







随着半导体行业的快速发展,芯片制造过程中的缺陷检测成为保障产品质量和提高生产效率的重要环节。传统的人工检测方法不仅耗时且容易出现遗漏和误判,因此,开发一种高效、准确的自动化检测系统变得尤为重要。本文提出了一种基于YOLOv8深度学习模型的芯片缺陷智能检测与分割系统,旨在识别和分割芯片表面常见缺陷类型,包括“芯片字符污痕”、“芯片表面划痕”、“芯片基材破损”和“芯片引脚损坏”。系统利用YOLOv8模型进行芯片缺陷图像的目标检测和分类,同时结合图像分割技术,精准定位并标注缺陷区域。
本文对芯片缺陷数据集进行预处理和标注,包括图像增强、数据归一化等步骤,以提高模型训练的效果。然后,采用YOLOv8模型进行训练,优化模型的准确率和推理速度。为了实现实时检测与分割,本文在PyQt5平台上开发了用户界面(UI),实现了图像上传、实时检测、缺陷标注和结果展示等功能。
实验结果表明,所提出的系统在准确率、召回率和推理速度方面均达到了较高水平,能够有效识别芯片表面缺陷并进行精确分割。该系统为芯片制造过程中的缺陷检测提供了一种自动化的解决方案,具有较好的应用前景,能够有效提升生产效率和产品质量。
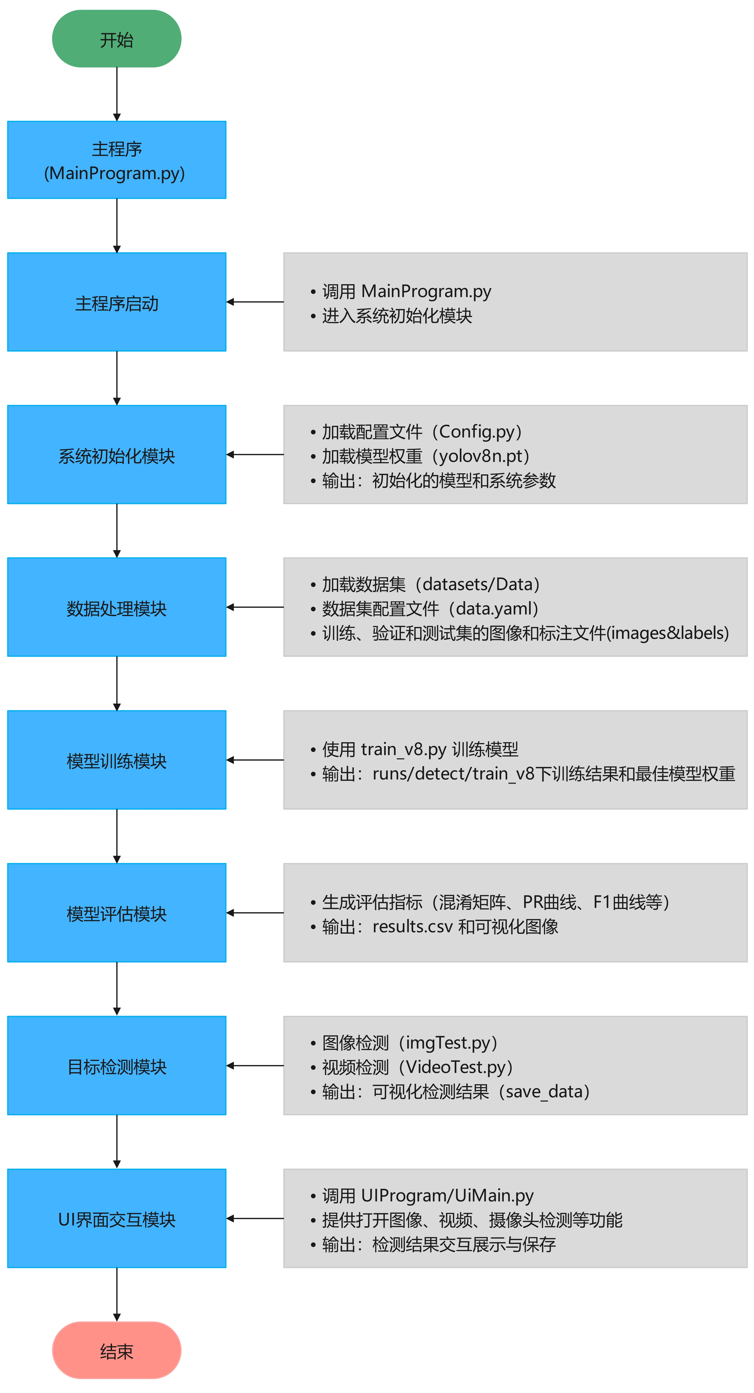
算法流程
Tipps:深入解析项目的算法流程,逐步探索技术实现的核心逻辑。从数据加载与预处理开始,到核心算法的设计与优化,再到结果的可视化呈现,每一步都将以清晰的结构和简洁的语言展现,揭示技术背后的原理与实现思路。
硬件环境
我们使用的是两种硬件平台配置进行系统调试和训练:
(1)外星人 Alienware M16笔记本电脑:

(2)惠普 HP暗影精灵10 台式机:

上面的硬件环境提供了足够的计算资源,能够支持大规模图像数据的训练和高效计算。GPU 的引入显著缩短了模型训练时间。
使用两种硬件平台进行调试和训练,能够更全面地验证系统的性能、适应性和稳定性。这种方法不仅提升了系统的鲁棒性和泛化能力,还能优化开发成本和效率,为实际应用场景的部署打下良好基础。
模型训练
Tipps:模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
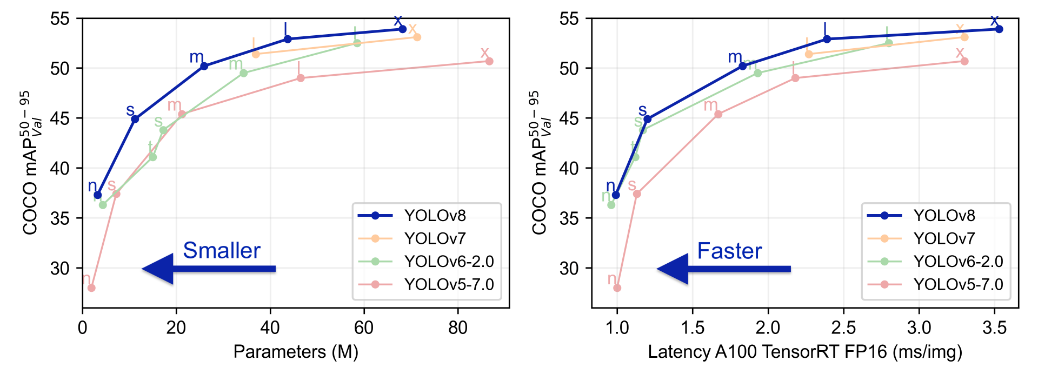
YOLOv8是Yolo系列模型的最新王者,各种指标全面超越现有对象检测与实例分割模型,借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,在全面提升改进Yolov5模型结构的基础上实现,同时保持了Yolov5工程化简洁易用的优势。
Yolov8模型网络结构图如下图所示:
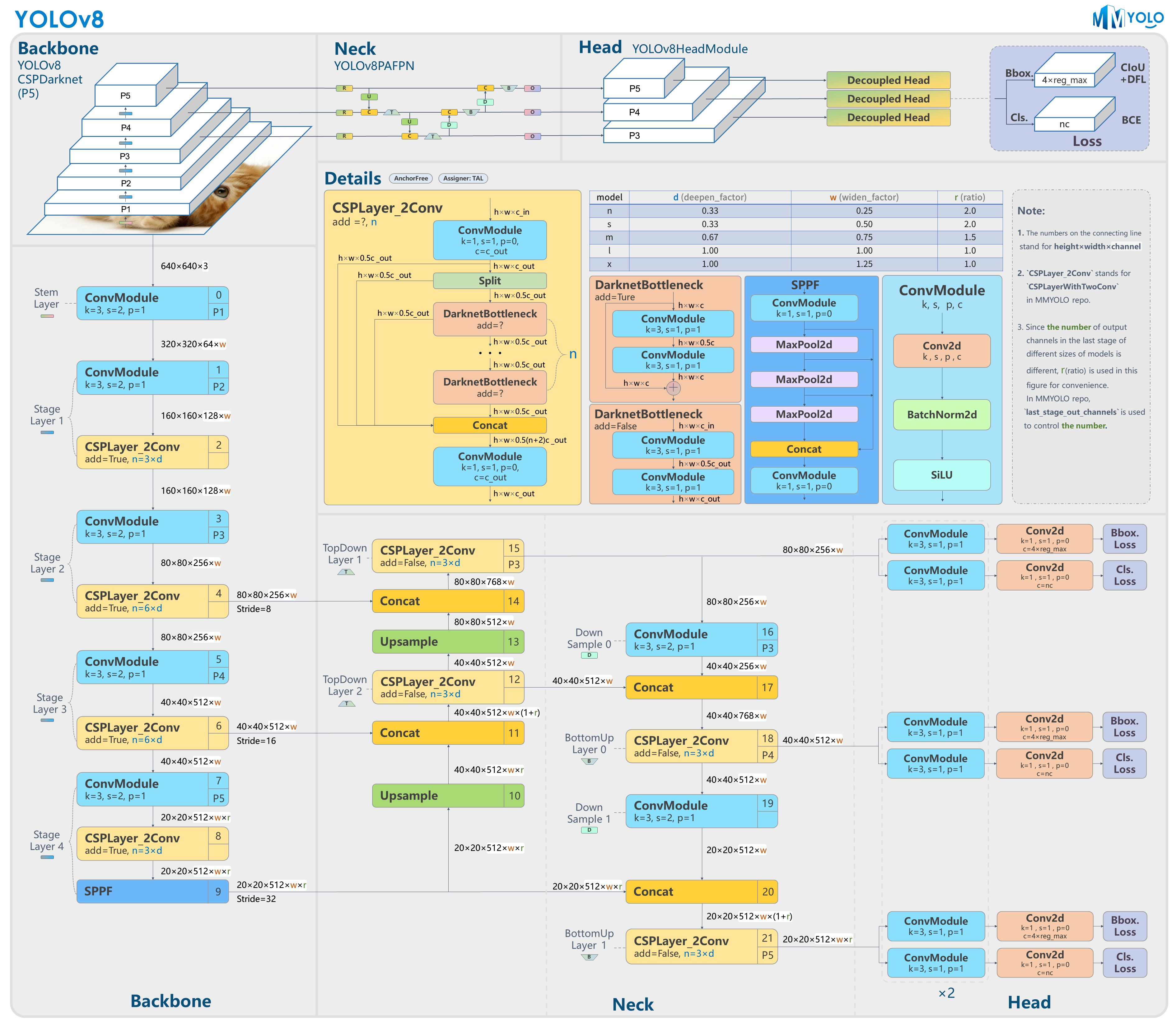
2.数据集准备与训练
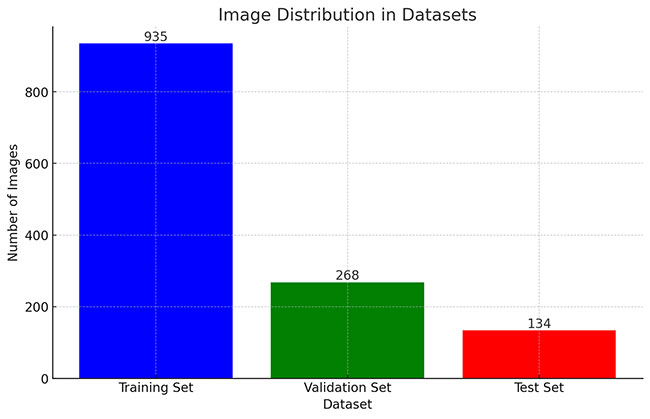
本研究使用了包含芯片缺陷相关超声图片的数据集,并使用Labelme标注工具对每张图片中的分割结果及类别进行标注。基于此数据集,采用 YOLOv8n 模型进行训练。训练完成后,对模型在验证集上的表现进行了全面的性能评估与对比分析。整个模型训练与评估流程包括以下步骤:数据集准备、模型训练、模型评估。本次标注的目标类别主要集中于芯片缺陷相关超声图片。数据集总计包含 1337 张图像,具体分布如下:
训练集:935张图片。
验证集:268张图片。
测试集:134张图片。
数据集分布直方图
以下柱状图展示了训练集、验证集的图像数量分布:
部分数据集图像如下图所示:

部分标注如下图所示:

这种数据分布方式保证了数据在模型训练、验证阶段的均衡性,为 YOLOv8n 模型的开发与性能评估奠定了坚实基础。
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入datasets目录下。
接着需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。
data.yaml的具体内容如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









