









目录
注:python使用requests爬取网页出现中文乱码:字符编码问题引起
爬取:2023流行歌曲排行榜150首
import requests
from bs4 import BeautifulSoup
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36"}
url="http://www.yy8844.cn/paihangbang/top100.shtml"
response=requests.get(url,headers=headers)
print(response.status_code)
print(response.encoding)
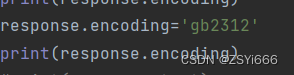
response.encoding='gb2312'
print(response.encoding)
#print(response.text)
datalist=[]
datalist=response.text
ad=BeautifulSoup(datalist,"html.parser")
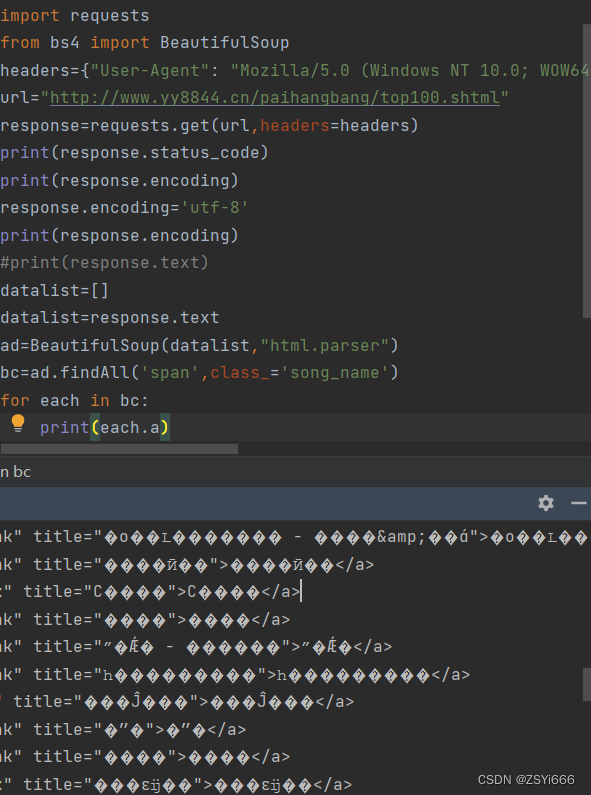
bc=ad.findAll('span',class_='song_name')
for each in bc:
print(each.a)
注:python使用requests爬取网页出现中文乱码:字符编码问题引起
可以通过指定的encoding基本解决问题
在浏览器中,在待爬取网页上右键单击,选择“查看页面源代码”

(字符集)charset=gb2312
在代码中添加一行,指定requests对象encoding的值为“gb2312”即可















 2933
2933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









