







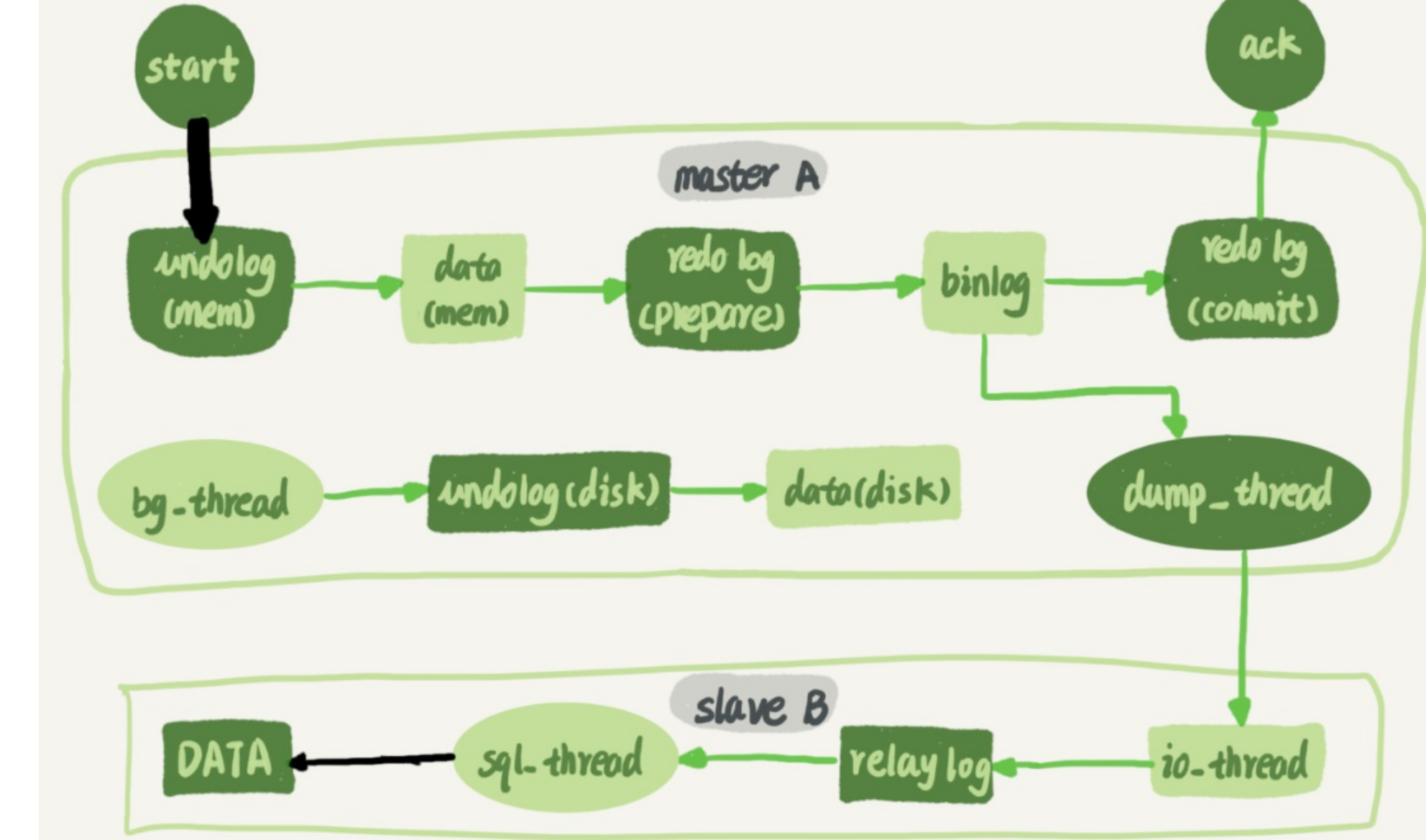
主备的并行复制能力,主要体现在两个黑箭头上,第一个是客户端写入到数据库;第二个是备库执行binlog日志更新或写入数据。如果备库使用的是单线程的话,就会导致备库应用日志不够快,造成主备延迟。
在官方的5.6版本之前,MYSQL只支持单行复制,所以在主库并发高,TPS高的情况下就会出现严重的主备延迟。从单行复制到多线程复制,中间经历了很多版本,所有的多行复制都是为了将sql_thread拆分为了多线程去跑任务。
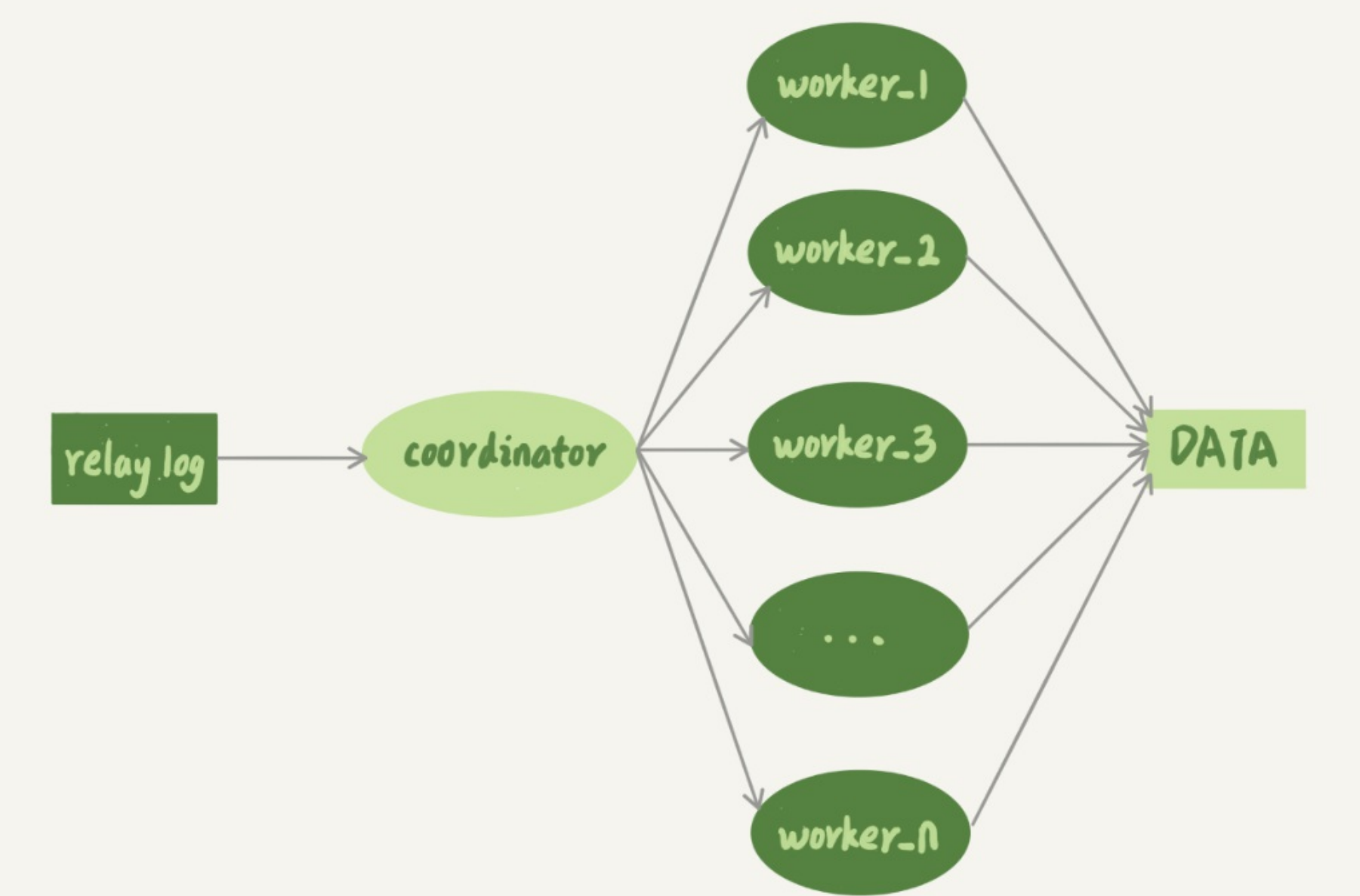
上图中的coordinator就是sql_thread,只不过coordinator不负责直接更新数据,而是负责读取relay log和分发事务,真正进行更新数据的是这些wroker线程。线程的个数是由参数slave_parallel_workers决定的。
思考一个问题:能否将所有的事务按照先后顺序分发给worker?
其实是不行的。如果事务A是将字段B=1的数据行的字段A更新为2;事务B是将字段A=2和字段B=1的数据行字段C更新为3;在主库中执行事先务A,后事务B的顺序执行的;到了备库之后如果事务A分给了worker1,事务B分给了worker2,因为CPU调度策略是随机的,所以可能就worker2先执行,后执行worker1,这样就会出现数据不一致的情况。所以如果同一行数据的事务被分给了不同worker,就可能出现主备不一致的情况。
第二个问题:同一个事务内的多个更新语句可以分给多个worker么?
也是不行的。因为这样做的话,一个事务的更新语句分给了多个worker,而worker执行的话会有先后顺序,就会导致在某个瞬间看到的数据是和主库不一致的。而且在主库中一个事务内的语句是一起执行的,在备库也应该一起执行才对。
所以coordinator在分发事务的时候需要满足两个基本要求:
- 更新同一行数据的两个事务,只能分给一个worker。
- 同一个事务只能分给一个worker,不能被拆分开。
下面先写两个作者写的并行策略:
按表分发策略
按表分发策略的基本思路就是如果两个事务操作的不是同一个表,那就可以执行。
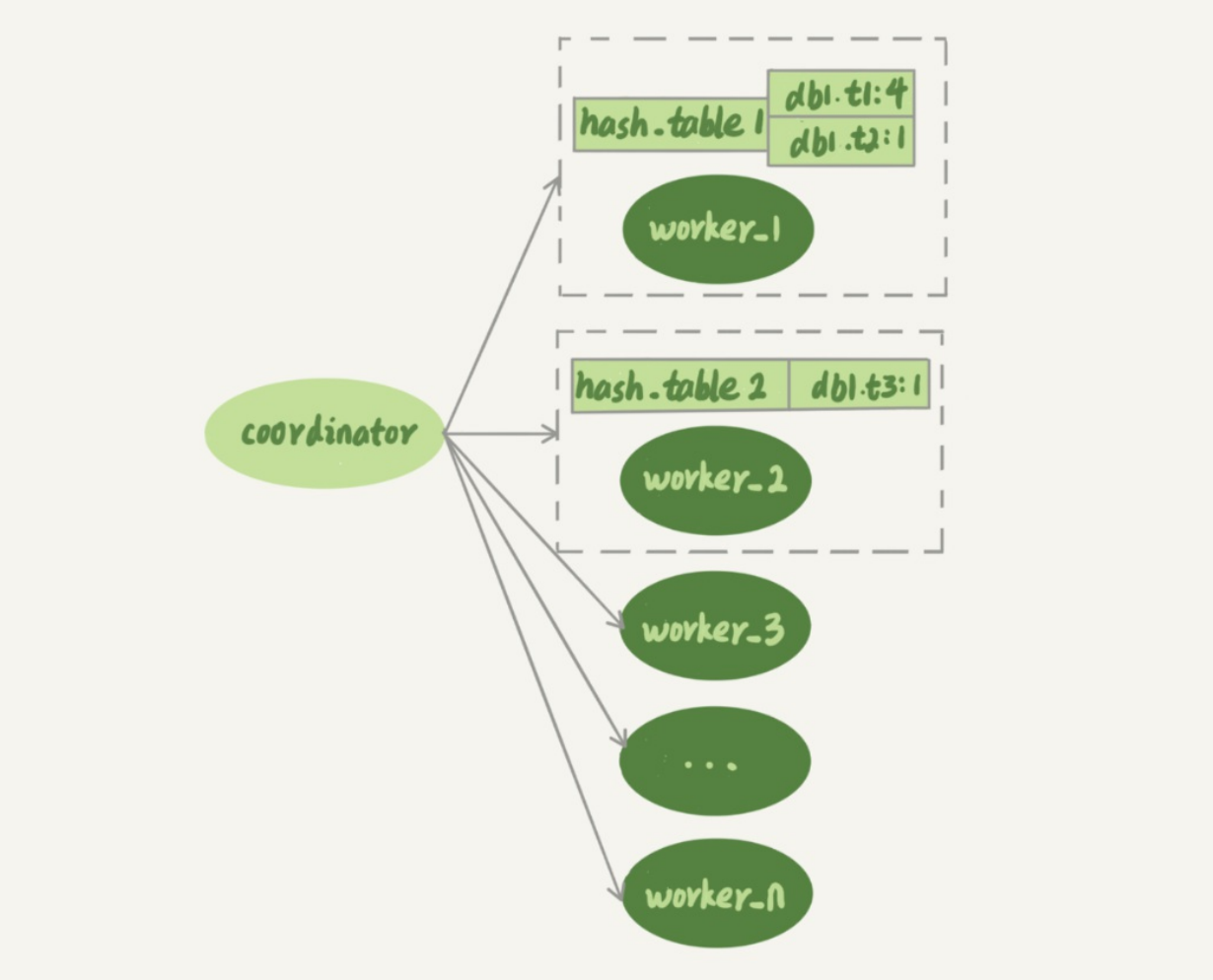
可以看到,每一个worker都有一个hash表,里面存放的是这个worker内部所有事务涉及到的表。
hash表的key值是 库名+表名。value值就是这个worker中有多少个事务需要操作这个表。在有事务分配给worker的时候,往hash表中添加(库名+表名,当前woker中所有事务中有关这个表的个数);worker执行某个事务完成之后,就会将事务中涉及到的表从hash表中去除掉。
上图中的hash_table_1表示,现在worker_1的“待执行事务队列”里,有4个事务涉及到db1.t1表, 有1个事务涉及到db2.t2表;hash_table_2表示,现在worker_2中有一个事务会更新到表t3的数 据。
假设在图中的情况下,coordinator从中转日志中读入一个新事务T,这个事务修改的行涉及到表 t1和t3,来看一下规则:
- 事务T中有对db1.t1的修改,worker1中hash表中有db1.t1,且value值为4,所以事务T和worker1中的事务需要操作同一个表,这种情况说事务T和worker1是有冲突的。
- 按照同样的逻辑,事务T和worker2也是有冲突的
- 因为和事务T有冲突的超过1个,所以coordinator线程就进入等待
- 每个worker进行执行;假设worker2中涉及db1.t3的事务执行完毕了,修改worker2的hash表,
- 这个时候coordinator会发现和事务T有冲突的只有worker1了,所以直接分配给worker1
这里直接将事务T直接分配给worker1,是因为有冲突,表明需要对同一个表进行操作,有可能就是同一行数据的更新,所以根据coordinator的分配要求,必须分给同一个worker,不然事务T的更新语句如果必须在worker1的事务完成之后才可以执行的,但是事务T分配给了其他worker,又被CPU选中,就有可能出现主备不一致的情况。
- 如果跟所有worker都不冲突,coordinator线程就会把这个事务分配给最空闲的woker;
- 如果跟多于一个worker冲突,coordinator线程就进入等待状态,直到和这个事务存在冲突关 系的worker只剩下1个;
- 如果只跟一个worker冲突,coordinator线程就会把这个事务分配给这个存在冲突关系的 worker。
按行分发策略
判断一个事务T和worker是否冲突,用的就规则就不是“修改同一个表”,而是“修改 同一行”。
按行复制和按表复制的数据结构差不多,也是为每个worker,分配一个hash表。只是要实现按行分发,这时候的key,就必须是“库名+表名+唯一键的值”。 但是,这个“唯一键”只有主键id还是不够的,还需要考虑唯一索引的限制。
因此,coordinator在解析这个语句的binlog的时候,这个事务的hash表就有三个项:
- key=hash_func(db1+t1+“PRIMARY”+2), value=2; 这里value=2是因为修改前后的行id值不 变,出现了两次。
- key=hash_func(db1+t1+“a”+2), value=1,表示会影响到这个表a=2的行。
- key=hash_func(db1+t1+“a”+1), value=1,表示会影响到这个表a=1的行。
由此可以看到,按行分发策略的计算量是大于按表分发策略的,毕竟精度更细了。
这两个方案其实都有一些约束条件:
- 要能够从binlog里面解析出表名、主键值和唯一索引的值。也就是说,主库的binlog格式必须是row;
- 表必须有主键;
- 不能有外键。表上如果有外键,级联更新的行不会记录在binlog中,这样冲突检测就不准确。
因为按行分发策略需要计算每一行的hash值,如果有多个唯一索引的话,计算量更大,所以在一个涉及特别大量数据的事务中,按行分发策略会很慢。比如删除一个100万行的数据。
- 耗费空间。首先得存储100万行的hash表
- 耗费CPU。得计算起码100万次的hash值
MYSQL5.6的并行复制策略
官方MySQL5.6版本,支持了并行复制,只是支持的粒度是按库并行
相比于按表和按行分发,这个策略有两个优势:
- 构造hash值的时候很快,只需要库名;而且一个实例上DB数也不会很多,不会出现需要构 造100万个项这种情况。
- 不要求binlog的格式。因为statement格式的binlog也可以很容易拿到库名。
如果业务上所有的表的都放在一个库下面,那其实就还是单线程复制;
如果不同DB的 热点不同,比如一个是业务逻辑库,一个是系统配置库,那也起不到并行的效果。因为多个事务需要访问业务逻辑库,但是因为是同一个库,所以就等于单行复制。当然如果把这个业务逻辑库的数据均匀的放在不同的DB中,那就可以实现多行复制了。这种不是很常用。
MariaDB的并行复制策略
MariaDB的并行复制策略利用了组提交的特性:
- 同一个批事务中,不会有多个事务修改同一行,因为修改同一行的话,会有锁。
- 主库中可以并行执行的事务,备库也一定可以执行。
在实现上,MariaDB是这么做的:
- 同一批事务中有相同的commit_id,下一组就是commit_id+1
- commit_id直接写在binlog中
- 传到备库应用的时候,相同commit_id的事务分发到多个worker执行;
- 这一组全部执行完成后,coordinator再去取下一批。
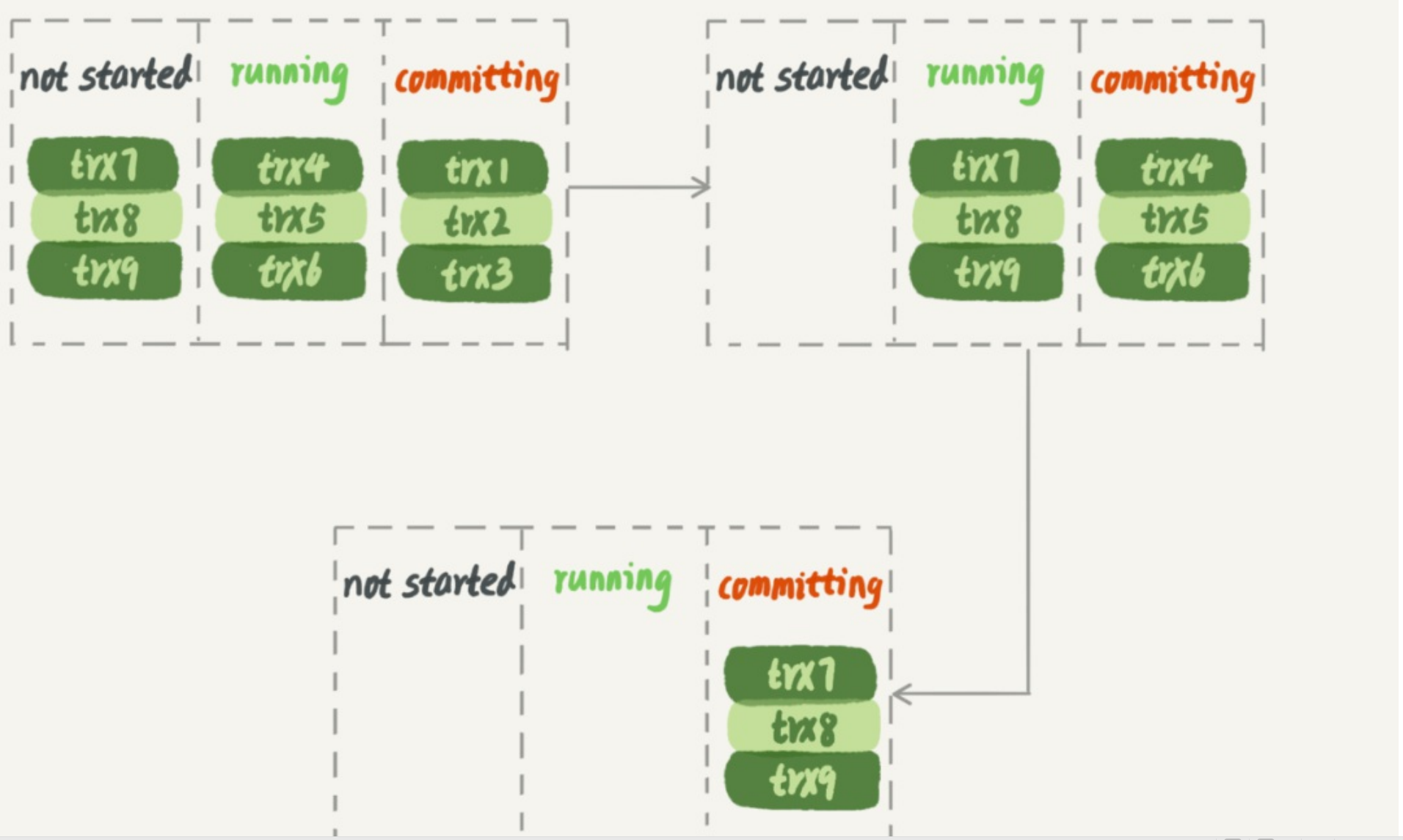
在主库并行执行的事务中,trx1,tr2,tr3这一批事务在处于committing的时候并且写入完毕之后,trx4,trx5,trx6就会进入committing状态。
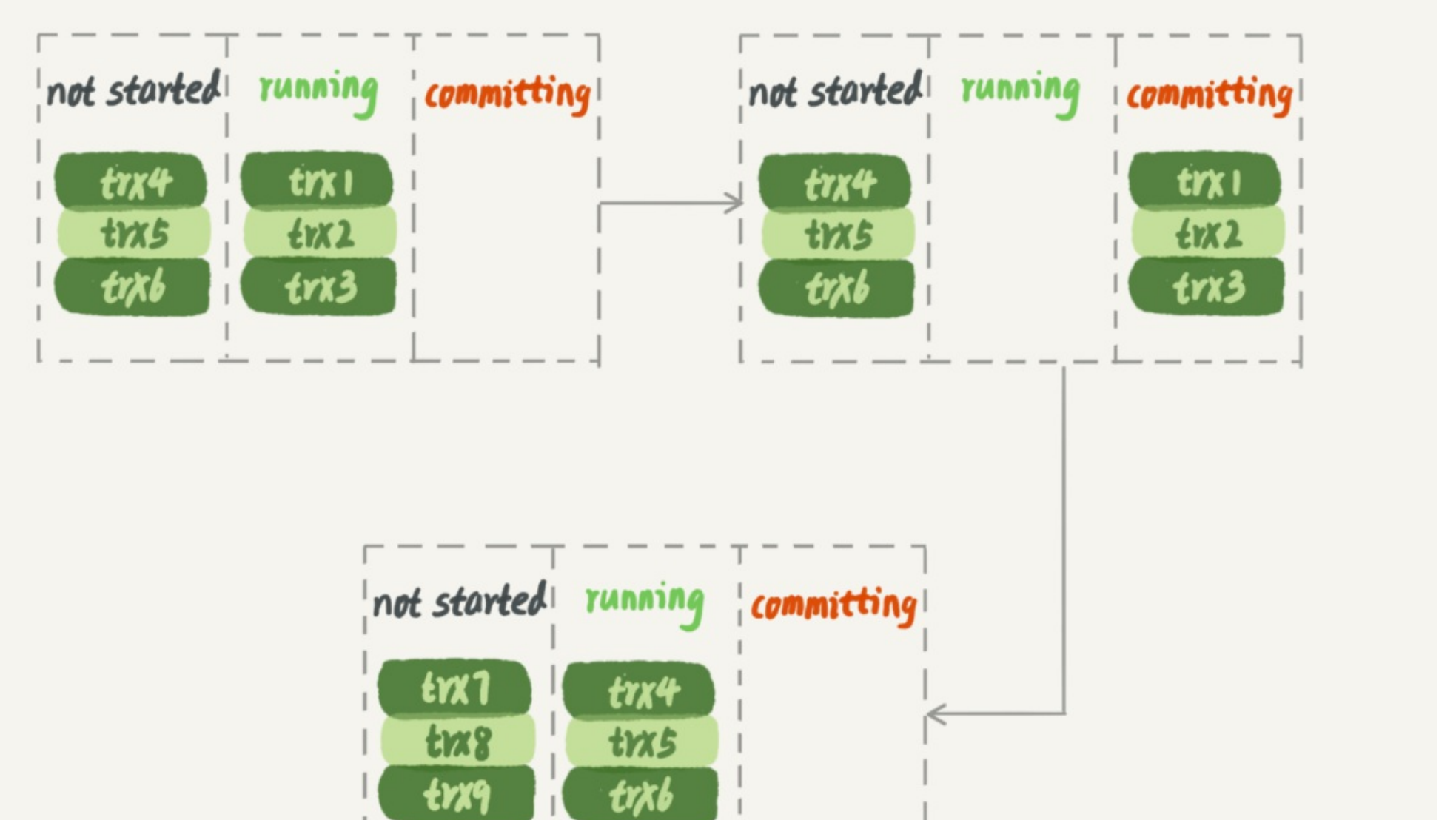
可以看到,在备库上执行的时候,要等第一组事务完全执行完成后,第二组事务才能开始执行, 这样系统的吞吐量就不够。
MYSQL5.7的并行复制策略
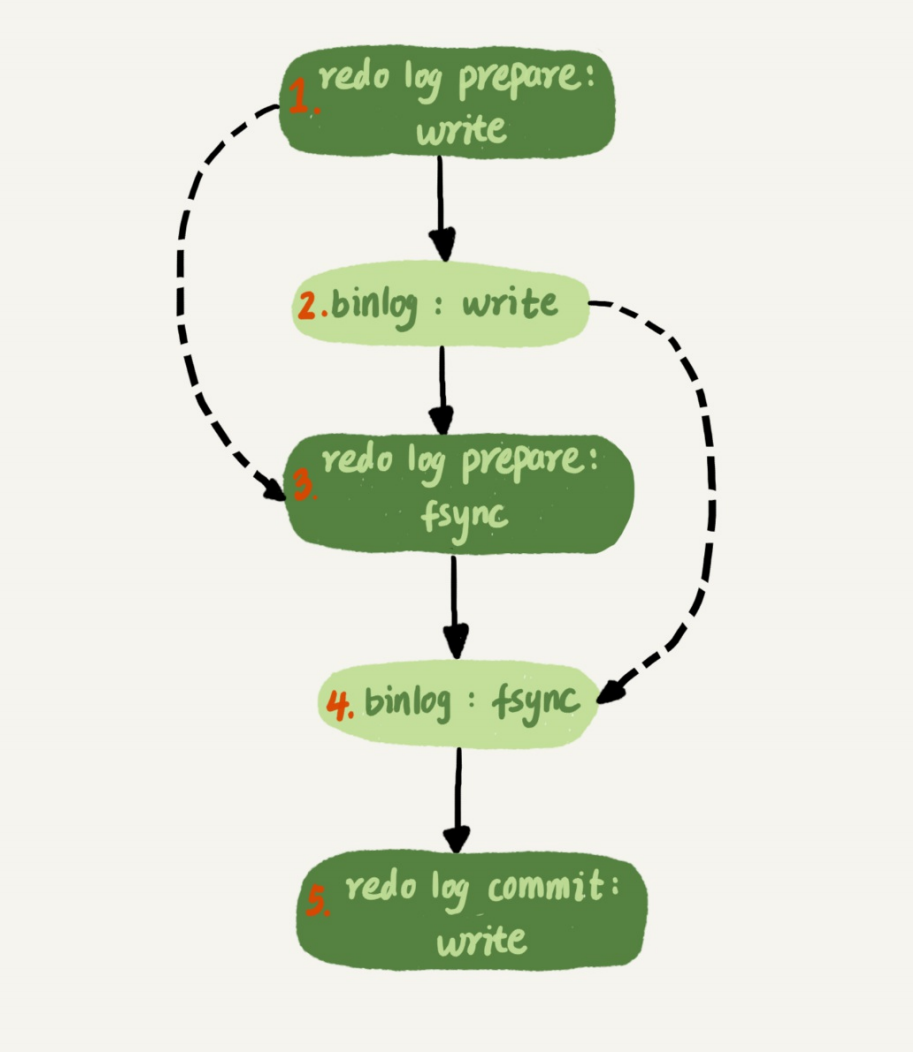
MySQL 5.7的并行复制策略的思想是:
- 同时处于prepare状态的事务,这个时候已经通过锁冲突的检测,所以在备用库也是可以并行执行的
- 处于prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的。
在组提交那块有提到过两个参数
binlog_group_commit_sync_delay参数,表示延迟多少微秒后才调用fsync;
binlog_group_commit_sync_no_delay_count参数,表示累积多少次以后才调用fsync
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL 5.7的并行复制策略里,它们可以用来制造更多的“同时处于prepare阶段的事务”。这样就增加了备库复制的并行度。
MYSQL5.7.22的并行复制策略
在2018年4月份发布的MySQL 5.7.22版本里,MySQL增加了一个新的并行复制策略,基于 WRITESET的并行复制。
相应地,新增了一个参数binlog-transaction-dependency-tracking,用来控制是否启用这个新策略。这个参数的可选值有以下三种。
- COMMIT_ORDER,表示的就是前面介绍的,根据同时进入prepare和commit来判断是否可 以并行的策略。
- WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合 writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并 行。
- WRITESET_SESSION,是在WRITESET的基础上多了一个约束,即在主库上同一个线程 先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
当然为了唯一标识,这个hash值是通过“库名+表名+索引名+值”计算出来的。如果一个表上除了 有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增 加一个hash值。
MySQL官方的这个实现还是有很大的优势:
writeset是在主库生成后直接写入到binlog里面的,这样在备库执行的时候,不需要解析 binlog内容(event里的行数据),节省了很多计算量;
不需要把整个事务的binlog都扫一遍才能决定分发到哪个worker,更省内存;
由于备库的分发策略不依赖于binlog内容,所以binlog是statement格式也是可以的。
当然,对于“表上没主键”和“外键约束”的场景,WRITESET策略也是没法并行的,也会暂时退化 为单线程模型。














 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









