









目录
小项目1:爬取豆瓣top250前10页电影的分数、影评、名称
练手:爬取豆瓣top250电影排行榜第一页
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
url="http://movie.douban.com/top250"
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
target=soup.find_all('div',class_='hd')
for each in target:
print(each.a.span.text)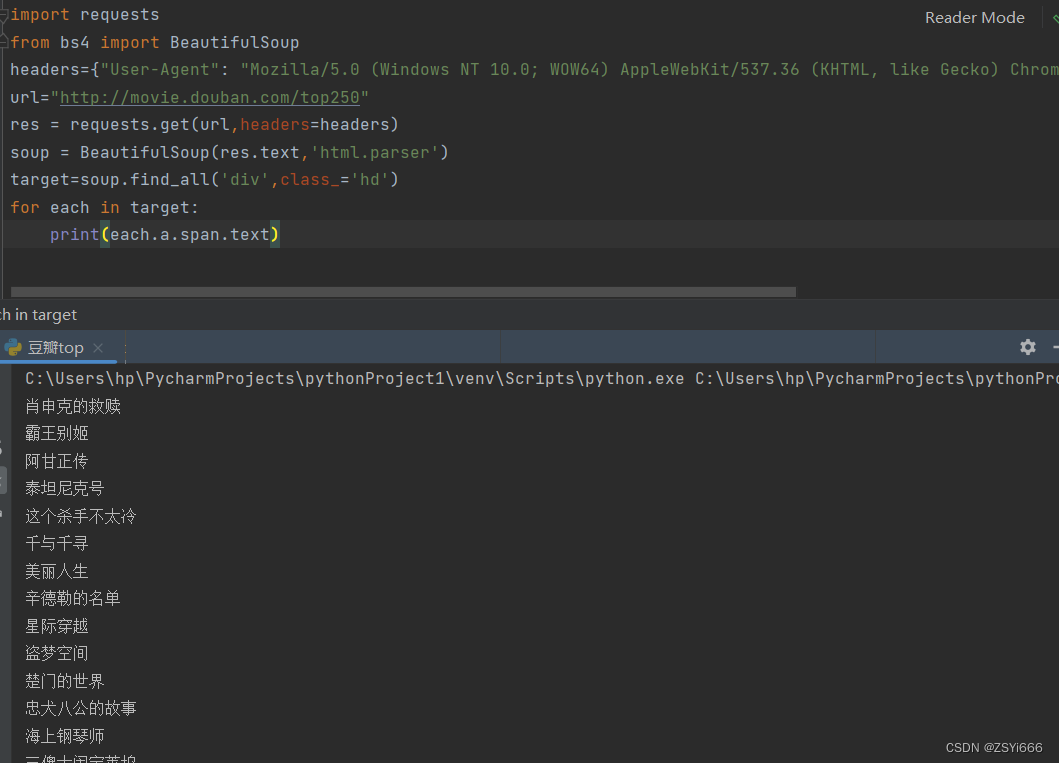
练手:爬取豆瓣top250第一页电影的影评
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
url="http://movie.douban.com/top250"
response=requests.get(url,headers=headers)
print(response.status_code)
datalist=[]
datalist=response.text
ad=BeautifulSoup(datalist,"html.parser")
bc=ad.findAll("span",class_="inq")
for each in bc:
print(each)
练手:爬取豆瓣top250前十页电影的影评
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
for star_num in range(0,250,25):
response = requests.get(f"http://movie.douban.com/top250?start={star_num}", headers=headers)
datalist=response.text
ad=BeautifulSoup(datalist,"html.parser")
bc=ad.findAll("span",class_="inq")
for each in bc:
print(each)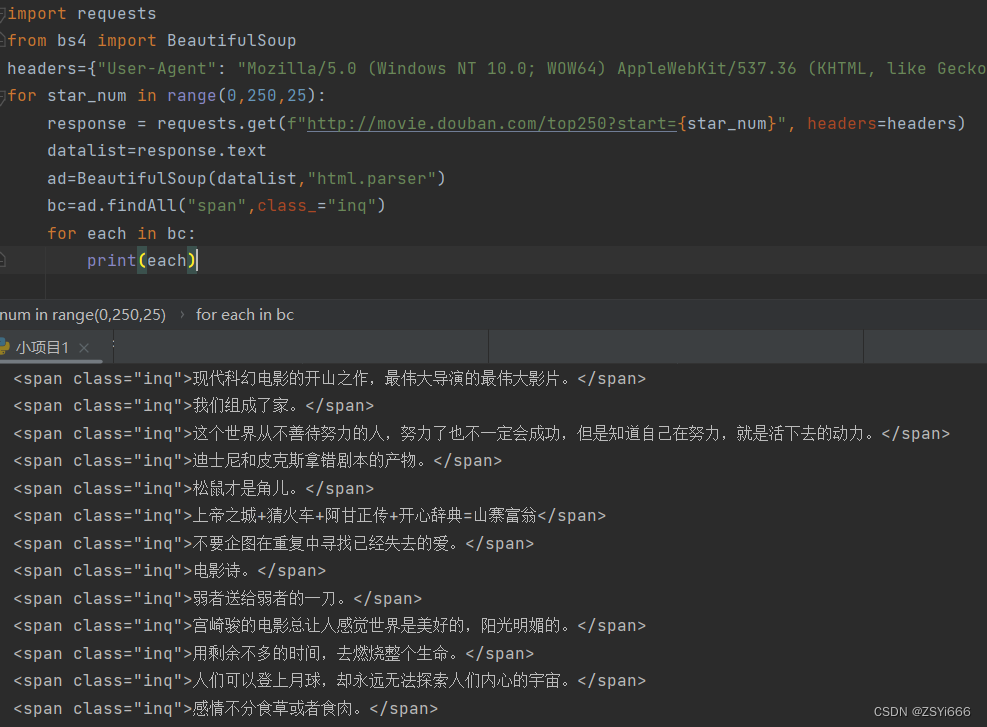
小项目1:爬取豆瓣top250前10页电影的分数、影评、名称
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
for star_num in range(0,250,25):
response = requests.get(f"http://movie.douban.com/top250?start={star_num}", headers=headers)
datalist=[]
datalist=response.text
ad=BeautifulSoup(datalist,"html.parser")
all_titles =ad.findAll("span", attrs={"class": "title"})
all_grades =ad.findAll("span", attrs={"class": "rating_num"})
bc=ad.findAll("span",class_="inq")
all_=all_grades+all_titles+bc
for each in bc :
print(each)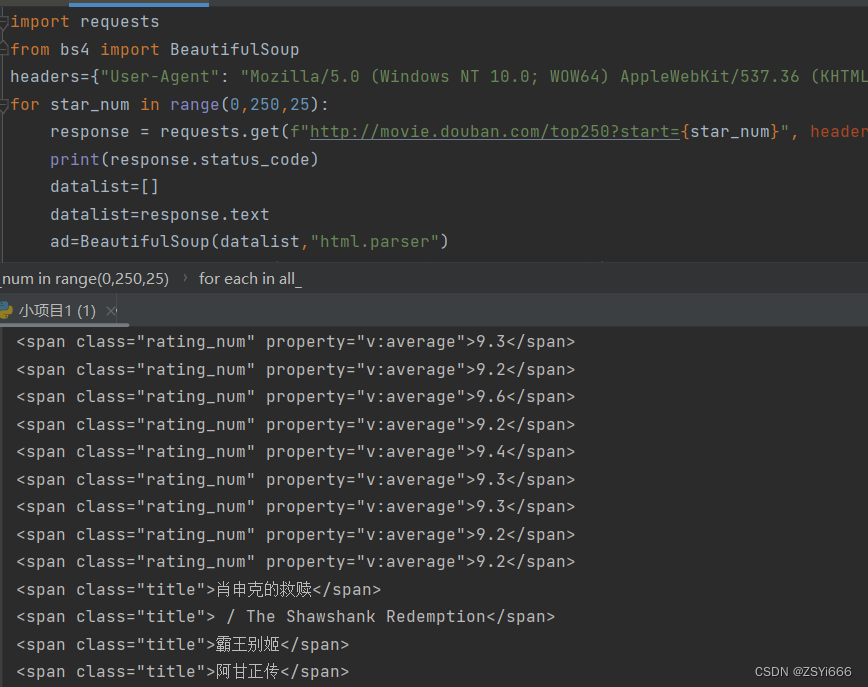















 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









