元组能够对不需要修改的数据写保护
P83 元组的常用操作和联系 2024/9/25
一、常用操作一览

# @Author :zjc
# @File :013_tuple_operation.py
# @Time :2024/9/25 19:20
tuple_a = (100, 200, 300, 400, 600, 200)
print("tuple_a元组元素个数:", len(tuple_a)) # 6
print("tuple_a元组最大元素:", max(tuple_a)) # 600
print("tuple_a元组最小示素:",min(tuple_a)) # 100
# tuple.count(obj) :统计某个元素在列表中出现的次数
print("100出现次数是:",tuple_a.count(100)) # 1
print("200出现次数是:", tuple_a.count(200)) # 2
# tuple.index(obj):从列表中找出某个值第一个匹配项的索引位置#如果找不到,会报错:
# ValueError: x is not in tuple
print("200第1次出现在元组的索引是:",tuple_a.index(200)) # 1
# 查找元组中是否有该元素
print(300 in tuple_a) # True
print(3000 in tuple_a) # False
二、课堂练习
- 定义一个元组,(‘大话西游’,‘周星驰’,80,['周星驰,'小甜甜"]),信息为(片名,导演,票价,演员列表
-
- 查询票价对应索引
-
- 遍历所有的演员
-
- 删除’小甜甜",增加演员’牛魔王’、"猪八戒’
-
# @Author :zjc
# @File :014_tuple_exercise.py
# @Time :2024/9/25 21:34
"""
定义一个元组,('大话西游','周星驰',80,['周星驰,'小甜甜"]),信息为(片名,导演,票价,演员列表
"""
tuple_movie = ('大话西游', '周星驰', 80, ['周星驰', '小甜甜'])
# 1. 查询票价对应索引
print(f"票价对应的索引{tuple_movie.index(80)}") # 2
# 2. 遍历所有的演员
for ele in tuple_movie[3]:
print(f"演员为:{ele}")
# 3. 删除'小甜甜",增加演员'牛魔王'、"猪八戒'
del tuple_movie[3][1]
tuple_movie[3].append('牛魔王')
tuple_movie[3].append('猪八戒')
print(tuple_movie[3])
P84 字符串基本使用 2024/9/25
参考手册:https://docs.python.org/zh-cn/3.11/library/stdtypes.html#text-sequence-type-str

一、基本介绍
介绍:
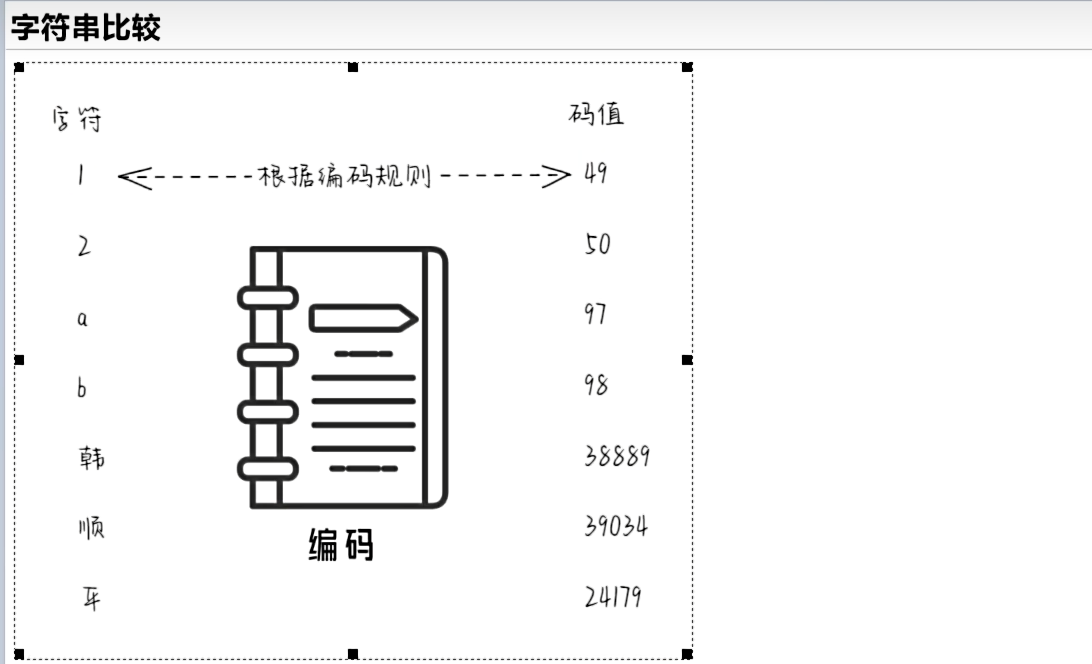
- 1、在Python中处理文本数据是使用str对象,也称为字符串。字符串是由Unicode码位构成的不可变序列。
Unicode码是一种字符编码
参考: https://zhidao.baidu.com/question/1376934773881722859.html
参考:
ord()返回单个字符对应的Unicode编码值print(ord("韩")) # 38889 print(ord("a")) # 97
- unicode编码能够表示的数量为65536个字符。
- Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
- 示意图:
- 2、字符串字面值有三种写法
- 单引号:‘允许包含有"双"引号’
- 双引号:“允许嵌入’单’引号”
- 三重引号:““三重单引号””,“”“三重双引号”“”,使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中
- 3、字符串是字符的容器,一个字符串可以存放多个字符,比如"hi-韩顺平教育”
- 示意图:

二、语法使用
-
语法:
字符串名[索引] -
举例说明:
str_a = "red-green"
比如: 要取出str_a字符串的第3个值/元素"d",则通过str_a[2]就可以访问到,
提示:注意索引是从0开始计算的,取出的单个字符,类型仍然是字符串.
str_a = "red-green"
print("str_a的第三个值/字符是:", str_a[2],"类型:",type(str_a[2]))

- 字符串遍历:
- 简单的说,就是将字符串的每个元素依次取出,进行处理的操作,就是遍历/迭代
str_b = "green-zjc"
# for循环
for ele in str_b:
print(f"{ele}")
print("-" * 30)
# while循环
index = 0
while index < len(str_b):
print(f"{str_b[index]}")
index += 1

三、注意事项和细节
-
字符串索引必须在指定范围内使用,否则报:
IndexError: string index out of range,比如str_d ="hi-韩顺平教育"有效下标为0-7,索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,以此类推 -
字符串是不可变序列,不能修改,看下面的代码
str = "hi-韩顺平教育"
print(id(str))
# 通过索引可以访问指定元素
print(str[3]) # 韩
# 不能修改元素 这是不允许的
# str[3]="李"
# 这样修改就相当于了修改了他的指向
str = "abc"
print(id(str))
- 在Python中,字符串长度没有固定的限制,取决于计算机内存大小。
P85 字符串常用操作和方法 2024/9/27
一、常用操作
- 参考文档:https://docs.python.org/zh-cn/3.11/library/stdtypes.html#string-methods

- 案例演示:
# @Author :zjc
# @File :016_str_operations.py
# @Time :2024/9/27 16:59
# 演示字符串常用操作
str_names = "jack tom mary hsp nono tom"
# 1. len(str):字符串的长度,也就是包含多少个字符
print(f"{str_names}有{len(str_names)}个字符") # 26
# 2. str.replace(old,new[, count]):返回字符串的副本。其中出现的所有子字符串 old 都将被替换为new.
# 如果给出了可选参数count,则只替换前count 次出现
"""
老韩说明:
返回字符串的副本表示原来的字符串不变,而是返回一个新的字符串,可以画一个示意图
"""
# 需求:将"jack”替换成“杰克",只替换一个;如果有两个就写2,全部替换就不写,默认全部替换
# 这里就是返回字符串的副本,赋值给另外一个变量
str_names_new = str_names.replace("jack", "杰克", 1)
print("str_names_new: ", str_names_new)
print("str_names : ", str_names)
# 3. str.split(sep=None, maxsplit=-1):
# 返回一个由字符串内单词组成的列表,使用 sep作为分隔字符串。如果给出了maxsplit,
# 则最多进行maxsplit次拆分(因此,列表最多会有 maxsplit+1个元素)。
# 如果_maxsplit未指定或为-1,则不限制拆分次数(进行所有可能的拆分)
# 需求对str_names按照" "(空格)进行分割
str_names_split = str_names.split(" ") # 类型是list[]
print(f"str_names_split 内容是{str_names_split}类型是: {type(str_names_split)}")
print(f"str_names 内容是: {str_names}")
# 4. str.count(sub):统计指定字符串在字符串中出现的次数
# 统计tom在字符串出现了几次
print("tom在字符串出现的次数:", str_names.count("tom")) # 2
# 5. str.index(sub):从字符串中找出指定字符串第一个匹配项的索引位置
print(f"tom出现的索引是:", str_names.index("tom")) # 5
# 6. str.strip([chars]):返回原字符串的副本,移除其中的前导和末尾字符
# 老韩说明:这个方法,通常可以用于除去前后的空格,或者去掉指定的某些字符
# 需求,去掉字符的前后的空格
str_names_strip = str_names.strip(" ")
print("str_names_strip: ", str_names_strip)
print(" jack ".strip(" ")) # jack
print("123jack321".strip("123")) # jack
print("123ja123ck321".strip("123")) # ja123ck
# 7. str.lower():返回原字符串小写的副本,不影响原来的字符工
# 需求:将字符串字母全部改成小写
str_names = "hspHsp"
str_names_lower = str_names.lower()
print("str_names_lower : ", str_names_lower)
print("str_names : ", str_names) # "hspHsp"
# 8. str.upper():返回原字符串大写的副本,不影响原来的字符#需求:将字符串字母全部改成大写
str_names_upper = str_names.upper()
print("str_names_upper: ", str_names_upper) # “HSPHSP”
print("str_names: ", str_names)

二、字符串比较
运算符:
>, >=, < ,<=, == , !=比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较。
比较原理:两上字符进行比较时,比较的是其
ordinal value(原始值/码值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符print(chr(97)) # a
- 字符串比较实例:
# 字符串比较-实例(str__compare.py),分析输出结果#实例
print("tom" > "hsp") # T
print("tom" > "to") # T
print("tom" > "tomcat") # F
print("tom" < "老韩") # T
print("tom" > "tom") # F
print("tom" <= "tom") # T
二、课堂练习
-
定义一个字符串,
str_names = "tom jack mary nono smith hsp
-统计一共有多少个人名-如果有"hsp”则替换成"老韩"
-如果人名是英文,则把首字母改成大写
# @Author :zjc
# @File :018_str_exercise.py
# @Time :2024/9/27 17:42
# 定义一个字符串,` str_names = "tom jack mary nono smith hsp`
str_a = "tom jack mary nono smith hsp"
# 1.统计一共有多少个人名
"""
1. 使用split方法进行分割
2. 然后统计有多少个人名即可
"""
str_a_list = str_a.split(" ")
print("一共有%d个人名" % len(str_a_list))
# 2.如果有"hsp”则替换成"zjc"
str_a_replace = str_a.replace("hsp", "zjc")
print("替换后的结果:", str_a_replace)
# 3.如果人名是英文,则把首字母改成大写
"""
"tom jack mary nono smith hsp 张三"-->全变成大写,中文不动
1. 定义字符串 str_names_upper 保存新的结果
2. 遍历str_name_list 列表,如果发现是英文名,就将其首字母变成大写
3. 拼接到 str_names_upper 即可
"""
str_names_upper = " "
for ele in str_a_list:
if ele.isalpha():
str_names_upper += ele.capitalize() + " "
# 去掉两边的空格 " "
str_names_upper = str_names_upper.strip(" ")
print(f"如果人名是英文,则把首字母改成大写 处理结果是:{str_names_upper}")
P86 切片基本使用 2024/9/27
一、基本介绍
-
什么是切片:从一个序列中,取出一个子序列,在实际开发中,程序员经常对序列进行切片操作
-
什么是序列:序列是指,内容连续、有序,可使用索引的一类数据容器

- 我们前面学习过的,列表(list)、元组(tuple)、字符串均可视为序列。
-
基本语法:
序列[起始索引]:[结束索引]:步长-
- 表示从序列中,从指定的起始索引开始,按照指定的步长,依次取出元素,到指定结束索引为止,截取到一个新的序列。
- 切片操作是前闭后开,也就是
[起始索引:结束索引),即截取的子序列,包括起始索引,但是不包括结束索引的部分。 - 步长表示,依次取出元素的间隔
- 步长为1:一个一个的取出元素
- 步长为2:每次跳过一个元素取出
- 步长为N:每次跳过N-1个元素取
-
案例说明:
# @Author :zjc
# @File :019_slice_use.py
# @Time :2024/9/27 22:16
# 对字符串进行切片
str = "hello,world"
# 需求:截取"hello"
str_slice = str[0:5:1]
print(str_slice) # hello
# 对列表进行切片
list_a = ["jack", "tom", "yoyo", "nono", "hsp"]
# 需求:截取["tom", "nono""]
list_slice = list_a[1:4:2] # ['tom', 'nono']
print(list_slice)
# 对元组进行切片
tuple_a = (100, 200, 300, 400, 500, 600)
# 需求:截取(200,300,400,500)
tuple_slice = tuple_a[1:5:1]
print(tuple_slice)

P87 切片细节和练习 2024/9/27
一、注意事项
- 切片语法:序列
[起始索引:结束索引:步长],起始索引如果不写,默认为0,结束索引如果不写,默认为截取到结尾,步长如果不写,默认为1。
# @Author :zjc
# @File :020_slice_exercise.py
# @Time :2024/9/27 22:34
str = "hello,韩顺平教育"
# 起始索引默认为0
str_slice01 = str[:5:1]
print("str_slice01->", str_slice01) # hello
# 结束索引默认截取到结尾
str_slice02 = str[1::1]
print("str_slice02->", str_slice02) # ello,韩顺平教育
str_slice03 = str[::1]
print("str_slice03->", str_slice03) # hello,韩顺平教育
# 步长默认为1
str_slice04 = str[2:5:]
print("str_slice04->", str_slice04) # llo

- 切片语法:
序列[起始索引:结束索引:步长],步长为负数,表示反向取,同时注意起始索引和结束索引也要反向标记。
str = "123456"
# 步长也是-1,表示从右到左依次的取出
str_slice05 = str[-1::-1]
print("str_slice05->", str_slice05) # 654321
str_slice06 = str[-1:-6:-1]
print("str_slice06->", str_slice06) # 65432
str_slice07 = str[-1:-6:-2]
print("str_slice07->", str_slice07) # 642

- 切片操作并不会影响原序列,而是返回了一个序列。
str = "ABCD"
str_slice07 = str[1:3:1]
print(f"str->{str} str_slice07->{str_slice07}") # str->ABCD str_slice07->BC
二、课堂练习
1、定义列表
list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]-取出前三个名字
-取出后三个名字,并且保证原来顺序(运用到以下方法)
s.reverse()就地将列表中的元素逆序。
list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]
# -取出前三个名字
list_slice01 = list_name[0:3:1]
print(list_slice01)
# -取出后三个名字,并且保证原来顺序
# list_slice02 = list_name[3:6:1]
"""
思路分析:
1. 使用反向切片
2. 步长 -1,起始索引为-1,结束索引-4
"""
list_slice02 = list_name[-1:-4:-1]
list_slice02.reverse() # 对元素进行逆序操作
print("取出后面三个名字:",list_slice02)

P88 集合基本使用 2024/9/28
- 参考文档:https://docs.python.org/zh-cn/3.11/tutorial/datastructures.html#sets
一、基本介绍
1、Python支持集合这种数据类型,集合是由不重复元素组成的无序容器。
- 不重复元素:简单的说就是集合中不会有相同的元素
- 无序:集合中元素取出的顺序,和你定义时元素顺序并不能保证一致
2、集合对象支持合集、交集、差集等数学运算
3、既然有了列表、元组这些数据容器,python设计者为什么还提供集合这样的数据类型呢?
在项目中,我们可能有这样的需求:需要记录一些数据,而这些数据必须保证是不重复的,而且数据的顺序并没有要求,就可以考虑使用集合
回顾:列表、元组的元素是可以重复,而且有序
二、集合的定义
- 创建一个集合,只要用逗号分隔的不同的数据项,并使用{括起来即可,示例如下:
set_a = {100,200,300,400,500}
basket = {'apple', 'orange', 'pear', 'banana'}
- 集合基本使用案例:
# @Author :zjc
# @File :022_set_define.py
# @Time :2024/9/28 12:22
# 集合的基本使用案例
set_a = {100, 200, 300, 400, 500}
basket = {'apple', 'orange', 'pear', 'banana'}
# 类型:<class 'set'>
print(f"set_a的内容是:{set_a}类型是:{type(set_a)}") # 注意:集合是无序的
print(f"set_a的内容是:{basket}类型是:{type(basket)}") # 注意:集合是无序的

三、注意事项和细节
- 集合是由不重复元素组成的无序容器。
# 1、集合是由不重复元素组成的无序容器
# 不重复元素组成,可以理解成会自动去重
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(f"basket: {basket}")
# 无序,也就是你定义元素的顺序和取出的顺序不能保证一致,
# 集合底层会按照自己的一套算法来存储和取数据,所以每次取出顺序是不变的
set_a = {100, 200, 300, 400, 500}
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")

- 集合不支持索引。
set_a = {100, 200, 300, 400, 500}
# 集合不支持索引
print(set_a[0])
- 既然集合不支持索引,所以对集合进行遍历不支持while,只支持for。
# 使用for对集合进行遍历print("-"* 30)
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
for ele in basket:
print(ele)

- 创建空集命只能用set(),不能用{},{}创建的是空字典,下一小节介绍:字典
# 创建空集合只能用set(),不能用仍,创建的是空字典,下一小节介绍:字典
set_b = {} # 创建空字典
set_c = set() # 创建空集合
print(f"set_b: {set_b}类型: {type(set_b)} set_c: {set_c}类型: {type(set_c)}")

P89 集合常用操作 2024/9/28
- 参考文档:https://docs.python.org/zh-cn/3.11/library/stdtypes.html#set
一、常用操作一览


- 案例演示:
# @Author :zjc
# @File :024_set_operations.py
# @Time :2024/9/28 16:30
# 定义集合
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
# 1. len(集合):集合元素个数
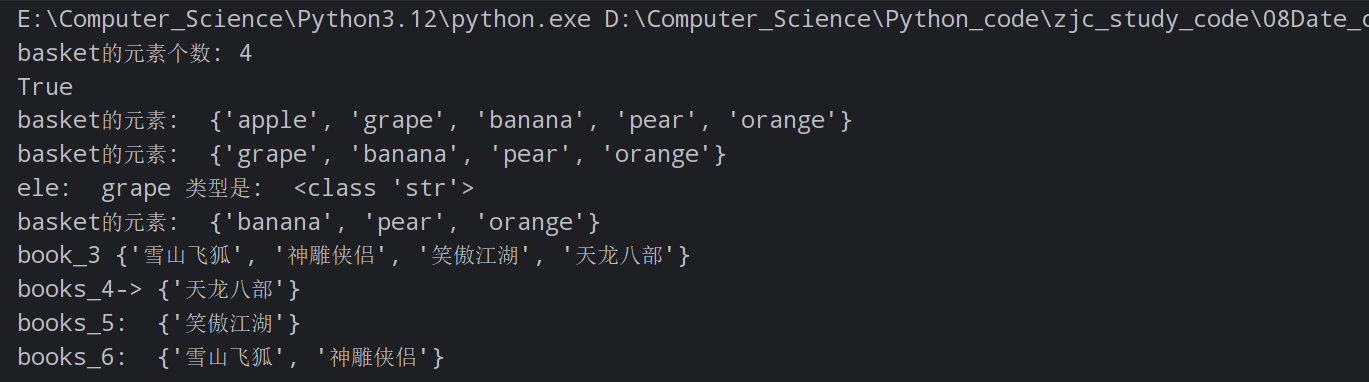
print("basket的元素个数:", len(basket)) # 4
# 2. x in s:检测×是否为s 中的成员
# 需求:判断apple是否在集合中
print("apple" in basket) # True
# 3. add(elem):将元素 elem 添加到集合中
# 需求:将grape添加到集合中
basket.add("grape")
print("basket的元素: ", basket) # {'pear', 'apple', 'banana', 'grape', 'orange'}
# 4. remove(elem) :从集合中移除元素elem。
# 如果elem不存在于集合中则会引发KeyError
# 需求:将apple从集合删除
basket.remove("apple")
# basket.remove("aaa") # KeyError
print("basket的元素: ", basket)
# 5. pop():从集合中移除并返回任意一个元素。
# 如果集合为空则会引发KeyError
# 需求:从集合中随机删除一个元素
ele = basket.pop()
print("ele: ", ele, "类型是: ", type(ele))
# 注意pop()操作会影响到原集合
print("basket的元素: ", basket)
# 6. union(*others):返回一个新集合,相当于求(并集)
# 其中包含来自原集合以及others 指定的所有集合中的元素
# 示意图说明一下:(不仅仅是简单的两集合相加起来,还有一个去重的操作)
books = {'天龙八部', '笑傲江湖'}
books_2 = {'雪山飞狐', '神雕侠侣', '天龙八部'}
# 需求:将books 和 books_2进行合集操作「即:求出在books集合或者在books_2集合的元素]
books_3 = books.union(books_2)
# books_3 = books | books_2 # 这种写法和第一种写法是等价的
# books_3 = ?
print("book_3", books_3)
# 7. intersection(*others):返回一个新集合,(交集)
# 其中包含原集合以及others指定的所有集合中共有的元素
# 需求:对 books 和 books_2求交集「即:求出既在books又在books_2集合的元素]
books_4 = books.intersection(books_2)
# books_4 = books & books_2 # 这种写法也是等价的
# books_4 = ?
print("books_4->", books_4) # {'天龙八部'}
# 8. difference(*others):返回一个新集合,(差集)
# 其中包含原集合中在others 指定的其他集合中不存在的元素
# 也就是: set - other - ...
books = {'天龙八部', '笑傲江湖'}
books_2 = {'雪山飞狐', '神雕侠侣', '天龙八部'}
# 需求:求出只存在books集合的元素
# books_5 = books - books_2 # 同样是等价的
books_5 = books.difference(books_2)
# books_5 = ?
print("books_5: ", books_5) # {'笑傲江湖'}
# 需求:求出只存在books2集合的元素
# books_6 = ?
books_6 = books_2 - books
print("books_6: ", books_6) # {'雪山飞狐', '神雕侠侣'}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











