






前言
第六届中国模式识别与计算机视觉大会(The 6th Chinese Conference on Pattern Recognition and
Computer Vision, PRCV
2023)已于近期在厦门成功举办。通过参加本次会议,使我有机会接触到许多来自国内外的模式识别和计算机视觉领域的研究者和工业界同行,了解了目前我国模式识别与计算机视觉领域的最新理论和技术成果。其中对我触动最大的就属上海合合信息的郭丰俊博士讲解的“
** 文档图像前沿技术探索—多模态及图像安全** ”专题部分了。

合合信息
在讲解 ** 多模态及图像安全** 之前,我们先对合合信息科技做一个简单的介绍吧。
上海合合信息科技股份有限公司致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。

它开发的深受全球用户喜爱的C端产品 ** 全球累计用户下载超23亿,累计月活约 1.3亿。** 其中 ** 名片全能王** 和 **
扫描全能王免费版** 在App Store排行榜上名列前茅。
文档图像分析识别与理解
技术难题
大会上,郭博士对目前文档图像分析识别与理解的技术难题做了阐述,主要体现在以下几个方面:
- 当文档图像质量退化时,会导致文档图像变得模糊不清。这种质量问题与文档图像扫描技术密切相关;
- 根据以下图片案例来看,文字的排布版面非常的复杂,这就给版面分析、文字检测带来了巨大的挑战;
- 在文字识别领域,由于书写的潦草、包括识别的种类非常的多,除了文字、公式还有一些特殊的符号;
探索
基于以上的问题和难题,合合信息将文档图像分析识别与理解的研究主题分成了以下六个模块:

- 文档图像分析与预处理:主要解决的是文档图像的质量问题,比如一张人眼都无法看清的文档图像在经过切边增强、去摩尔纹、弯曲矫正、图片压缩、PS检测等技术的处理之后变成非常清晰的质量非常高的图像。
- 文档解析与识别:经过文档图像分析与预处理之后的文档图像会接着来到文档解析与识别模块。我们通过文字识别、表格识别、电子档解析等技术获取到文字信息。
- 版面分析与还原:我们会把上个步骤拿到的文字信息进行处理,使用元素检测、元素识别、版面还原等技术来识别文档的标题、段落、图像等元素,并还原文档的原始版面结构,以便后续的信息抽取和理解。
- 文档信息抽取与理解:通过计算机技术,从文档中自动提取出有用信息并进行理解、分类和归纳。文档信息抽取与理解可以帮助人们更加有效地管理和利用大量文档数据,提高工作效率和决策质量。它在数字化档案管理、企业知识管理、搜索引擎、自动化客服等领域具有广泛的应用前景。
- AI安全:在文档图像分析识别与理解过程中,通过篡改分类、篡改检测、合成检测、AI生成检测等技术来保证用户的数据隐私和文档图像安全性。
- 知识化&存储检索和管理:将信息和知识进行有效的组织、存储、检索和管理,在大量的数据和信息中提取有用的知识,并使其易于访问和利用,对于提高工作效率、决策质量和创新能力具有重要意义。
多模态模型进展与探索
去年随着ChatGPT的横空出世,大家对多模态模型是否能快速融入到自己的工作场景产生了浓厚的兴趣。我们接下来讲一下多模态大模型对文档图像处理方面将会产生怎样的影响。
文档图像多模态属性
多模态大模型是指能够同时处理多种类型数据(例如图像、文本、语音等)的强大神经网络模型。它将多个模态的输入数据整合在一起,并通过共享的模型结构进行联合训练和推理。
多模态大模型的核心思想是将不同模态的数据进行融合和交互,以实现更全面、准确的任务处理。例如,在图像与文档生成任务中,模型可以同时接受图像和文档输入,并根据两者之间的关联生成相应的输出。由此可见
** 文档图像具有天然的多模态属性** 。
多模态大模型在文档图像处理中的应用
- GPT-4:多模态大模型如GPT-4已经取得了显著的进展,可以同时处理文本和图像数据,从而提高了文档图像识别与理解的性能。这使得处理多种类型的信息更加容易,包括文字、图像和其它媒体。
- Google Bard:Google Bard是另一个多模态大模型,同样在文档图像领域表现出色。这种竞争推动了领域内的技术进步,有望带来更多创新。
- 文档图像大模型:文档图像处理领域出现了一系列专有大模型,如LayoutLM系列、LiLT INTSIG、UDOP和Donut。这些模型使用了多模态Transformer编码器,可以应用于不同的文档图像处理任务,包括文本、表格、版面结构和多语言支持。
- 多模态大模型的局限性:尽管多模态大模型在处理文本和图像方面表现出色,但它们仍然存在一些局限性,特别是对于细粒度文本的处理表现较差。这为未来的研究提供了挑战和机会,以进一步提高这些模型的性能。
LLM时代文档图像处理技术趋势
随着大模型领域技术的突飞猛进,领域专家对LLM时代文档图像处理技术的趋势做出了预测。普遍认为输入端应该是多模态的方法,架构应该是Transformer
Encoder / Decoder的架构,而数据层面应该是海量/高质量的数据。只有具备了以上三个条件,才能得到一个比较好的文档图像大模型的效果。
ChatGPT4出来以后,之前的做OCR的方法还适用嘛?答案是肯定的,OCR仍然是多模态大模型中的一项重要技术,因为要想训练一个很好的大模型,都依赖于高质量的大数据,而OCR本身就是一个提供高质量数据的工具。OCR可以支持大模型高效的录入数据,而且支持不同格式的信息提取。
文档图像处理知名系统

通过对比实验分析,当前大模型的系统测评的系统性能还有待提高,跟监督学习的结果相比还是差点意思。究其原因,可能跟视觉编码器的分辨率和训练数据限制有关。

图像安全
随着生成式人工智能的快速发展,现在在图像领域,越来越多的系统能够生成图像质量非常高的生成式图像,图像的真伪、图像的安全问题变得越来越重要。AI换脸、证照篡改等会对银行、保险、金融行业的认证体系带来冲击:



中国信通院携手合合信息开启《文档图像篡改检测标准》制定工作,为文档图像内容安全提供可靠保障,助力新时代AI安全体系建立。主要体现在图像篡改检测、AIGC判别两个方面。
篡改种类
图像篡改分为四种类型:复制移动、拼接、擦除、重打印。

系统架构
解决的方法主要是通过以下分割模型来解决的,Backbone使用ConvNeXt作为编码器,使用LightHam和EANet两个网络并行作为解码器来达到更好的判断效果。

技术挑战
对于文档图像和证件照篡改的主要技术挑战主要体现在它的泛化性。通过大量数据的构建和整个训练策略的不断调优来达到泛化问题的改善。

合合信息在今年获得ICDAR2023 文档图像篡改检测的冠军。

生成式AI ** 鉴别**
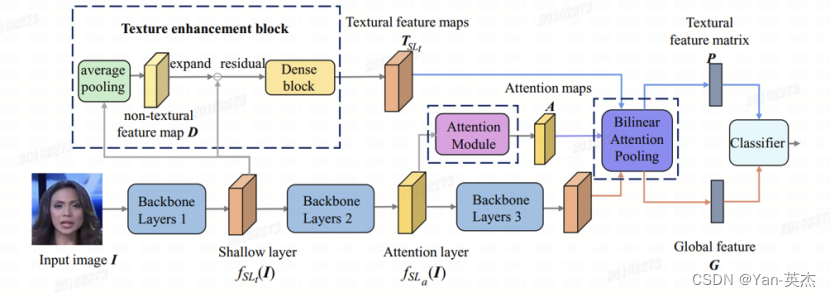
以人脸场景为例,通过多个空间注意力头来关注空间特征,并使用纹理增强模块放大浅层特征中的细微伪影,增强模型对真实人脸和伪造人脸的感知与判断准确度。
鉴别结果展示

展望
合合信息的研究成果为各行业提供了实用的解决方案。智能图像处理作为其中的一个重要领域,合合信息开发出了高效、准确的图像处理算法和工具,为各种应用场景提供了优化的解决方案。这些成果广泛应用于金融、制造业、医疗等领域,极大地提升了效率和精度,并为各行业的发展带来了实际效益。希望合合信息能够持续进行深入的研究探索和技术创新,不断取得更多突破,推动人工智能技术的应用和智能产业的发展。
最后
从时代发展的角度看,网络安全的知识是学不完的,而且以后要学的会更多,同学们要摆正心态,既然选择入门网络安全,就不能仅仅只是入门程度而已,能力越强机会才越多。
因为入门学习阶段知识点比较杂,所以我讲得比较笼统,大家如果有不懂的地方可以找我咨询,我保证知无不言言无不尽,需要相关资料也可以找我要,我的网盘里一大堆资料都在吃灰呢。
干货主要有:
①1000+CTF历届题库(主流和经典的应该都有了)
②CTF技术文档(最全中文版)
③项目源码(四五十个有趣且经典的练手项目及源码)
④ CTF大赛、web安全、渗透测试方面的视频(适合小白学习)
⑤ 网络安全学习路线图(告别不入流的学习)
⑥ CTF/渗透测试工具镜像文件大全
⑦ 2023密码学/隐身术/PWN技术手册大全
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!
扫码领取
















 46
46











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









