






一、P2P Store介绍
P2P Store 是在 Transfer Engine 基础上封装的一个用于内存数据远程读写的应用。内存的数据块用全局唯一的 key 标识,数据提供者将数据内存块注册到本地内存,并将 key 注册到 etcd 中,以便于其它数据获取者进行数据发现。数据获取者可以从etcd中list所有注册的数据 key(从原理上来说,也可以进行监听),如果数据获取者发现感兴趣的数据key被注册到系统中,则可以通过 P2P Store 提供的 replica 接口将 key 对应的远端数据读取到本地内存。总体来说,P2P Store 系统中的节点可以读写系统中注册的任意 key 所对应的内存数据,就像操作本地内存数据一样,其底层由 transfer engine 支持。
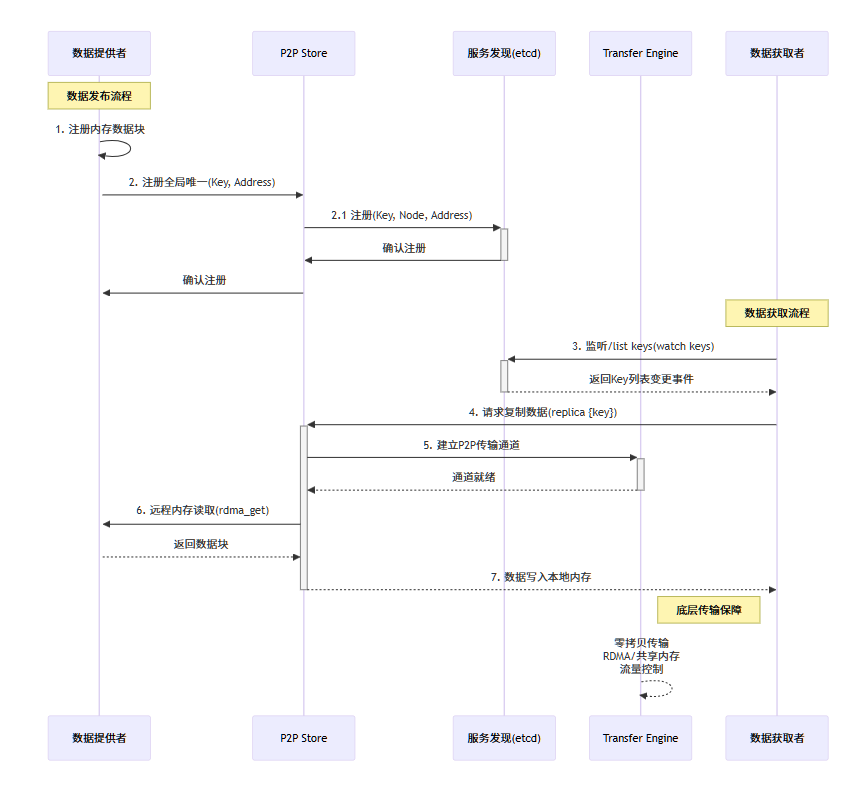
目前 p2p store 仅支持内存数据的透明传输,如果需要进行文件的传输,需要在其基础上,将文件映射到机器内存。p2p-store-example 展示了单个模型文件的分发流程:
1. trainer 节点将自身训练的模型数据注册到 p2p store
// 文件位置:src/example/p2p-store-example.gofunc doTrainer(ctx context.Context, store *p2pstore.P2PStore, name string) { // 将需要传输的文件映射进内存 addr, err := syscall.Mmap(-1, 0, fileSize, syscall.PROT_READ|syscall.PROT_WRITE, syscall.MAP_ANON|syscall.MAP_PRIVATE) // // ... // startTimestamp := time.Now() addrList := []uintptr{uintptr(unsafe.Pointer(&addr[0]))} sizeList := []uint64{uint64(fileSize)} const MAX_SHARD_SIZE uint64 = 64 * 1024 * 1024 const MEMORY_LOCATION string = "cpu:0" // 将内存块地址注册到 p2p store,key 为传输的 string name err = store.Register(ctx, name, addrList, sizeList, MAX_SHARD_SIZE, MEMORY_LOCATION, true) // // ... //2. inference 节点查看当前可用的模型文件,并通过p2p store 进行数据读取
// 文件位置:src/example/p2p-store-example.gofunc doInferencer(ctx context.Context, store *p2pstore.P2PStore, name string) { // 申请内存以存储读取的数据 addr, err := syscall.Mmap(-1, 0, fileSize, syscall.PROT_READ|syscall.PROT_WRITE, syscall.MAP_ANON|syscall.MAP_PRIVATE) // // ... // addrList := []uintptr{uintptr(unsafe.Pointer(&addr[0]))} sizeList := []uint64{uint64(fileSize)} // 读取string name 对应的数据副本到申请的本地内存地址 err = store.GetReplica(ctx, name, addrList, sizeList) // // ... //模型数据存储与加载场景应用
模型数据由训练服务生成后,供推理服务加载并投入使用。模型数据通常由一组文件构成,而推理服务针对模型的加载方式主要分为两类:多机推理模式与单机推理模式。在多机推理模式下,推理服务架构由多个节点协同组成,共同完成推理任务;单机推理模式则是仅依靠一台配备 GPU 的机器独立对外提供推理服务。
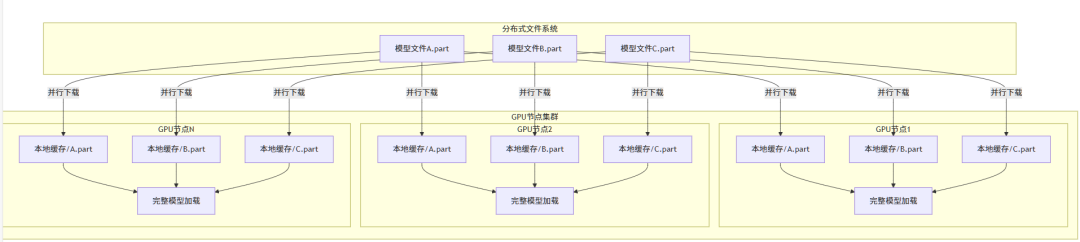
现阶段,几乎所有的推理框架在应对多机推理场景时,每个推理节点实际上仅需处理模型数据中的一部分,但这些数据的划分并非依照文件粒度来进行。这就导致每个推理节点都不得不将全量的模型文件先行下载至本地,再借助文件系统接口从中提取所需的数据。如此一来,不难发现,随着推理节点数量规模的逐步扩大,数据的读放大问题愈发凸显。整个过程整理示意如下图所示。
根据P2P Store所提供的能力,如果我们希望将其应用于当前推理的模型加载过程中,则需要在推理框架层面进行适配或者文件系统层面进行适配。推理服务的每个节点作为p2p store 系统的一部分,从中心存储中加载取部分训练数据到本地,同时向其它节点提供本地已经加载数据的读取服务。整体如下图所示。
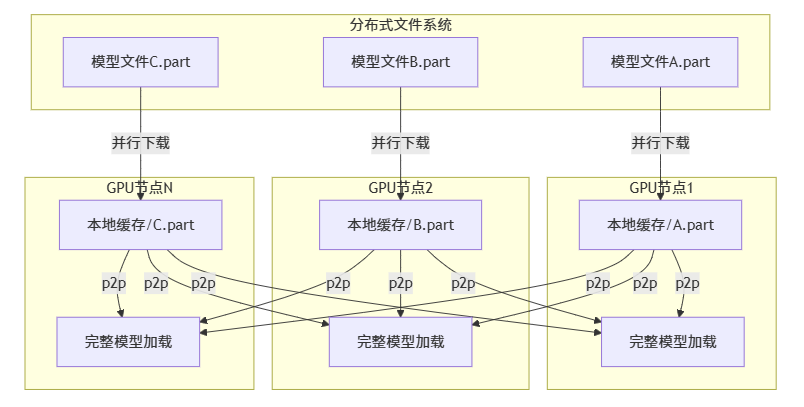
要达到上图效果,一个可行的方案是:
在P2P store基础上封装简单的文件读写接口,拦截GPU节点上模型文件的读写请求,使其通过P2P store 进行文件数据读取
二、Transfer Engine
transfer engine 是一个高速数据传输框架,在实现中以zero copy为基础,以lib库的形式对外提供高性能的数据传输服务。它能在进程、线程或网络节点间实现高效、可靠且无锁的数据传输。其核心由两个抽象层组成:segment 和 batch transfer。
1.核心特性
(1). 高性能与低延迟
采用无锁算法最大限度减少线程竞争。
零拷贝传输,降低内存开销。
针对高吞吐场景优化,支持批量处理。
(2). 多传输协议支持
共享内存(IPC) —— 同一台机器上进程间的超高速通信。
TCP/UDP 网络传输 —— 适用于跨机器分布式系统。
RDMA(远程直接内存访问) —— 为高频交易(HFT)提供超低延迟网络支持。
(3). 线程与进程安全
单生产者单消费者(SPSC) 队列,实现最高性能。
多生产者多消费者(MPMC) 变体,锁竞争极低。
支持无等待(wait-free)或阻塞模式,适应不同场景。
(4). 实时数据流处理
采用环形缓冲区(类似之前的示例),支持连续数据流传输。
背压控制机制,避免快生产者/慢消费者的数据堆积问题。
(5). 跨平台与多语言支持
核心使用 C++ 编写(保证性能),对外提供了go、rust、c++等lib。
2. 应用场景
根据transfer engine的核心特性,其可能在以下场景中发挥巨大作用:
(1)高频交易(HFT)
(2)大数据与流处理
(3)大模型数据分发
3. 核心原理
transfer engine 核心由 segment 和 batch transfer 两部分组成。
Segment 表示一个连续的地址空间,该空间可进行远程读写操作。它既可以是由动态随机存取存储器(DRAM)或视频随机存取存储器(VRAM)提供的非持久性存储,即随机存取存储器段(RAM 段);也可以是由 NVMe over Fabrics(NVMeof)提供的持久性存储,即 NVMeof 段。
BatchTransfer 对操作请求进行封装,专门负责在一个段内的一组非连续数据空间与另一组段内的相应空间之间同步数据,支持双向的读 / 写操作,因此其作用类似于异步且更灵活的全散 / 全聚操作。
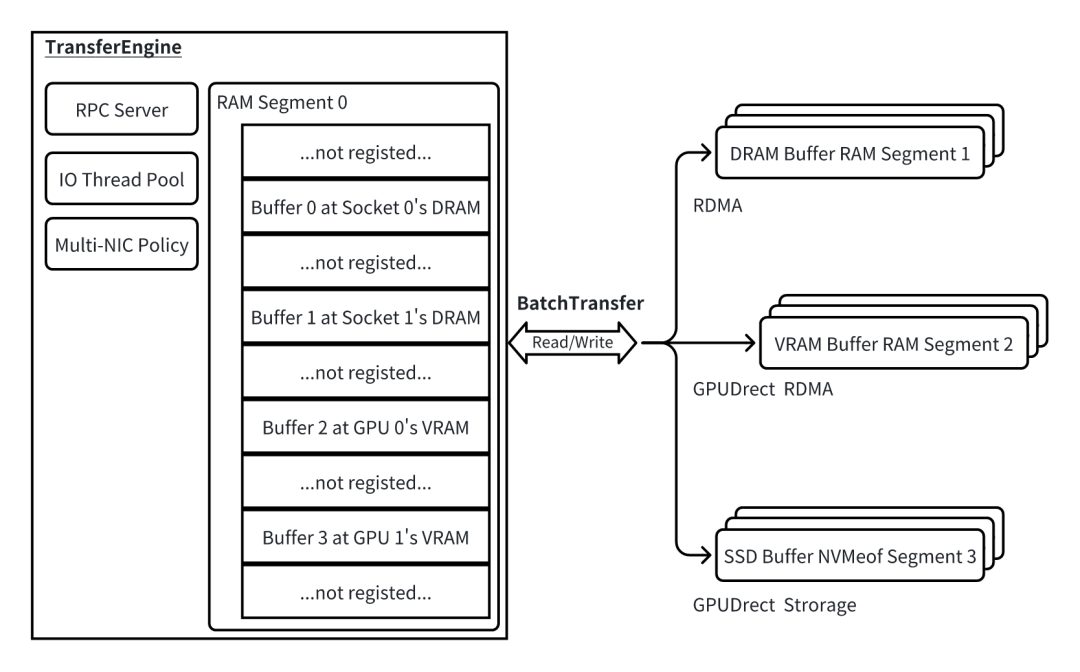
如上图所示,每个特定的客户端对应一个传输引擎,该传输引擎不仅包含一个 RAM 段,还集成了跨多个线程和网卡的高速传输管理功能。原则上,该 RAM 段对应此传输引擎的整个虚拟地址空间,但实际上,仅其部分区域(即缓冲区)会被注册用于(GPUDirect)远程直接内存访问(RDMA)的读 / 写操作。每个缓冲区可以拥有独立的权限(对应于 RDMA 的远程密钥等)和网卡亲和性(例如,不同类型内存优先使用的网卡)。
Transfer Engine 通过传输引擎类(位于 mooncake - transfer - engine/include/transfer_engine.h)提供接口,其中针对不同后端的具体数据传输功能由传输类实现,目前支持 TCP、RDMA和 NVMeoF传输。
4. 性能测试
我们使用transfer engine自带的exmaple程序进行了测试,测试结果显示,在RDMA环境下transfer engine数据传输速度基本可以打满网卡(测试环境配置 200Gpbs 网卡)。而TCP网络下,传输速度仅 1 ~ 2GiB/s。分析其原理,可能的原因是其用户与内核态之间数据拷贝导致的。同时,看上去应用并未对TCP场景进行特殊优化。
RDMA网络 | TCP网络 | |
|---|---|---|
传输速度 | 19.2GiB/s | ~2GiB/s |
三、总结
Transfer Engine 是一款优秀的高性能内存数据传输框架,基于 Transfer Engine 开发的 P2P Store 系统则将数据封装为 Key-Value 形式,便于使用者从系统中获取任意 key 的数据。
总体上,P2P Store 只是一个比较原始的高性能 P2P 应用模型,还需要更多的功能支持才能应用于特定的业务场景,比如推理服务的模型加载。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









