






评测目的
评估模型性能:通过对大语言模型进行评测,可以了解模型的性能和表现,从而确定其在实际应用中的价值。
优化模型:通过评测,可以发现模型存在的问题和不足,进一步优化和改进模型,提高其性能和表现。
比较不同模型:通过评测不同的大语言模型,可以比较它们的性能和表现,从而选择最适合特定任务的模型。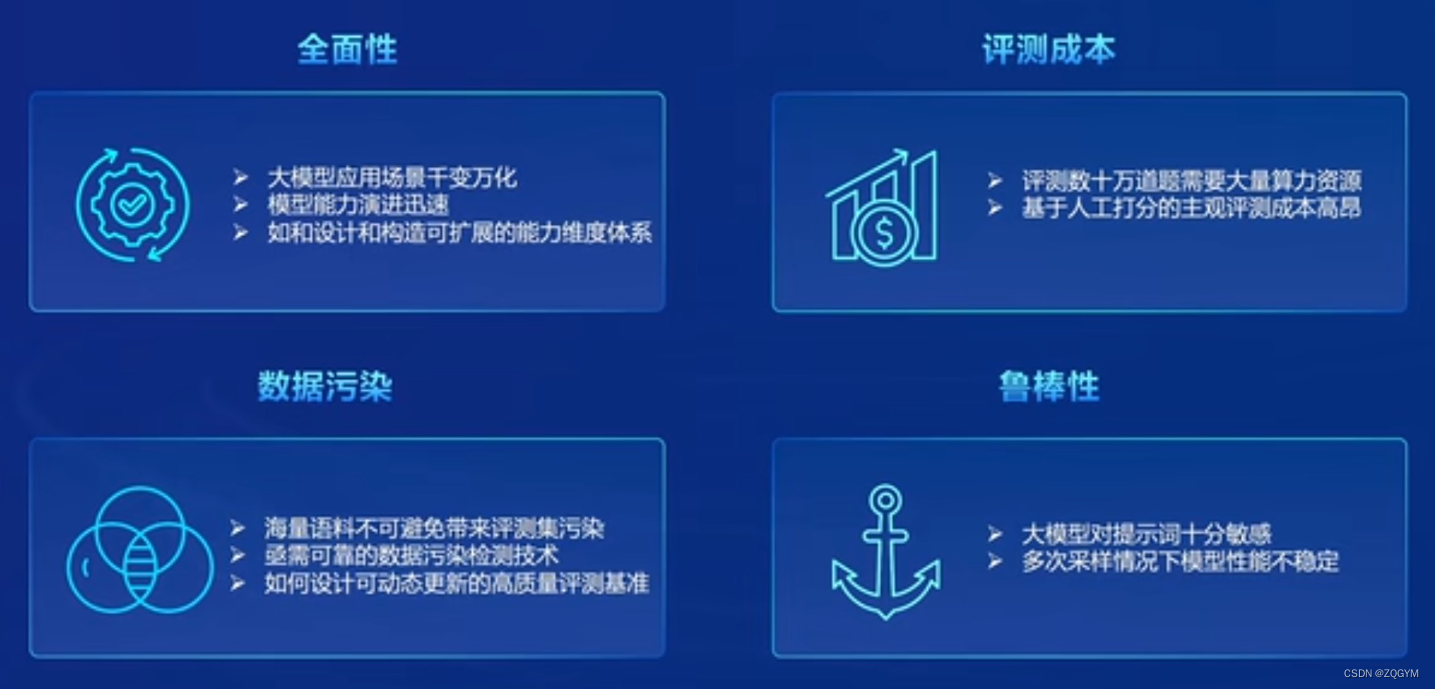
评测要素
评估指标:需要选择合适的评估指标,以全面、客观地反映模型的性能和表现。常用的评估指标包括准确率、召回率、F1值、BLEU分数等。
数据集:需要选择具有代表性的数据集,以测试模型在不同场景下的性能和表现。
实验设置:需要设置合理的实验参数和条件,以确保评测结果的准确性和可靠性。
OpenCompass
OpenCompass是一个大模型评测平台,用于对自然语言处理模型的性能、评估指标、评测方法和模型种类进行全面评估。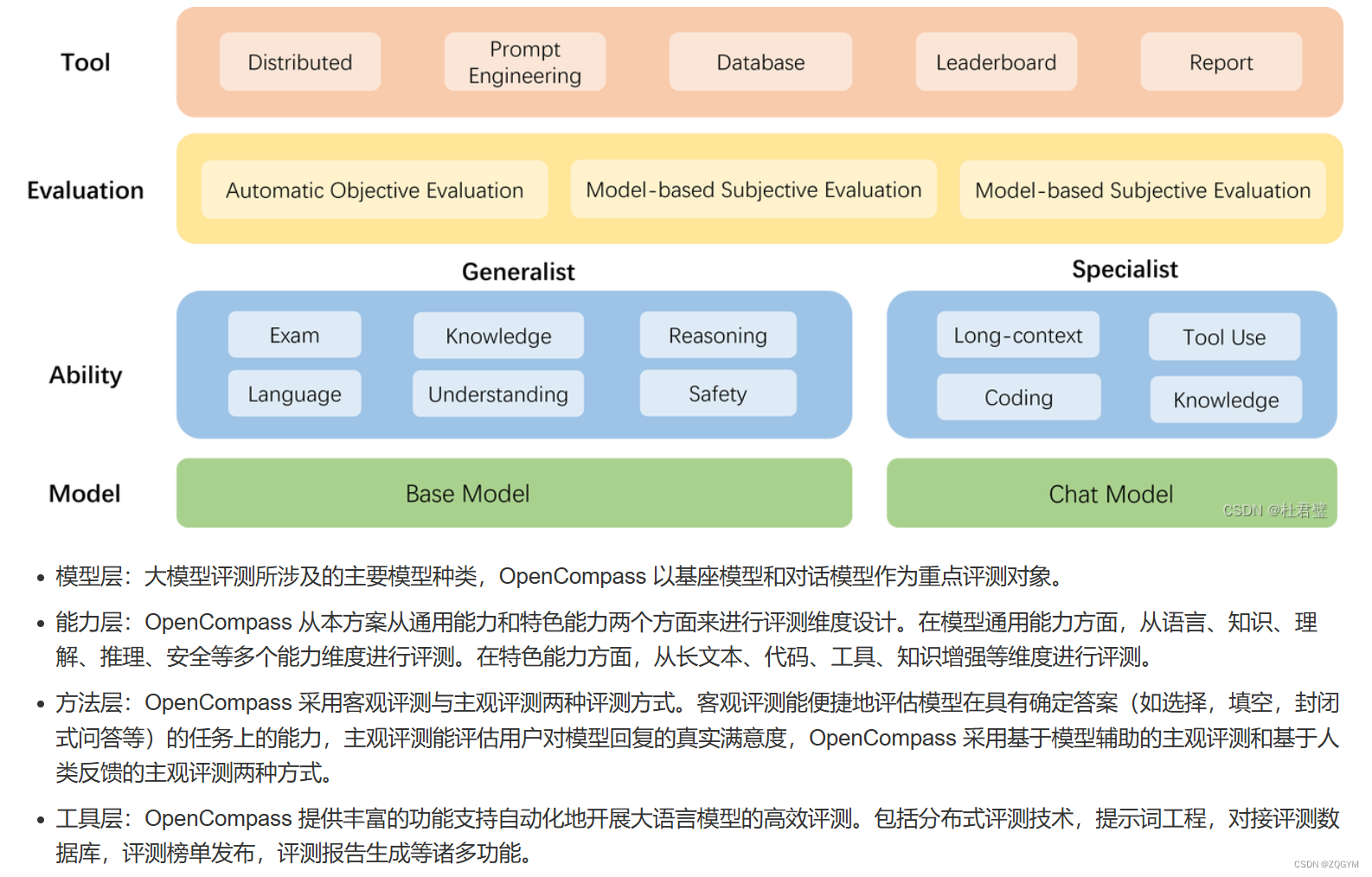
core功能升级

工具+
评测流水线
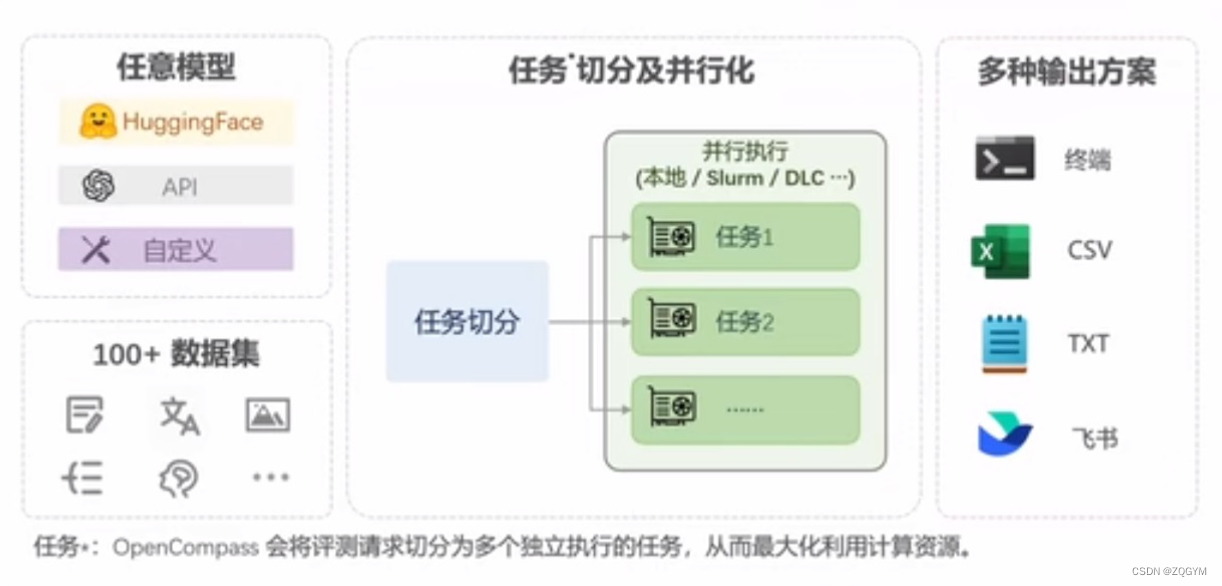
行业共建

作业过程
安装环境
启动测评
python run.py
--datasets ceval_gen \
--hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug

















 2180
2180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









