







写在前面:
【xml的解析方式有两种,即dom方式解析和sax方式解析】sax、dom是两种对xml文档进行解析的方法(没有具体实现,只是接口),所以只有它们是无法解析xml文档的;jaxp只是api,它进一步封装了sax、dom两种接口,并且提供了DomcumentBuilderFactory/DomcumentBuilder和SAXParserFactory/SAXParser(默认使用xerces解释器)。
1. dom:(Document Object Model, 即文档对象模型)是W3C组织推荐的处理XML的一种方式。
2. sax: (Simple API for XML)不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它。
在使用DOM解析XML文档时,需要读取整个XML文档,在内存中构建代表整个DOM树的Doucment对象,从而再对XML文档进行操作。此种情况下,如果XML文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
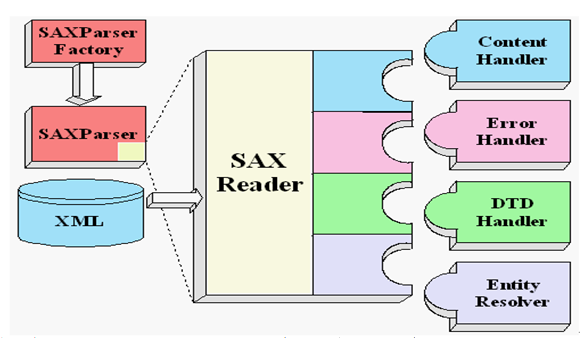
SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。SAX采用事件处理的方式解析XML文件,利用SAX解析XML文档,涉及两个部分:解析器和事件处理器。解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。解析器采用SAX方式在解析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
XML解析器:Crimson、Xerces 、Aelfred2
XML解析开发包:Jaxp(jdk中)、Jdom(开源的jar包)、dom4j(开源jar包);备注:Jaxp是Javajdk本身提供的对xml文件的解析(包括了以dom、sax两种方式的解析);Jdom和dom4j是一种通过dom方式解析xml的开源工具。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成。在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
javax.xml.parsers包中的DocumentBuilderFactory用于创建DOM模式的解析器对象, DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance方法,这个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名 name="dddd">java web就业</书名>
<作者>码农</作者>
<售价>40</售价>
</书>
<书>
<书名>C++教程</书名>
<作者>自己</作者>
<售价>50</售价>
</书>
</书架>package cn.keymobile;
import java.util.jar.Attributes;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
/**
* xml解析之:dom解析
* Jaxp中包含了以dom方式解析xml的内容,Jdom和dom4j 相当是解析xml的开源工具
* @author zhaojd
*
*/
public class XmlParse {
@Test
public void jdkDomParse() throws Exception {
//1.创建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.得到dom解析器
DocumentBuilder builder = factory.newDocumentBuilder();
//3.解析xml文档,得到代表文档的document
Document document = builder.parse("src/book.xml");
/**
* 4.使用dom方式对xml文档进行CRUD
* ①.读取<书名>C++教程</书名> 读取到 C++教程
* ②.得到文档中所有标签
* ③.得到文档中标签属性<书名 name="xxxx">java web就业</书名>
*
* ④.添加节点 【 添加节点、挂到某个节点下】
* ⑤.向文档中指定位置上添加节点 <售价>10</售价>
* ⑥.向文档节点 添加属性 <售价>10</售价>
* ⑦.删除节点
* ⑧.更新节点
*/
//①
NodeList nodeList = document.getElementsByTagName("书名");
Node node = nodeList.item(1);
System.out.println("①:" + node.getTextContent());
//②
// NodeList nodes = document.getElementsByTagName("书架");
// list(nodes.item(0));
//③
// Node node = document.getElementsByTagName("书名").item(0);
// if(node.hasAttributes()){
// NamedNodeMap attrs = node.getAttributes();
// for (int i = 0; i < attrs.getLength(); i++) {
// Node attr = attrs.item(i);
// String attrName = attr.getNodeName();
// String attrVal = attr.getNodeValue();
// System.out.println("属性名称" + attrName + "; 属性值为" + attrVal);
// }
// }
//④
//创建节点
// Element priceNode = document.createElement("售价");
// priceNode.setTextContent("59");
// document.getElementsByTagName("书").item(0).appendChild(priceNode);
// //把更新后的内容写回到文档
// Transformer transformer = TransformerFactory.newInstance().newTransformer();
// DOMSource source = new DOMSource(document);
// FileOutputStream outstream = new FileOutputStream(new File("src/outbook.xml"));
// StreamResult reslut = new StreamResult(outstream);
// transformer.transform(source, reslut);
// outstream.close();
//⑤
// Element priveNode = document.createElement("售价");
// priveNode.setTextContent("88.0元");
// //得到参考节点
// Node referNode = document.getElementsByTagName("售价").item(0);
// //得到挂仔的节点
// Node pNode = document.getElementsByTagName("书").item(0);
// pNode.insertBefore(priveNode, referNode);
//
// Transformer transformer=TransformerFactory.newInstance().newTransformer();
// DOMSource source=new DOMSource(document);
// FileOutputStream outstream =new FileOutputStream(new File("src/outbook2.xml"));
// StreamResult reslut=new StreamResult(outstream);
// transformer.transform(source, reslut);
// outstream.close();
//⑥
// Element priceNode = (Element) document.getElementsByTagName("售价").item(0);
// priceNode.setAttribute("属性名", "属性值");
// Transformer transformer=TransformerFactory.newInstance().newTransformer();
// DOMSource source=new DOMSource(document);
// FileOutputStream outstream =new FileOutputStream(new File("src/outbook3.xml"));
// StreamResult reslut=new StreamResult(outstream);
// transformer.transform(source, reslut);
// outstream.close();
// Node node = document.getElementsByTagName("售价").item(0);
// node.getParentNode().removeChild(node);
// Transformer transformer=TransformerFactory.newInstance().newTransformer();
// DOMSource source=new DOMSource(document);
// FileOutputStream outstream =new FileOutputStream(new File("src/outbook3.xml"));
// StreamResult reslut=new StreamResult(outstream);
// transformer.transform(source, reslut);
// outstream.close();
//⑦
// Element element = (Element) document.getElementsByTagName("作者").item(0);
// element.setTextContent("更新节点");
// Transformer transformer=TransformerFactory.newInstance().newTransformer();
// DOMSource source=new DOMSource(document);
// FileOutputStream outstream =new FileOutputStream(new File("src/outbook3.xml"));
// StreamResult reslut=new StreamResult(outstream);
// transformer.transform(source, reslut);
// outstream.close();
}
/**
* 遍历父节点下的子节点
*/
public void list(Node node) {
Node child;
if (node instanceof Element) {
System.out.println(node.getNodeName());
NodeList childNodes = node.getChildNodes();
for (int i = 0; i < childNodes.getLength(); i++) {
child = childNodes.item(i);
list(child);
}
}
}
@Test
public void jdkSaxParse() throws Exception {
//1.创建解析工厂
SAXParserFactory factory=SAXParserFactory.newInstance();
//2.得到解析器
SAXParser sp=factory.newSAXParser();
//3.得到读取器
XMLReader reader=sp.getXMLReader();
//4.设置内容处理器
reader.setContentHandler(new TagValueHandler());
//5.读取xml文档内容
reader.parse("src/book.xml");
}
}
class TagValueHandler extends DefaultHandler{
private String currentTag;//记住当前解析器得到的是什么标签
private int needNumber=2;//记住想获取第几个作者标签的值
private int currentNumber;//当前解析的是第几个
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
currentTag=qName;
if("作者".equals(currentTag))
currentNumber++;
}
public void characters(char[] ch, int start, int length) throws SAXException {
if("作者".equals(currentTag)&& currentNumber==needNumber){
System.out.println(new String(ch,start,length));
}
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
currentTag=null;
}
}//dom4j解析
//读第 2 本书的信息 <书名 name="xxxx">C++教程</书名>
@SuppressWarnings("unused")
private static void read() throws DocumentException {
SAXReader reader = new SAXReader();
org.dom4j.Document document = reader.read(new File("src/book.xml"));
Element root = document.getRootElement();
Element book = (Element) root.elements("书").get(1);
String value = book.element("书名").getText();
String value2 = book.element("书名").attributeValue("name");
System.out.println(value + ";" + value2);
}
//在第一本上添加一个新的售价
@SuppressWarnings("resource")
public void add() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = document.getRootElement().element("书");
book.addElement("售价").setText("111");
//XMLWriter writer=new XMLWriter(new FileWriter("src/book.xml"));
//XMLWriter writer=new XMLWriter(
new OutputStreamWriter(new FileOutputStream("src/book.xml"), "UTF-8");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("gb2312");
XMLWriter writer =
new XMLWriter(
new OutputStreamWriter(new FileOutputStream("src/book.xml"), "gb2312"),
format);
writer.write(document);
writer.close();
}
//在第一本书指定位置上添加一个新的售价,更改List集合
@SuppressWarnings({"unchecked", "rawtypes"})
public void add2() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = document.getRootElement().element("书");
List list = book.elements();//[书名,作者,售价]
Element price = DocumentHelper.createElement("售价");
price.setText("309元");
list.add(2, price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("gb2312");
XMLWriter writer =
new XMLWriter(
new OutputStreamWriter(new FileOutputStream("src/book.xml"), "gb2312"),
format);
writer.write(document);
writer.close();
}
//删除上面的节点
public void delete() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element price = document.getRootElement().element("书").element("售价");
price.getParent().remove(price);
}
//更新节点
public void update() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = (Element) document.getRootElement().elements("书").get(1);
book.element("作者").setText("张三");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("gb2312");
XMLWriter writer =
new XMLWriter(
new OutputStreamWriter(new FileOutputStream("src/book.xml"), "gb2312"),
format);
writer.write(document);
writer.close();
}
//应用xpath提取xml文档的数据,需要包jaxen-1.1-beta-6.jar
public void xpath() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
String value = document.selectSingleNode("//作者").getText();//第一个值
System.out.println(value);
}
}收藏阅读:
http://qingkangxu.iteye.com/blog/1838405
http://blog.csdn.net/smcwwh/article/details/7183869















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









