







随机在一个表里选择三个数据:
创建表语句:
CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10002 DEFAULT CHARSET=utf8
插入数据的存储过程:
CREATE DEFINER=`zhuruilin_dev`@`%` PROCEDURE `dev`.`test1`()
begin declare i int;
set i = 0;
while(i <= 10000)do
insert into words(word)
values(concat(char(97+(i div 1000)),char(97+(i%1000 div 100))));
set i = i + 1;
end while;
end
考虑的sql:
select word from words order by rand() limit 3;
分析一下这个sql的执行情况

Extra列的值由Using temporary表示使用了临时表, Using filesort 就是 需要排序。
合起来就是需要使用临时表,并且在临时表上做了排序操作。
之前有说过select的字段中如果有不是索引字段的,就会有一个回表的操作,根据主键id去查询这一行的数据,如果表中没有主键,那就InnoDB就会给每一行的数据生成一个rowid,用来表明每一行数据的位置,类似索引作用。
这条语句的大概执行流程如下:
- 创建一个临时表,表的引擎是memory引擎,表里有两个字段,一个是double类型,存储rand()函数生成的0到1的数字也就是用来排序的(先称为R字段),另一个字段就是word字段(先称为W字段)。这个临时表是没有索引的。
- 从words表中,按主键的顺序将表中的数据的word一行一行的读入到临时表中,对应的就是W字段,并且同时rand()函数生成的0到1的值放入表中,对应的就是R字段。这一步需要全表扫描,扫描行数为10000.
- 临时表的数据已经弄完了,接下来准备排序
- 初始化sort_buffer,将临时表中的排序字段也就是R字段放进去,因为没有主键,所以会将每一行对应的rowid页放入进去,这个过程需要对临时表做全表扫描,扫描行数增加10000,变为20000.
- 排完序之后,取前三条的rowid,再去临时表中取到word值,进行返回。扫描了三行数据,扫描行数变为20003。
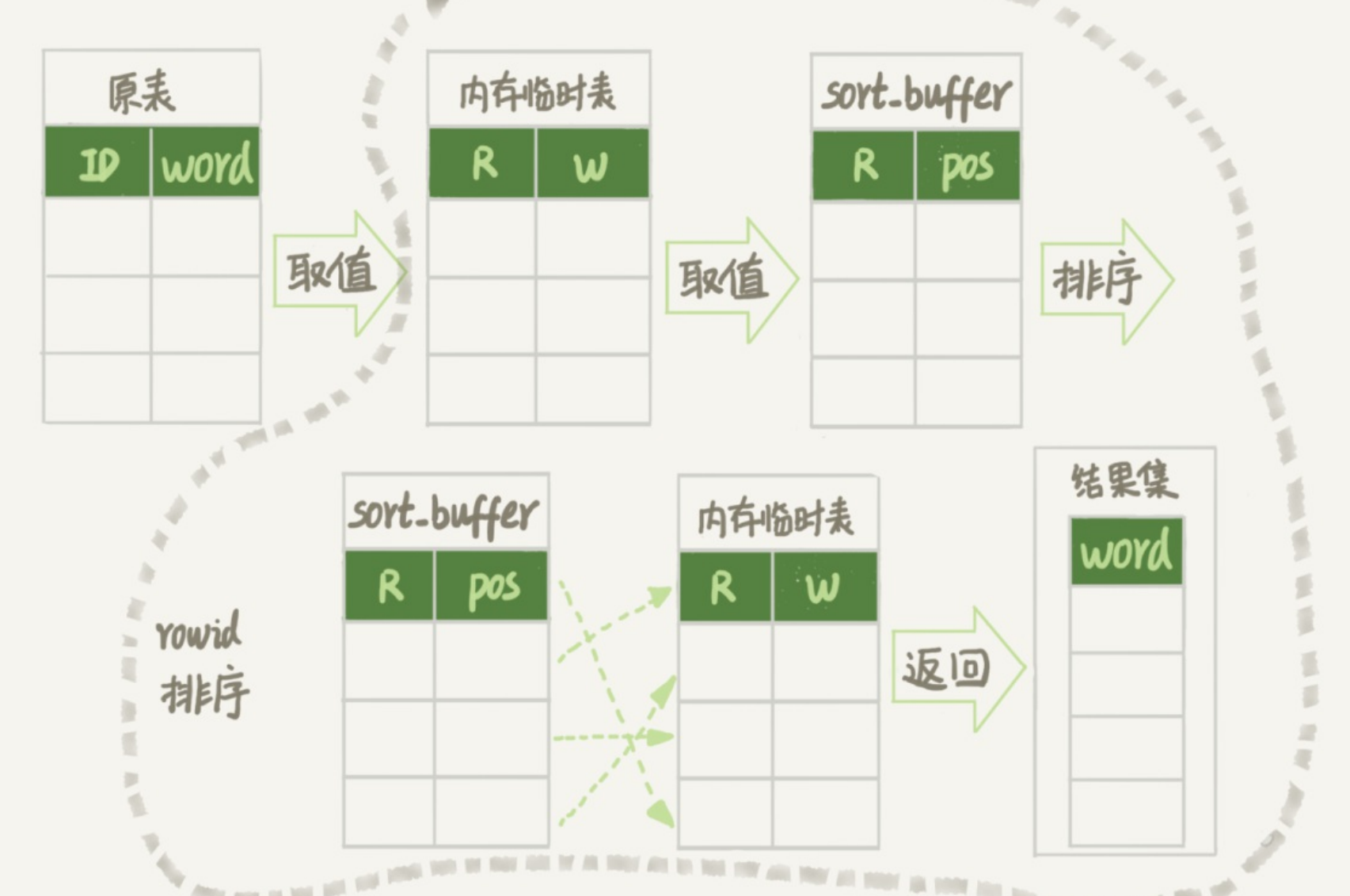
order by rand()函数使用了内存临时表,内存临时表排序的时候使用了rowid排序方法。
磁盘临时表
tmp_table_size这个配置限制了内存临时表的大小,默认值是16M。如果临时表大 小超过了tmp_table_size,那么内存临时表就会转成磁盘临时表。
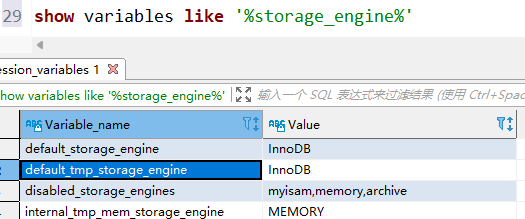
磁盘临时表使用的引擎默认是InnoDB,是由参数default_tmp_storage_engine控制的。
如果将max_length_for_sort_data参数设置为16,tmp_table_size设置成1024。
max_length_for_sort_data小于word字段定义的64,所以会使用rowid算法排序,
R字段存放的随机值就8个字节,rowid是6个字节,数据总行数是10000,这样算出来就有140000字节, 超过了sort_buffer_size 定义的 32768字节了。但是,number_of_tmp_files的值会是0,也就是不会用到临时文件(之前有写过超过sort_buffer_size的限制之后会采取归并排序,创建多个临时文件来归并排序再合并的方式)。
没有创建临时磁盘文件的原因是因为没有使用归并排序方法,而是使用的是优先队列排序算法。因为是要求随机取三个单词,所以order by rand()中可以 生成随机数最小的三个也行。如果使用归并排序,那就是对10000条数据都排序了,算是浪费了资源。
所以可以通过比较大小的方式来取得最小的三个。
- 先取前三个值组成一个堆,
- 取得第四个值cur,和这个堆里的最大值max进行比较,如果 cur < max, 就将 max的值换成cur,如果cur > max,就跳过
- 重复上面的步骤,直到10000条数据比较完,就可以取得最小的三个值。
这样操作实际用到的内存会很小。
随机排序方法
先把问题简化一下,如果只随机选择1个word值,可以怎么做呢?
- 取这个表的主键id的最大小max和最小值min
- 用随机函数在min和max中生成一个数 cur = min+rand()*(max-min)
- 取id = cur +1 的数据
虽然words表是自增的,但是如果实际的表会有删除操作,就会导致数据不均匀。也就是可能表中数据id的分布值变为1,100,200,500,60000。
这样就导致生成的cur是无效的。
再修改下。
- 用count(1)来查询一下行数 rows
- 取得 target = floor(rows * rand()) floor是为了取整
- 再用 limit target,1 取的随机一行















 2772
2772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









