







01
前言
随着业内容器化的普及和业务发展,公司内集群规模、集群数量不断增加。其中为了实现 pod ip 公司全网可达,采用了向接入交换机宣告 bgp 的方案。
遇到的问题是集群、pod 网络需要精确规划,交换机等网络设备需要额外管理、配置。开发、管理、运维成本较高,并形成故障隐患。
加之公司虚拟化团队有成熟的云网络方案,可以使容器网络接入使用虚拟化云网络,实现降本增效的同时,又满足灵活、稳定、高性能等诉求。
可以为公司容器云下一步规划,提供更多的想象空间。
02
方案
方案涉及 2 个维度,1 是容器在 k8s 节点上的转发面实现(CNI);2 是 IPAM(IP Address Management)容器 IP 管理。
1. CNI
主流开源 CNI 实现,容器在 k8s 节点的转发面驱动,绝大多数为 bridge + veth pair(flannel、calico、cilium,weave)。
veth pair 可以在 CentOS 7 等较旧操作系统(内核 3.10.x)。
考虑到公司节点,系统较新(4.19.x、5.10.x),可以使用 linux 内核新特性 ipvlan。
ipvlan vs macvlan
ipvlan | macvlan | |
|---|---|---|
Network Interface Compatibility | Limited Mac Address | Common DHCP Server |
Hardware Performance | High CPU, Low Network Utilization | Low CPU, Normal Network Utilization |
Security | Meets 802.11 standards | Unknown |
Implementation | Easy to Set-Up | Needs Advanced Router Configuration |
macvlan 有 bridge、private、vepa、passthru 等 4 种模式,适用于不同场景。ipvlan 有 l2、l3 两种工作模式。
由于 k8s 容器场景,不需要为 pod 分盘独立 mac,涉及到的网络策略、acl、qos 等,均可由云网络 ovs 层实现。加之是为了复用虚拟化云网络,容器层 pod 网络应该只做接入。
其中涉及到 CPU 使用,ipvlan 是相较于 macvlan 高,而不是影响到性能的“高”。而 macvlan 的低,一定程度上是因为把交换下放给力网络设备,内核不做交换。
其中涉及到 ipvlan 的 l2、l3 模式,l3 是 ip 路由展开到节点本身,会绕开 subnet 的 gateway。
综合对比,以及参考业内开源 CNI(Aliyun Terway、Cilium ipvlan dataplane)后,决定使用 ipvlan l2。
2. IPAM
云网络 VPC 的 ip 由 ultron、openstack 进行分配,容器侧,需要对接 ultron、openstack 接口。ip 的公司全网可达,通过虚拟化云网络网关实现,容器侧需要对接 floating ip 接口。
k8s 容器侧,通过配置容器 VPC 网络、子网,实现同集群 pod 可以灵活指定使用的 ip。
早期落地开发过程中,基于阿里云开源 terway 进行 hulk 适配改造。可以实现基本的接入能力。
但是缺乏指定 VPC、子网,指定安全组,指定 Qos bandwidth 能力。加之 terway 本身工程结构问题(核心逻辑是个 object pool,ipam 逻辑包在 pool 之外,没法对 pool 做额外区别操作),决定从头开发实现 hulk-vpc-cni,以满足公司内容器上云网络涉及的多种需求。
03
实践问题
落地实践过程,遇到种种问题,最终攻坚解决,并验证可靠。
1.Service
接云网络 VPC 后,pod 容器内,网络默认路由,需要配成对应 subnet 的 gateway。
另一方面,k8s service 是云原生最基本语义之一,service 网络如果走默认路由,去 subnet gateway,会 no route to host。
需要给 service 网络引流,引道 pod 所在节点本身,节点上有 kube-proxy 生成的 service 网络 ipvs、iptables 规则。
VPC 裸金属
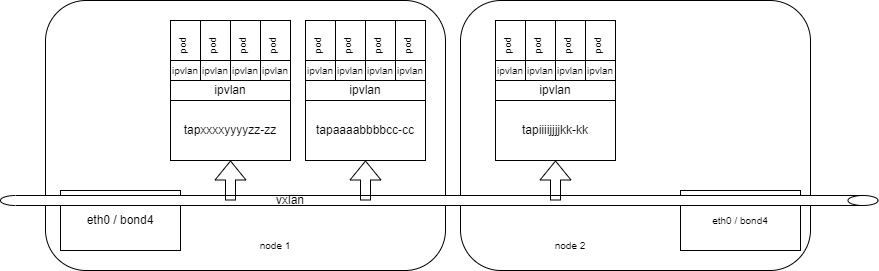
VPC 裸金属,为改造传统裸金属节点,安装 VPC 组件,ovs 挂载 tap 网卡,修改节点默认路由,走 vpc tap 网卡。
最初的思路为,cni agent 发现默认路由是 VPC 网络 subnet gateway,则修改默认路由,修改回 10 网络。
向 pod 内添加去 service 网段的路由,下一跳为 pod 所在裸金属节点。则 service 网络流量可以导到节点本身,走 kube-proxy 规则。
流量路径为,去,pod 到节点,节点走 10 网关,回,为回到 pod ip 所在 subnet gateway,再到 pod。
此方案,有 2 个问题,1 是去程、回程流量路径不同,11 裸金属虽然还有 11 ip,但是默认路由是 10 的;2 是当安全组 driver 升级为 ovs 后,由于去程回程路径不同,conntrack 里没有回程状态,流量直接被 drop,导致 service 网络不通。
经过与虚拟化部门共通攻坚,VPC 裸金属的 service 网络,通过 2 步实现:
一是需要将 vpc 自身 11 ip 从 ovs 直接挂 tap,换成 qbr、qvo、qvb 方案,用 bridge + veth pair 转一下,这一步的目的是使 kube-proxy 的 iptables 规则生效,如果是最初的 tap,则 iptables 规则不生效。
二是给每个 pod fixe ip 加去 service 网络的流表规则。
至此,service 网络通过流表,经 ovs 引道 vpc 自身 11 网卡到宿主机,走 kube-proxy 规则。实现连通。
非 VPC 10 裸金属
最初方案与 VPC 裸金属初始方案一样,由于裸金属自身没有 11 ip,直接路由即可。后同样由于安全组 driver 升 ovs 原因,流量去程、回程路径不一致,conntrack 里没有状态,被 drop 掉,导致不通。
后与 VPC 裸金属一致,也通过 ovs 流表规则实现向宿主机 service 引流。实现 service 网络连通。
虚拟机
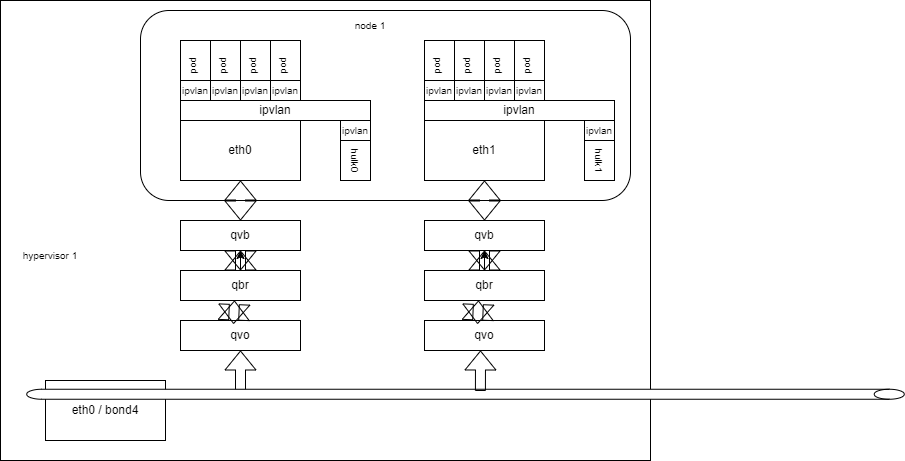
虚拟机比较简单,原因是虚拟机上 openstack port 挂的弹性网卡,在虚拟机上是以设备的形式出现的(eth1、eth2、ethX),直接在虚拟机 network namespace 建出一个 ipvlan 子接口,给 pod 的 ipvlan 子接口里去 service 网络的流量,从挂载虚拟机自身 network namespace 的子接口出,引道虚拟机上,进而走 kube-proxy 规则,实现连通。
iptables、nftables
整个接通 k8s service 的过程,还遇到 kube-proxy iptables 规则的问题(ipvs 模式并不是完全不用 iptables)。需要开 kube-proxy masquade-all 参数,如果不开,去 service 网络的流量,在 ipvs 逻辑里,直接被替成目标 rs 的真实 ip,无法命中流表规则。
另一个问题是龙蜥操作系统,默认有 nftables 规则,优先级比 iptables 高,导致流量没走进 iptables 规则里。
2. pod 启动慢
初期版本由于适配公共集群,不同事业部、项目,可以指定 pod 使用不通的 vpc 子网,实现为同步、飞池化版本。申请 ip,配置 pod ipvlan 子接口,为耗时操作。
导致配 pod 网络会花 10s 左右的时间,反应到使用者的视角,即为 pod 要 10+s 才起。这对与 serverless 等场景是不可接受的。
修复方案是,引入资源池,通过 max idle、min available 维护 pool 水位,实现池化版本,解决 pod 启动慢的问题。
自研池化逻辑,与社区 terway 的池化逻辑,有本质的、核心的区别,terway 的逻辑包在 pool 之外,pool 只管“几个”,是无法满足公共集群,不通业务,使用不通 vpc 的需求的。
自研池化逻辑,pool 只维护设计模式层面的资源复用,而资源本身的生命周期,由池外逻辑维护。
3. 网关同步规则慢
这个问题主要矛盾点,在虚拟化、容器,定位不同,解决问题的初衷不同。毕竟虚拟机、裸金属的创建、销毁频率,要远远低于容器。
新建容器,流表规则同步到 pod 所在节点,存在一定延迟(5s 左右),在此事件内,pod 网络不通,不通的原因是走默认路由网关不同,走网关不通的原因是,arp 解不出网关 ip 的 mac,host unreachable。
由于虚拟化、容器,解决的问题不同。难以在虚拟化云网络层面进一步优化。所有容器侧,进行优化。手段之一是,可以通过 openstack api 查到网关 mac,在配 pod 网络时,直接加网关 ip 到 mac 的静态解析。二是,由于容器测引入池化逻辑,也几乎避开了该问题。在实际给业务部门升级部署,并长期运行后,未再发现该问题。
4. 资源清理
由于 IPAM 是调 ultron、openstack 接口,申请 ip 资源。正常 pod 销毁,会走入 cni delete 流程,释放资源。而如果 k8s 节点关机、集群整体销毁,等等无法走入 cni delete 流程的场景,ip 资源则成为脏数据,并始终占用,最终最坏结果是耗尽 VPC 内可用 ip。
为了避免脏数据产生,从 2 个维度实现了资源清理逻辑。
一是 base 集群维度,检测独享集群的销毁,节点的移除,以及 stark 服务端,用户主动删除独享集群的 callback。对删除的集群占用资源进行删除释放。
二是具体集群 cni controller 里,周期对比上有 ultron、openstack 接口返回的使用状态,与集群存量 pod 状态做对比,删除 pod 已经不存在,实际 ip 还占用的资源(兜底逻辑,测试阶段,频繁创建、删除集群、频繁重启导致,正式上线后未走入此逻辑)。
5. 节点重启
由于运维、降本,等等原因,重启、关闭 k8s 节点是偶尔需要的。容器编排的特性保证了驱逐、滚动发布的可靠,使得在完全不影响线上业务的情况下,可以重启、关闭 k8s 节点。
但是。vpc 云网络配置,在节点关机、重启后会丢。反映到使用者角度,当节点再开机,该节点上的 pod 都不通了。
属于 cni 逻辑没有覆盖到重启 reload 配置,加入重启重新配置逻辑,即可解决。
6. 异步、并发
由于 pod 可能落在不同 k8s 节点,每个节点上 pod 的创建、销毁,是并发发生的,加之池化逻辑,为异步处理。在大规模,大压力场景下(如 serverless 瞬间弹出几十个 pod,瞬间销毁几十个 pod),出现 vpc 资源操作逻辑错误(一边创建一边销毁)、死锁等异步、并发场景的程序逻辑问题。
04
投产
从 2022 年初开始投入编码开发,陆续小量级上线,迭代至今,已经有 2 部分业务长期使用容器 VPC 投入生产。
1. db 混部
db 集群为最初使用容器 VPC 的环境,总 zzzc2 的 20 台节点,到后续由其他同事在不通机房,部署的其他集群,截至至今,已经有 xx 台节点。
从 zzzc2 的 20 台节点算起,至今 db 集群使用容器 vpc 已经稳定运行至少 2 个季度。
db 集群对容器 vpc 能投产上量,起到了推动示范作用。
2. Serverless
serverless 集群公有 x 个机房,xx 个节点,在投产实践过程中,为容器 vpc 的好用、易用、云原生化,提供了建设性的反馈,倒逼容器 vpc 完善迭代。
3. hbox
高性能 gpu 环境,最初 vpc、overlay 两种方案共通存在于同一个集群,后在使用过程中,逐步发现容器 vpc 的稳定、性能等优势,逐步扩 vpc 节点。
后又在 lycc 机房,为借条单独部署独享集群,使用隔离 vpc,并选择性、针对性的放通某一网段,添加到 hdfs 白名单,重复落地了容器 vpc 的隔离性、易用性。
4. 运维
是程序,就会有 bug,google 的程序如此、linux 如此,所有程序都如此,因为人就是会犯错,与水平无关。
但是生产,是严肃的,任何故障,都可能造成真金白银的损失,为了避免损失、最小化故障,在开发迭代,生成运维的过程中,整理了丰富的运维文档。
并且 vpc cni 程序里,也暴露了多种监控指标,在出问题之前,可以人工干预。vpc cni 程序里,也实现了大量运维接口,用于必要时人工救火。
现阶段运维由开发自己承担,如有程序问题,可以第一时间修复。经过近一个季度的生产,容器vpc已经非常稳定,已经达到交付给专业运维同事的标准。
05
完善上量
经过 db 集群、 serverless 集群、hbox 集群、独享集群的生产检验,容器 vpc 已经达到生产上量,大规模推广的标准。
其中 hbox shyc2 集群,已经稳定运行近一个月,毫无人工干预、修复升级,正常稳定运行。
06
结语
近期公司层面“All in AI”,作为算力基础,容器网络的高性能、可靠、易用,给上层业务提供了更多的想象空间。
容器部门,也在落地基于 vpc 的多集群算力分享。
经过生产上量检验,作为基础设施的容器网络,未来会像 5G 一样,让公司业务 All in AI 底气更足,步子更稳,走的更远。
更多产品和技术文章,敬请关注👆
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn
客服电话:4000052360















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









