







大数据特点
- 大量
- 高速
- 多样
- 结构化
- 非结构化
- 价值密度:快速对有效数据的”提纯“
业务流程分析
需求——>数据部门搭建数据平台——>数据可视化
大数据部门组织结构
- 平台组
- Hadoop、FLume、Kafka、HBase、Spark等框架平台搭建
- 集群性能监控
- 集群性能调优
- 数据仓库组
- ETL数据清洗
- Hive数据分析、仓库建模
- 数据挖掘组
- 算法工程师
- 推荐系统工程师
- 用户画像工程师
- 报表开发组
- JavaEE工程师
Hadoop概念
因为Lucene项目面对海量数据,存在存储数据困难,检索速度慢等问题
Hadoop用于解决海量数据的存储和分析问题
GFS——>HDFS
Map-Reduce——>MR
BigTable——>HBase
Hadoop优势
- 高可靠性:维护多个数据副本
- 高可扩展性:集群间分配任务,方便扩展节点
- 高效性:MapReduce并行计算
- 高容错性:能欧自动将失败的任务重新分配
Hadoop组成
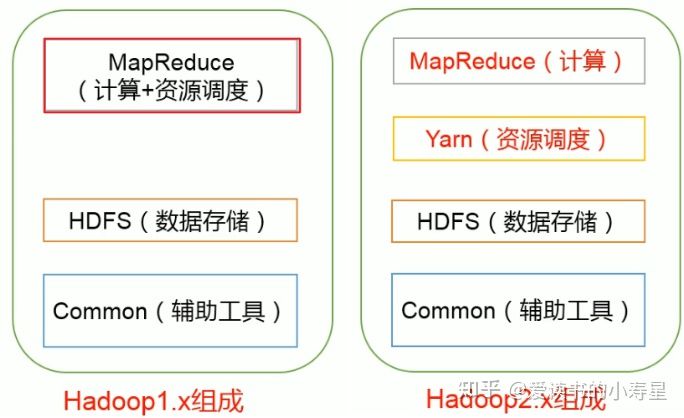
- Hadoop2.0中Yarn单独负责调度
- Common:一组分布式文件系统和通用I/O的组件与接口(序列化、Java RPC和持久化数据结构)
- HDFS:分布式文件系统
- Pig:检索数据集
- Hive:分布式、按列存储的数据仓库。Hive管理HDFS中存储的数据,并提供基于SQL查询语言。
- HBase:分布式,按列存储数据库
- Zookeeper:分布式,可用性高的协调服务
- Sqoop:数据库和HDFS之间高效传输数据的工具
具体学习内容
- HDFS——存储
- MapReduce——分析处理
- YARN——调度















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









