







创建两个表:
CREATE TABLE `t2`
( `id` int(11) NOTNULL,
`a` int(11) DEFAULTNULL,
`b` int(11) DEFAULTNULL,
PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB;
这两个表的表结构是一样的,id为主键,a上加索引,b上没有索引。
然后t2表中插入1000条数据,t1中复制t2中的100条数据。
执行一条查询语句:
explain select * from t1 straight_join t2 on (t1.a=t2.a);
straight_join是让MYSQL使用固定的连接方式执行查询,直接用join的话MYSQL优化器可能会选择t1或者t2作为驱动表。
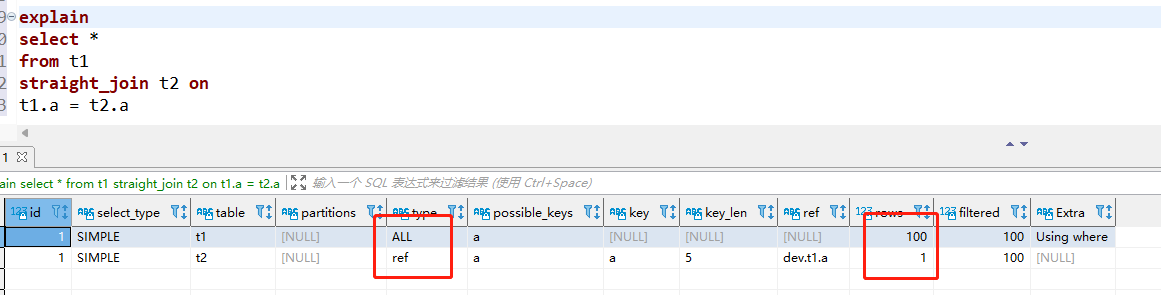
可以看到t2中使用到了a列的索引的,执行流程如下:
- 从t1表中取出一行数据R
- 在数据R中找到a字段,根据a字段到t2表中去查询数据
- 取出t2表中符合条件的数据,和R组成一行,因为select * 所以会将t1表和t2表的字段都查询出来
- 重复步骤1和到步骤3,一直到t1表查询完
这个过程是先遍历表t1,然后根据从表t1中取出的每行数据中的a值,去表t2中查找满足条件的记录,并且可以用上被驱动表的索引,
称之为“IndexNested-Loop Join”,简称NLJ。
修改一下查询sql:
explain select * from t1 straight_join t2 on (t1.a=t2.b);
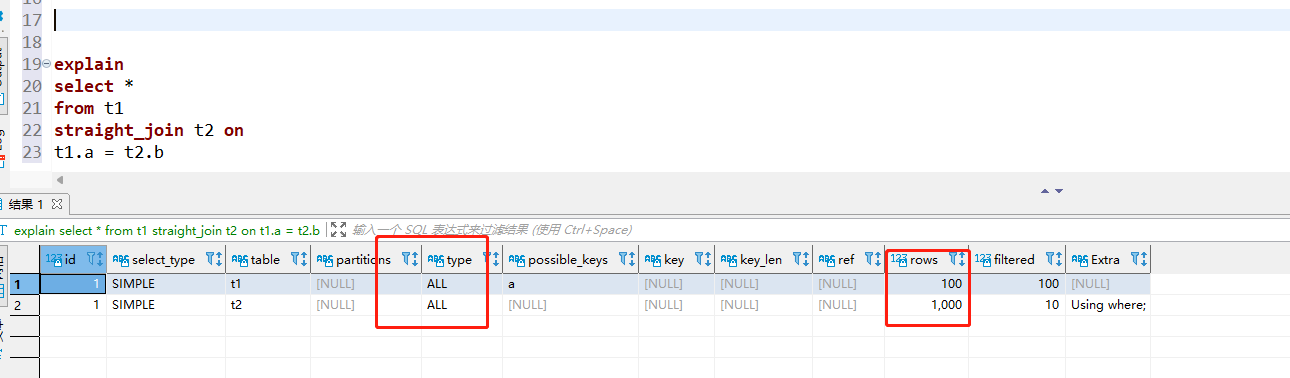
可以看到t2表中是没有使用到索引的,所以是走的全表扫描,扫描行数就是100*1000=100000行,但是之前使用到索引字段的查询扫描行数只有100+100=200行,差距还是很明显的。
这种算法叫做Simple Nested-Loop Join,MYSQL并没有使用这个算法,而是用的“Block Nested-Loop Join”的算法,简称BNL。
大概的流程如下:
- 从t1表中取出一行,放入到线程内存join_buffer中,这里是select *;所以放入到join_buffer的是驱动表也就是t1的所有字段。
- 扫描t2表,取出一行数据,和join_buffer中的数据进行比较,符合条件的和join_buffer组成结果集。Block Nested-Loop Join算法中扫描行数但是固定的,也是100*1000=100000行,但是是在内存中进行的,所以速度会快点。
join_buffer的内存大小是有限的,如果t1表中的100行数据是放不下join_buffer里的,那就需要分多次放到job_buffer中,join_buffer是由参数join_buffer_size配置的。执行过程就变成了:
- 扫描表t1,顺序读取数据行放入join_buffer中,放完第88行join_buffer满了,继续第2步;
- 扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结 果集的一部分返回;
- 清空join_buffer;
- 继续扫描表t1,顺序读取最后的12行数据放入join_buffer中,继续执行第2步。
这时候由于表t1被分成了两次放入join_buffer中,导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是判断等值条件的次数还是不变的,依然是(88+12)*1000=10万次。
如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用。
判断要不要使用join语句时,就是看explain结果里面,Extra字段里面有没有出现“Block Nested Loop”字样,如果出现了Block Nested Loop,尝试增加点join_buffer_size大小看是否可以。
看两个sql:
select * from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=50;
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50;
这个时候因为t1表只查询50条数据,所以相对来说是个小表,所有优先t2表作为驱动表,t1作为被驱动表。
再看:
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
表t1只查字段b,因此如果把t1放到join_buffer中,则join_buffer中只需要放入b的值;
表t2需要查所有的字段,因此如果把表t2放到join_buffer中的话,就需要放入三个字段id、a和 b。
(但是这块我想如果t1作为驱动表,也就是就t1的数据行放入到job_buffer中,但是t2的数据还需要和job_buffer中的字段进行判断是否符合条件,那是不是job_buffer中除了放查询字段,还需要放判断条件字段)
所以,更准确地说,在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,在过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表 ”,应该作为驱动表。















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









