







文章目录
前言
由于HashMap不是线程安全的,在多线程环境下可能会发生错乱,死循环等问题,而HashTable虽然是线程安全的,但是是直接在方法上添加Synchronized来保证线程安全的,在高并发的情况下效率十分低下,因为读写也是互斥的。而ConcurrentHashMap是HashMap的线程安全版本,由于内部结构设计的优化,导致相比HashTable效率各方面都有极大的提高
1、ConcurrentHashMap1.7实现原理分析
1.1、数据结构实现
在1.7版本的通过锁分段来提升并发度,把整个哈希表分成了多个段(segment),每个段可以并发进行读写,从下图可以看出segment数组的长度就是并发度,表示最多可以存在多少线程同时操作ConcurrentHashMap,默认segment数组长度是16,每个segment中包含HashEntry数组,是真正存放键值的地方,如果存在hash冲突也会采用拉链法解决。
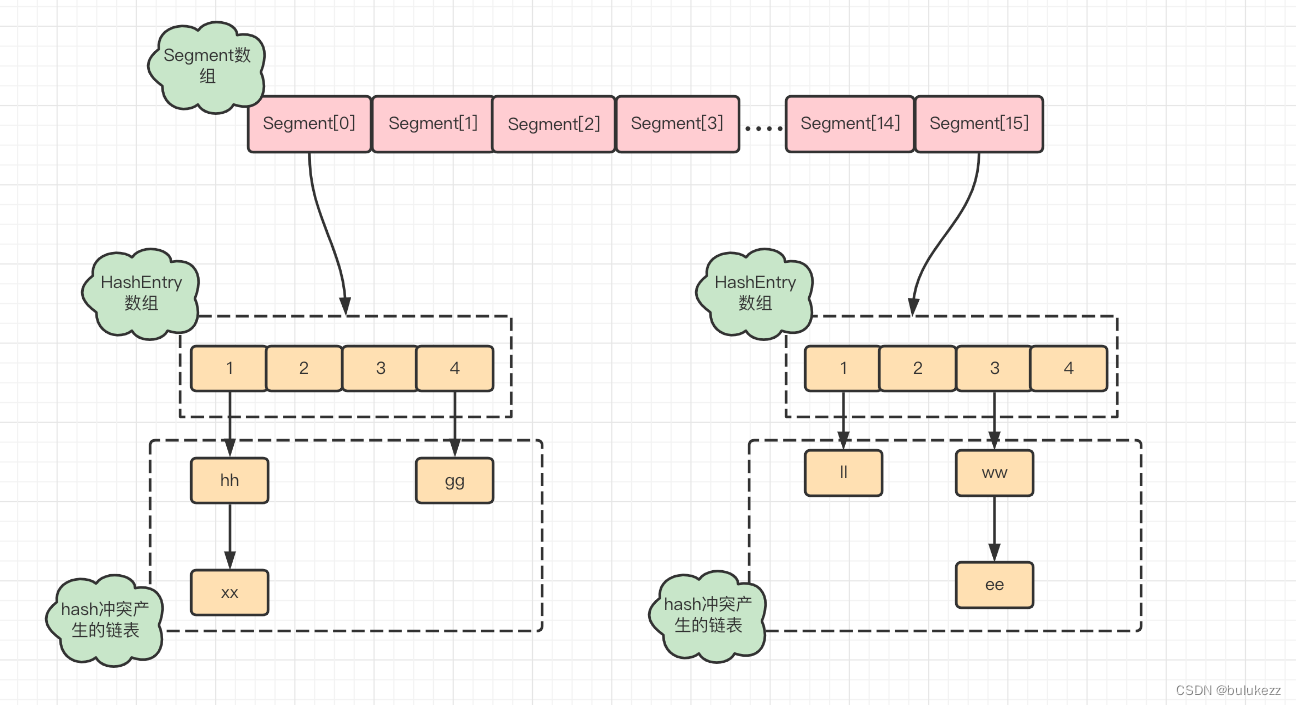
1.2、常用属性和内部类解析
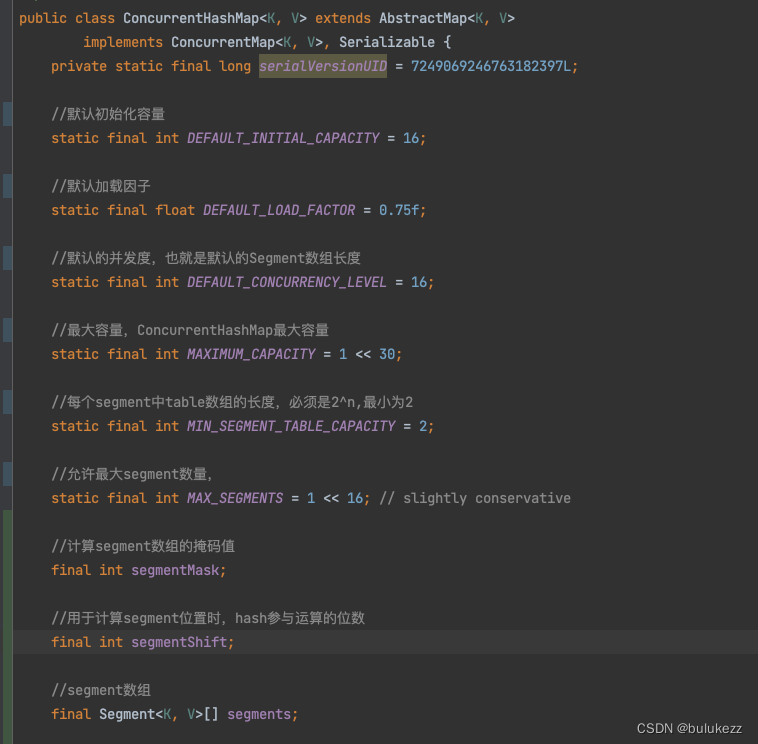
这里有几个比较关键的属性:
- 初始化容量为16,加载因为也是0.75
- Segment数组的长度默认是16,也就相当于并发度是16。
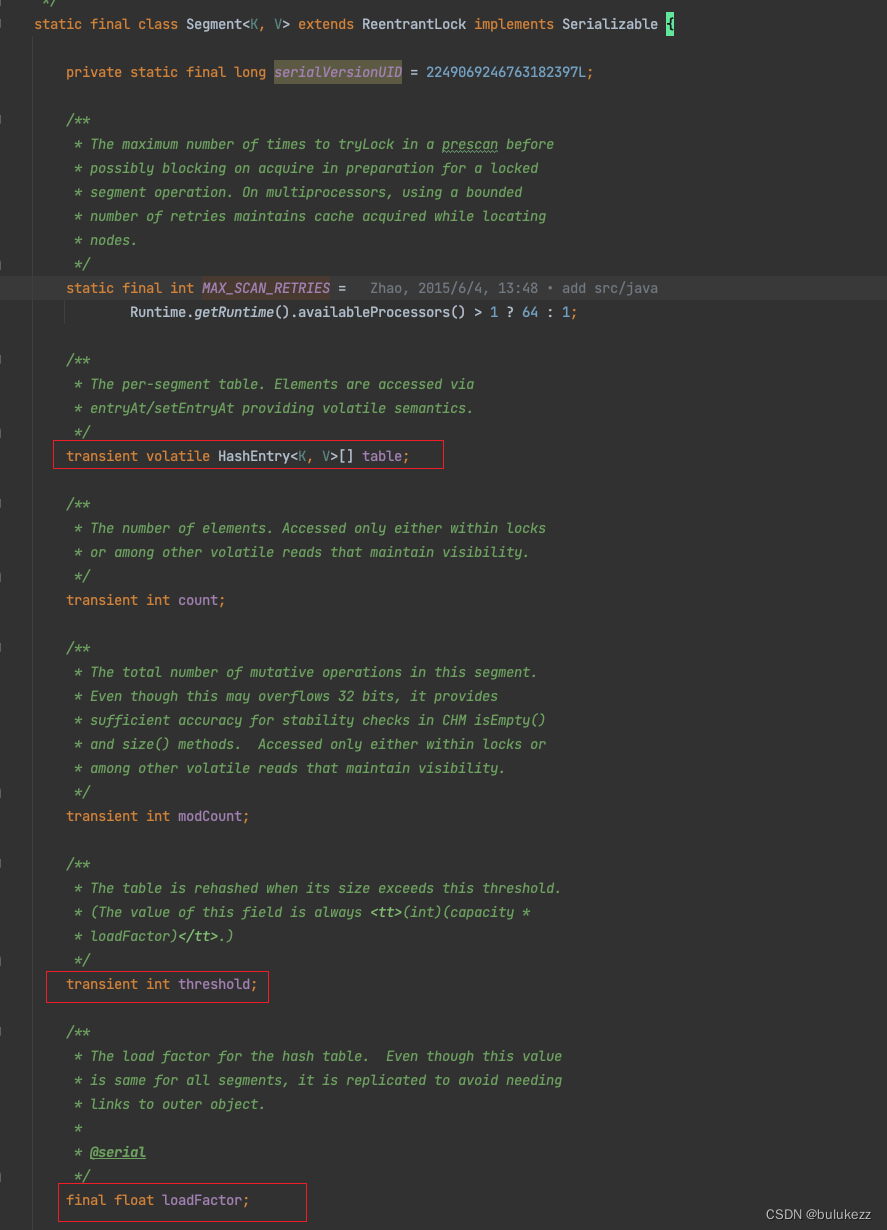
Segment内部类其实持有一个HashEntry的数组,其中也会有HashEntry数组的加载因子和扩容阈值,HashEntry就是真正存储数据的实体,包含key,value等相关信息。
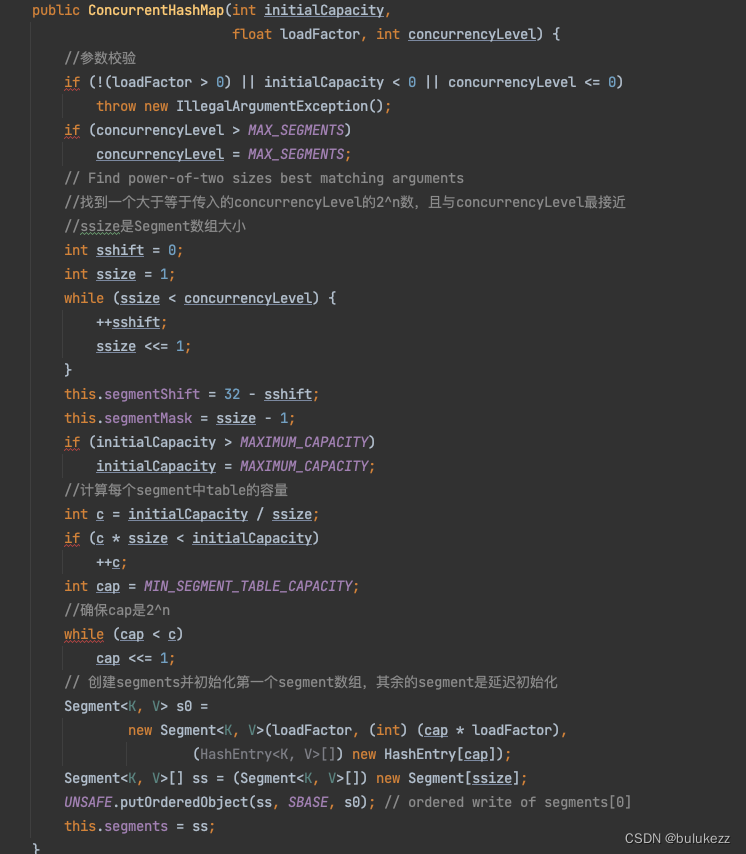
1.3、构造方法解析
这里直接看参数最全的构造方法,步骤如下:
- 校验参数,不合法抛出异常
- 找到大于等于concurrencyLevel(并发度)的2^n的一个数,作为segment数组的长度
- 计算每个segment中table数组的容量(总容量大小/segment数组长度),把计算出来的容量也适配成2^n次方。
- 创建segments数组,并初始化第一个segment数组。
1.4、ConcurrentHashMap#put方法解析
- 先对value做判空,这里发现是不支持value为空的。
- 根据key计算出一个hash值
- 通过hash值定位对应segment相应的下标
- 判断对应下标的segment有没有初始化,没有则进行初始化(lazyLoading)
- 调用segment的put方法往table中添加值
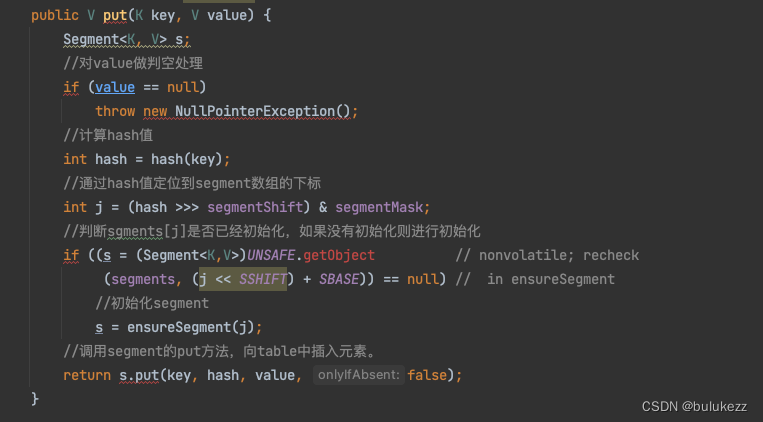
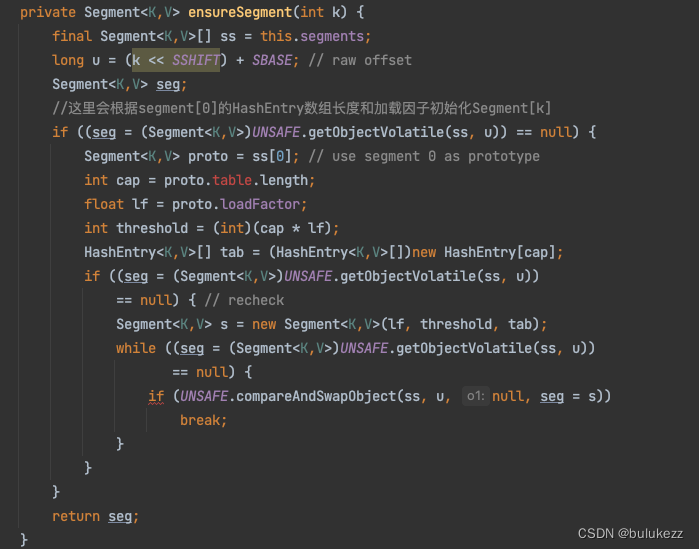
1.4.1、ConcurrentHashMap#ensureSegment方法解析
- 延迟初始化segment,因为之前创建的时候已经初始化了segment[0],所以这里按照segment[0]的配置信息初始化当前segment信息
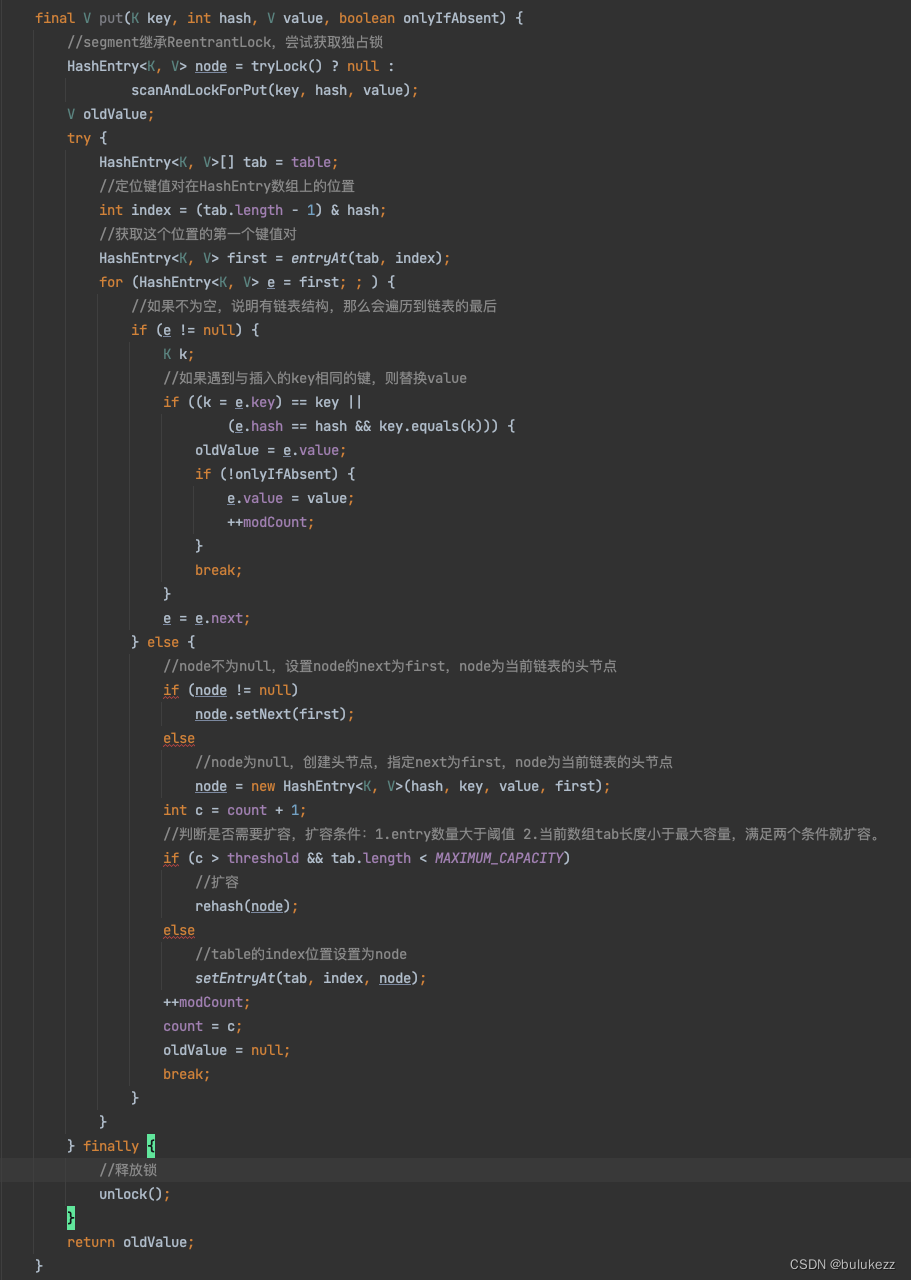
1.4.2、Segment#put方法解析
- 首先去抢占锁,抢占到锁继续后续流程。
- 定位到键值对在HashEntry数组的哪个桶
- 获取这个slot中第一个元素,如果不为空,则说明之前已经有值了,则遍历到链表的最后然后插入,如果为空,说明当前slot没有元素,则创建头节点插入。
- 插入完元素,判断是否已经到扩容阈值并且table长度是小于最大容量,满足则进行rehash
- 释放锁。
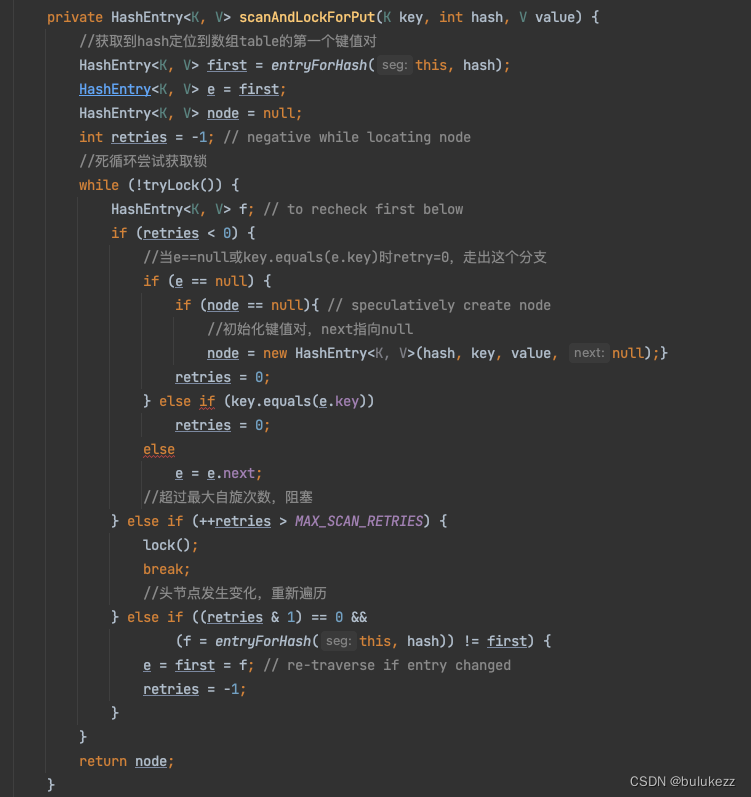
1.4.3、Segment#scanAndLockForPut方法解析
当调用tryLock尝试获取锁没有获取到的时候会进入这个方法,方法流程如下:
- 获取下标对应的第一个元素(为了防止后续发生头节点变化)
- 死循环尝试获取锁(确保从这个方法出去一定拿到独占锁)
- 如果判断当前头节点已经为null了,说明当前slot没有元素了,则退出循环
- 如果超过最大自旋次数,则进行阻塞获取锁(说明当前竞争比较厉害,自旋浪费cpu也拿不到锁)
- 判断头节点是否发生变化,发生变化重新赋值,并且自旋次数–。
1.4.4、ConcurrentHashMap#rehash方法解析
1.计算扩容后的数组的阈值和数组长度和掩码,然后创建一个新数组
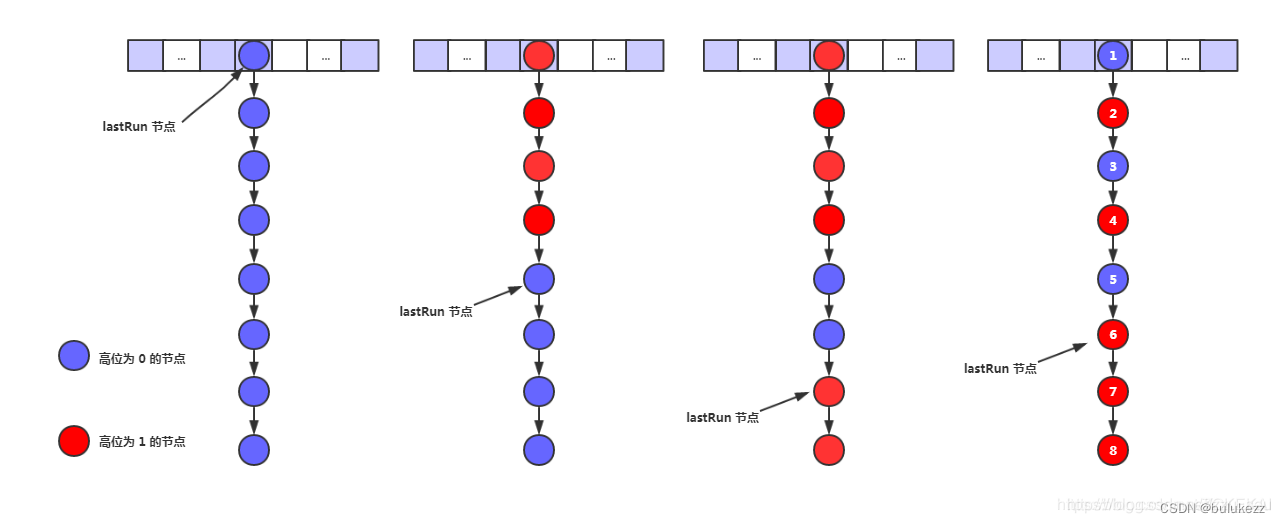
2. 遍历旧的数组,判断slot中的元素如果只有一个说明没有hash冲突,那么直接重新rehash到新节点,如果存在冲突,则遍历slot中的链表,这个做了个优化,找到了一个lastRun节点,这个节点之后的元素都是在原来位置,所以我们可以对lastRun及之后的元素进行整体迁移,然后逐个重新迁移只需要针对lastRun之前的元素即可。
3. 重新把segment的table指向扩容后的table。
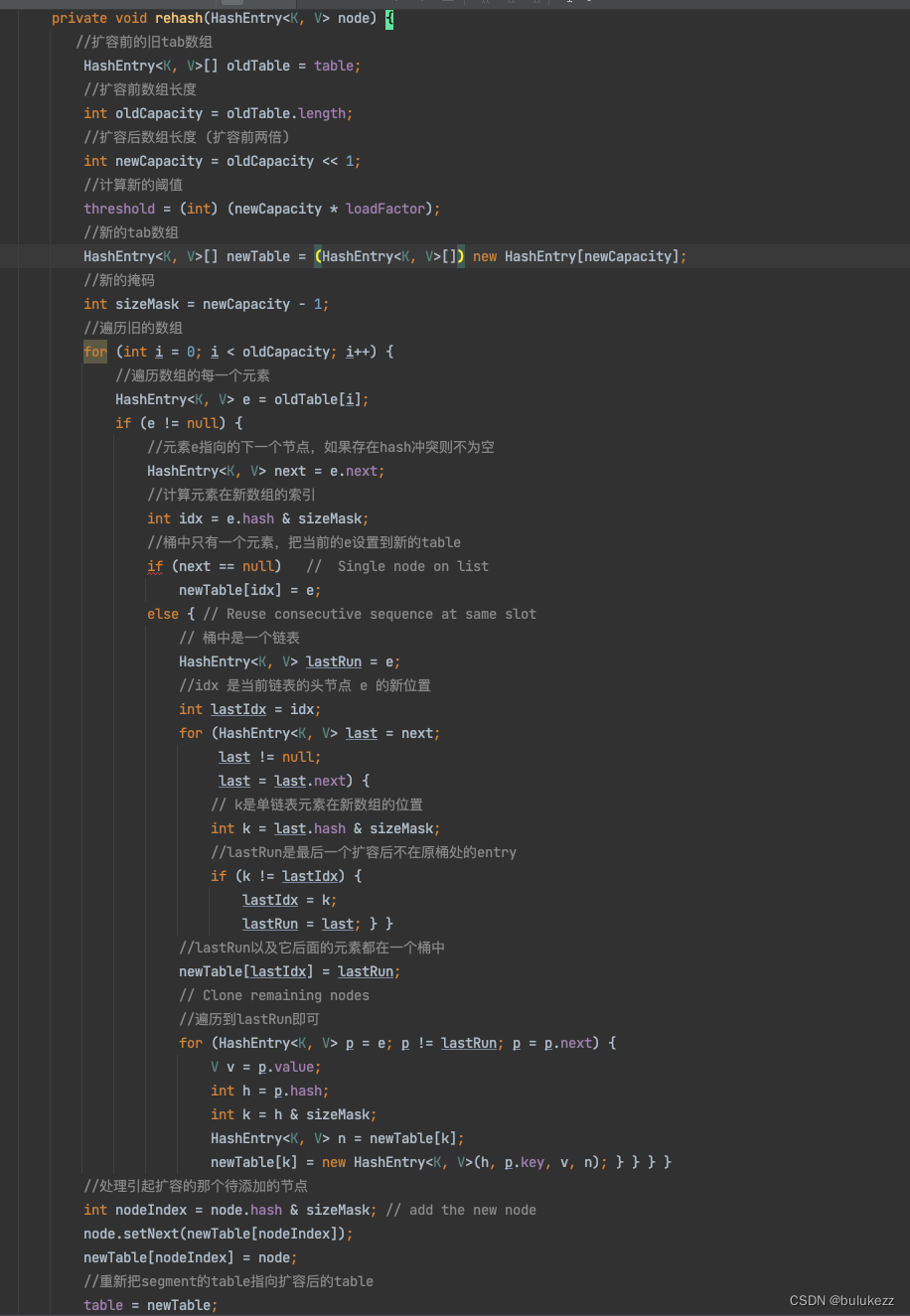
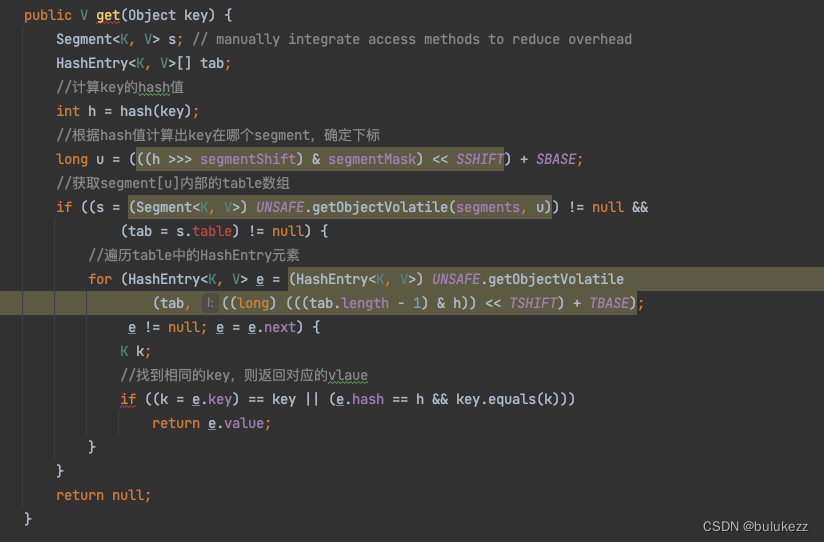
1.5、ConcurrentHashMap#get方法解析
- 根据key计算出hash值
- 根据hash值定位到对应的segment
- 获取segment对应的table数组,遍历获取到key对应的value返回。
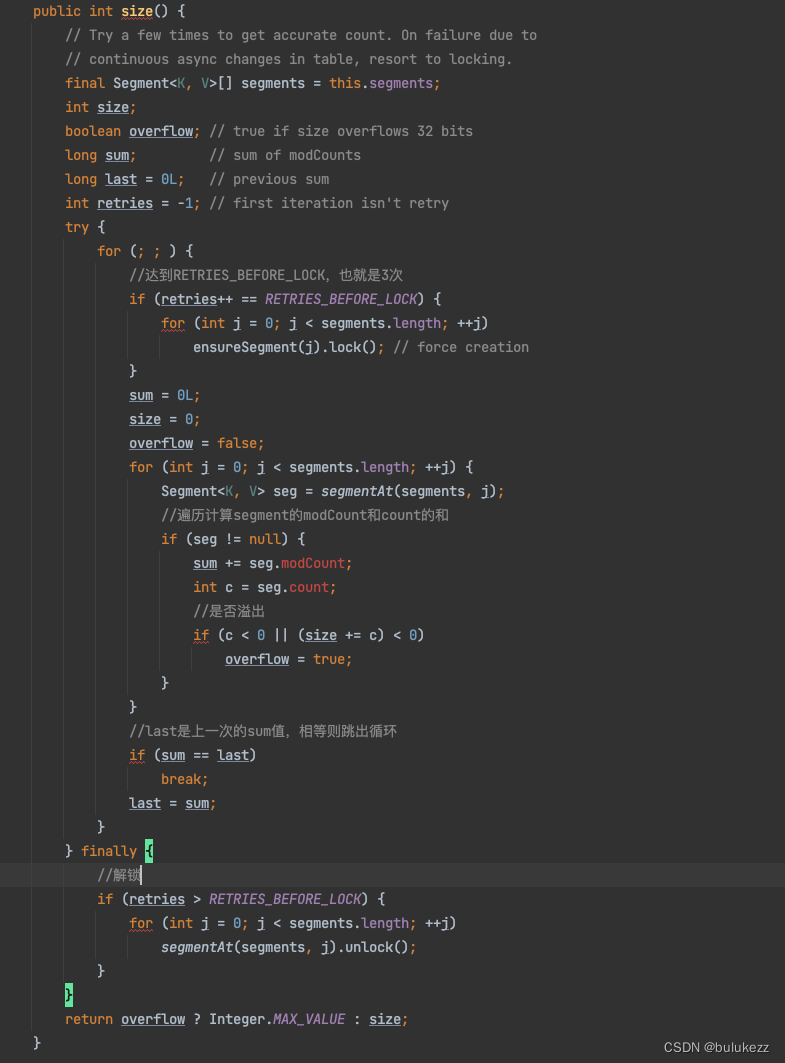
1.6、ConcurrentHashMap#size方法解析
这里统计ConcurrentHashMap中的元素个数比较有意思,这里是没有进行加锁的,那没有加锁,统计过程中可能有其他线程增加或者删除元素,那么就会造成计数不一致,如果加锁又会造成读写效率的降低,这里ConcurrentHashMap会无锁遍历三次,把所有的segment的modCount加到sum里面,如果和前一次遍历的结果相比没有改变说明这两次遍历没有其他线程修改,则返回segment的count的和,如果每次和上次统计都不一致则加锁进行同步。
总结
这里分段锁的实现很值得学习,通过分段的方式扩大并发度,从而提升读写效率,而且这里统计的时候也是没有直接加锁,而是采用了一种折中的方案,先进行无锁遍历,来判断两次统计中否没有线程修改,如果不一致才进行加锁。
2、ConcurrentHashMap1.8实现原理分析
2.1、数据结构实现
ConcurrentHashMap1.8和HashMap一样都是采用拉链法处理hash冲突,且为了防止链表长度过长影响查询效率,所以当链表长度超过阈值,就会将其转成红黑树。采用数组+链表+红黑树的结构
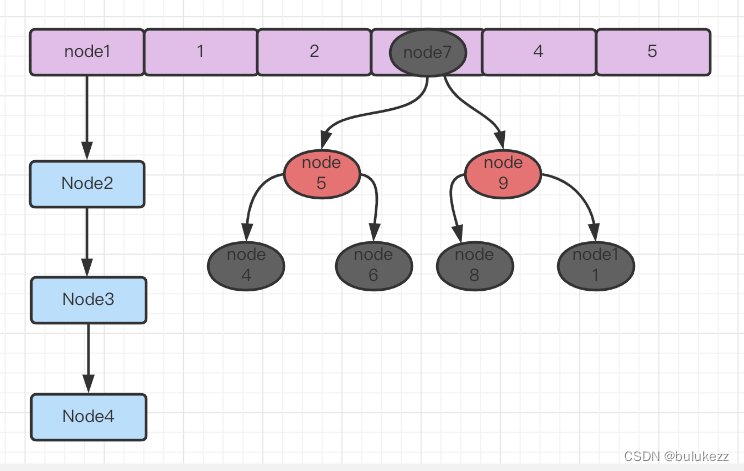
2.2、常用属性解析
table:存放元素的数组容器
nextTable:扩容时生成的数组,容量为之前的2倍
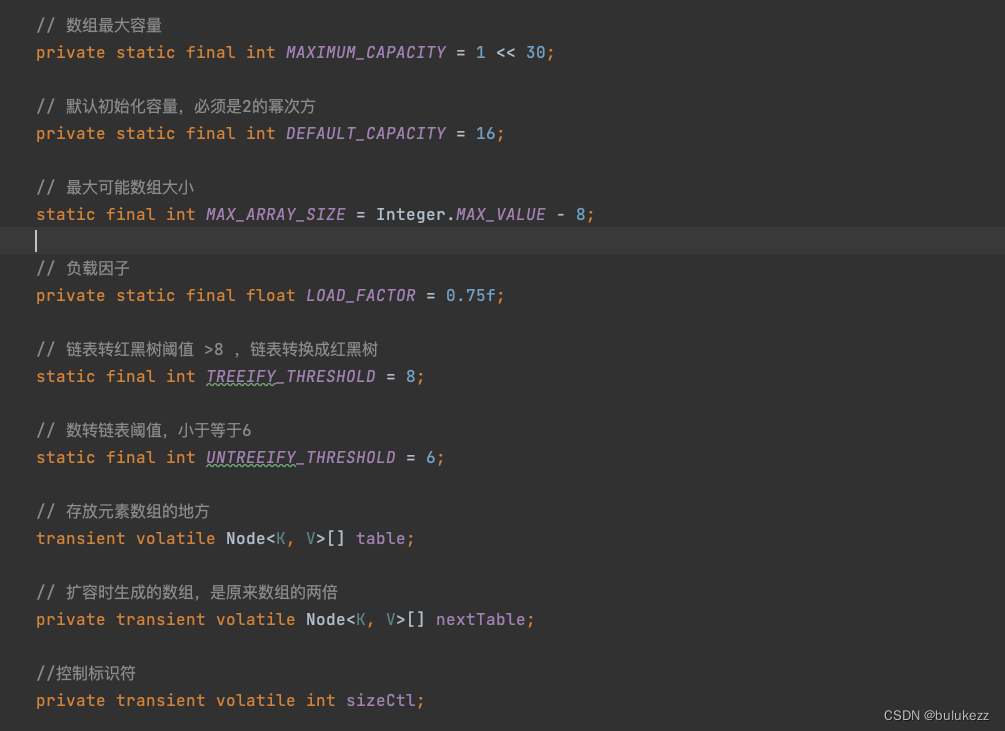
sizeCtl:多个线程的共享变量,操作的控制标识符:
- -1代表正在初始化
- -(1+nThreads),表示有n个线程正在一起扩容
- 0代表rehash还没有被初始化,默认值
- 大于0表示下一次进行扩容的容量大小
2.3、构造方法解析
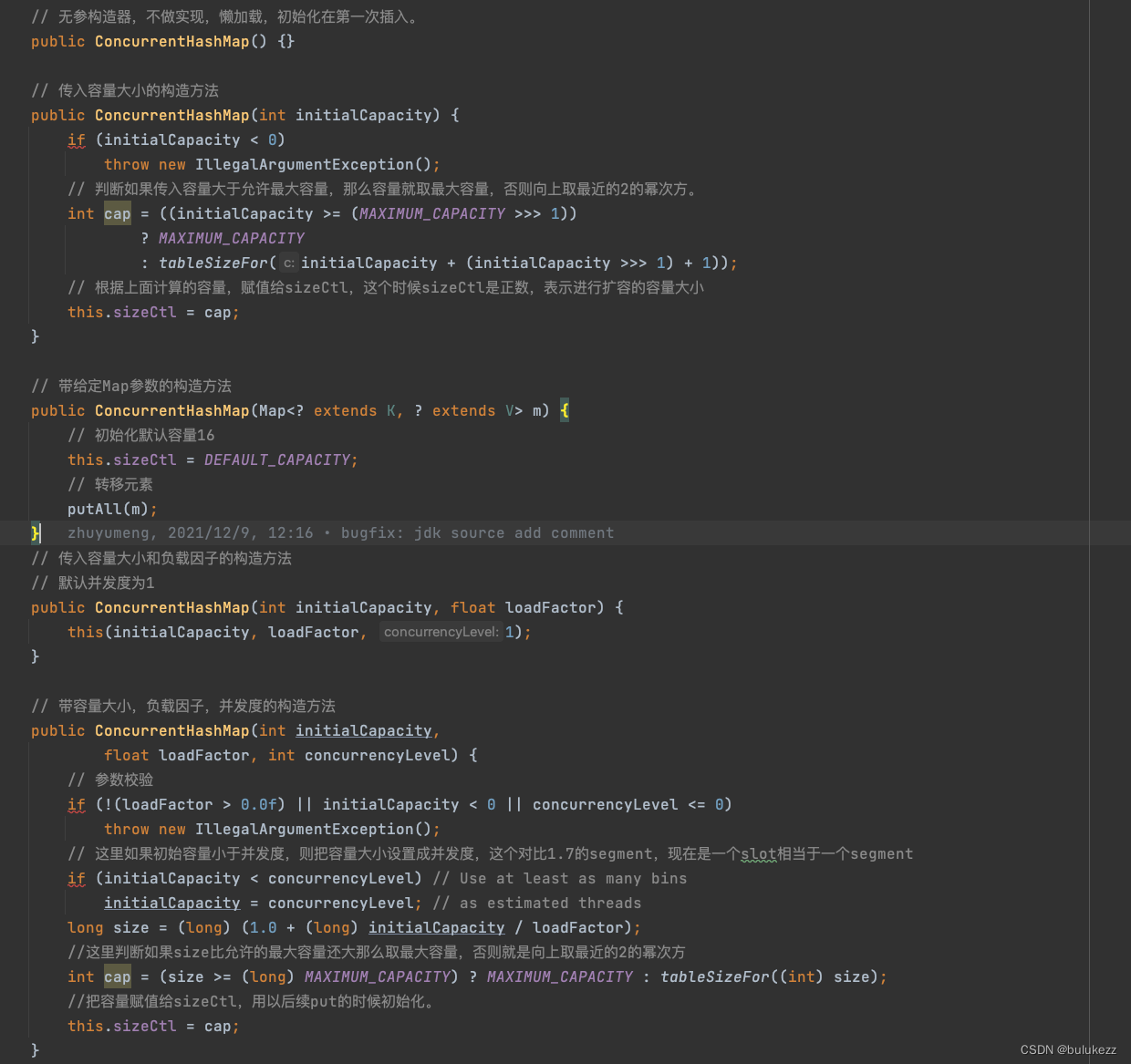
这里我们只分析参数最全的构造方法:
- 首先进行参数校验,不合法抛出异常
- 判断容量是否小于并发度,小于并发度则把并发度复制给容量,因为数组大小就对应并发度的大小,对应1.7版本的segment
- 对容量做下判断,如果大于最大容量那么取最大容量,否则向上取最近的2的幂次方。
- 把容量赋值给sizeCtl,用以在put的时候进行初始化。
2.4、ConcurrentHashMap#put方法解析
1.put方法会调用putVal方法
2. putVal方法流程如下:
- 校验key和value是否为空,这里可以发现并发map不允许key和vlaue为空
- 计算出来hash值
- 循环尝试插入
- 在循环中,如果数组还没有初始化,则进行初始化数组
- 在循环中,根据hash计算出来对应数组的slot,判断如果slot没有元素,则直接使用CAS把数据插入
- 在循环中,如果判断slot的头节点的元素hash地址为-1(ForwardingNode节点),则表示当前正在进行扩容,则当前线程会去协助扩容
- 在循环中,如果上面情况都没有命中,我们就会进入链表中,先对头节点进行加锁,保证当前slot元素的修改是互斥的,然后遍历链表,做元素的添加或覆盖。(有红黑树或链表两种情况)
- 添加完成后,则判断是否需要树化(条件:链表长度超过8,数组长度超过64)
- 调用addCount对键值对数量累加,并检查是否需要扩容,需要扩容会执行扩容逻辑。
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key和value都不能为null
if (key == null || value == null) throw new NullPointerException();
// 计算hash值
int hash = spread(key.hashCode());
// 要插入的元素所在筒的元素个数
int binCount = 0;
// 死循环,结合CAS使用(如果CAS失败,则会重新取整个桶进行下面的流程)
for (Node<K, V>[] tab = table;;) {
Node<K, V> f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 如果桶为初始化或者桶个数为0,则初始化桶
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果要插入的元素所在的桶还没有元素,则把这个元素插入到这个桶中,这里使用cas
if (casTabAt(tab, i, null,
new Node<K, V>(hash, key, value, null)))
break; // no lock when adding to empty bin
} else if ((fh = f.hash) == MOVED)
// 如果要插入的元素所在的桶的第一个元素的hash是MOVE,则当前线程一起帮忙进行迁移元素
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 如果这个桶不为空切不在迁移元素,则锁住这个桶(分段锁)
// 并查找要插入的元素是否在这个桶中
// 存在,则替换值(onlyIfAbsent=false)
// 不存在,则插入到链表结尾或者插入到树中
synchronized (f) {
// 再次检测第一个元素是否有变化,如果有变化则进入下一次循环,从头开始
if (tabAt(tab, i) == f) {
// 如果第一个元素的hash值大于等于0(说明不实在迁移,也不是等于树)
if (fh >= 0) {
// 桶中元素个数赋值为1
binCount = 1;
// 遍历整个桶,每次结束binCount++
for (Node<K, V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// 如果找到了这个元素,并赋值了新值(onlyIfAbsent=false)
// 并退出循环
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K, V> pred = e;
if ((e = e.next) == null) {
// 如果到链表尾部还没有找到元素,就把他插入到链表结尾并退出循环
pred.next = new Node<K, V>(hash, key,
value, null);
break;
}
}
} else if (f instanceof TreeBin) {
// 如果第一个元素是数节点
Node<K, V> p;
// 桶中元素个数赋值为2
binCount = 2;
// 调用红黑树的插入方法插入元素
// 如果成功插入则返回null
// 否则返回寻找到的节点
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果binCount不为0,说明成功插入了元素或者寻找到了元素
if (binCount != 0) {
// 因为链表元素个数已经达到了8,则尝试树化
// 因为上面把元素插入到树中时,binCOunt只赋值了2,并没有计算整个树中元素的个数
// 所以不会重复树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// 如果要插入的元素已经存在,则返回旧值
if (oldVal != null)
return oldVal;
// 退出外层大循环,流程结束
break;
}
}
}
// 成功插入元素,元素个数加1(是否要扩容在这个里面)
addCount(1L, binCount);
// 成功插入元素返回null
return null;
}
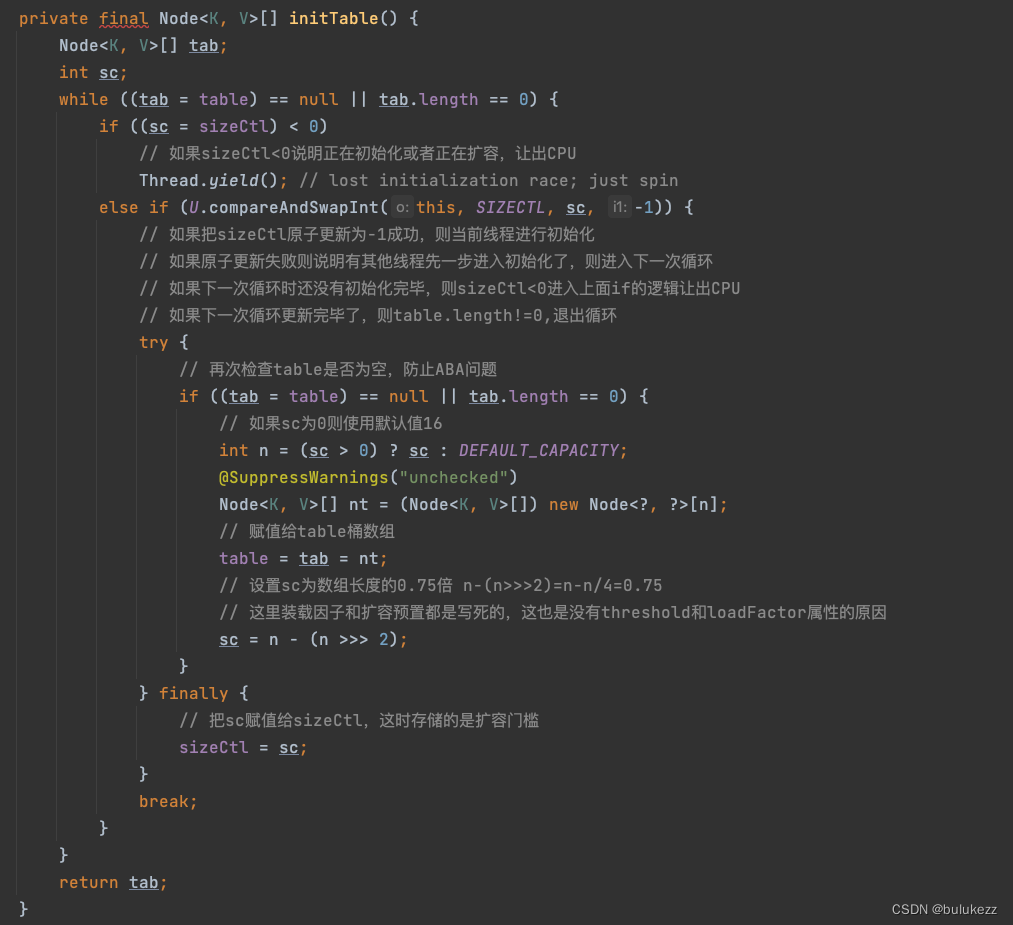
2.4.1、ConcurrentHashMap#initTable方法(初始化)
这里初始化是没有加锁的,通过CAS修改sizeCtl为-1来达到只有一个线程执行临界区代码,具体流程如下:
- 如果数组为空则进入循环
- sizeCtl<0,说明有其他线程在初始化或者扩容,那么就调用Thread.yield()让出一次cpu,等下次抢到的时候再循环潘敦啊
- sizeCtl不小于0,则使用CAS修改sizeCtl为-1,表示当前线程正在进行初始化,修改成功则会进行初始化逻辑。
- 判断sc的值(构造方法中设置的容量),如果sc大于0,则容量大小赋值为sc,如果小于等于0,则是无参构造方法的初始化逻辑,直接给默认值16,根据容量初始化table数组。
- 计算下次扩容的阈值保存到sizeCtl中。
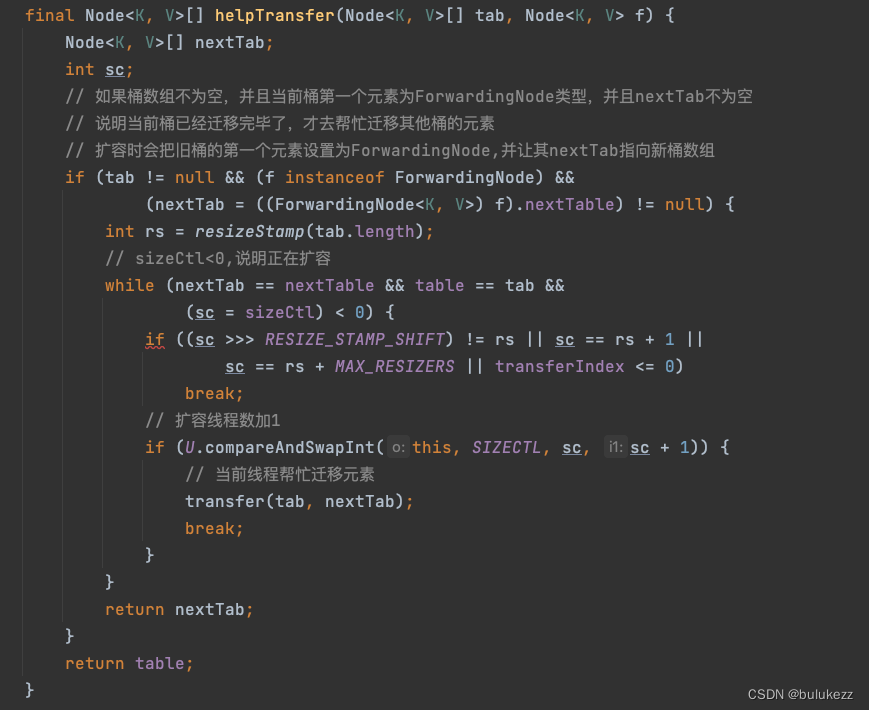
2.4.2、ConcurrentHashMap#helpTransfer方法(协助扩容)
这里是线程添加元素时发现正在扩容并且当前元素的桶已经迁移完成了,则协助迁移其他桶的元素。
- 修改sizeCtl累加1,现在表示扩容的线程数量
- 然后调用transfer协助扩容。
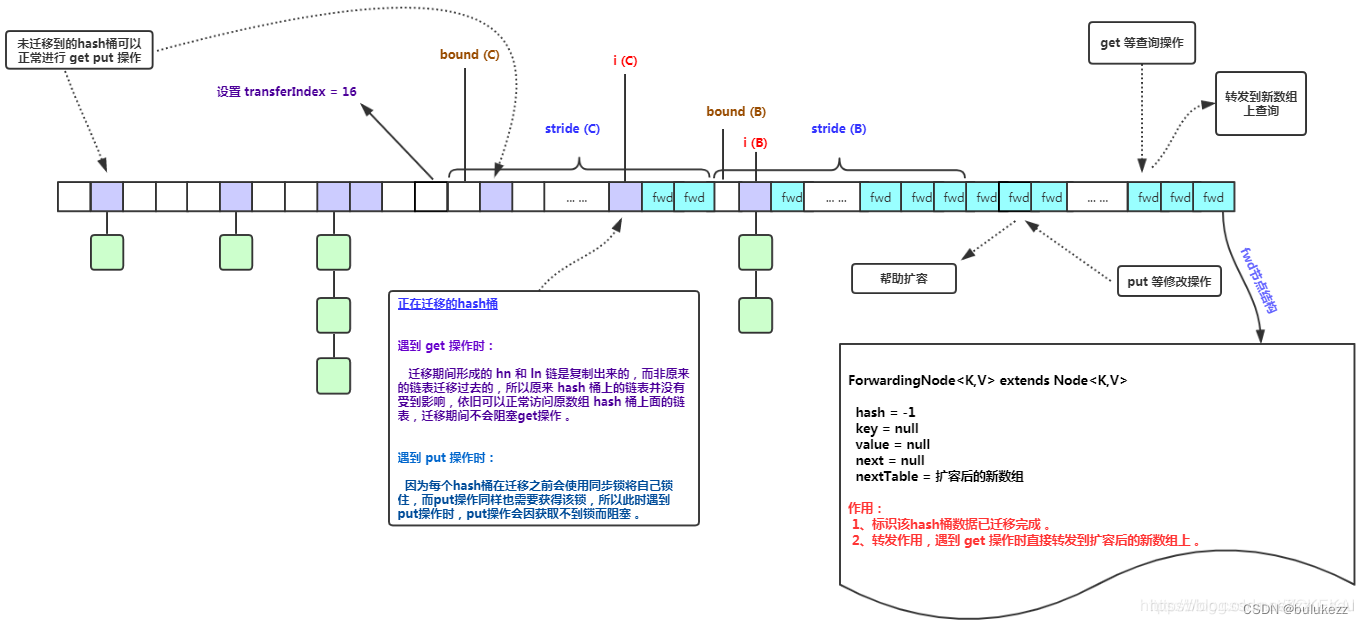
2.4.3、ConcurrentHashMap#transfer方法(扩容)
- 首先计算出来一个步长(迁移桶的数量), 如果cpu核数是1,则步长是1,否则是桶的数量除以cpu数量,如果每个线程负责的数量小于16的话则会强制分配16.
- 如果nextTab为空,说明当前线程是第一个,还没开始迁移,则新建一个新数组,容量为原来的两倍。
- 修改transferIndex变量,这个字段表示当前线程要迁移的桶区间,table[transferIndex-stride,transferIndex-1]
- 迁移元素从靠后的桶开始迁移,迁移完成的桶放置一个ForwardingNode类型的元素,表示该桶已经迁移完成了。
- 迁移时如果这个位置是Node节点(fh>=0),根据hash&n是否为0,把桶中的元素分成两个链表,高位链表和低位链表,低位链表存储在原来的位置,高位链表存储原来的位置+n的桶的位置,迁移的时候也会使用lstRun提升迁移速度,这个上面有分析过。
- 迁移的时候如果这个位置是TreeBin节点(fh<0)如果发现桶中节点是红黑树也会走红黑树的迁移逻辑。
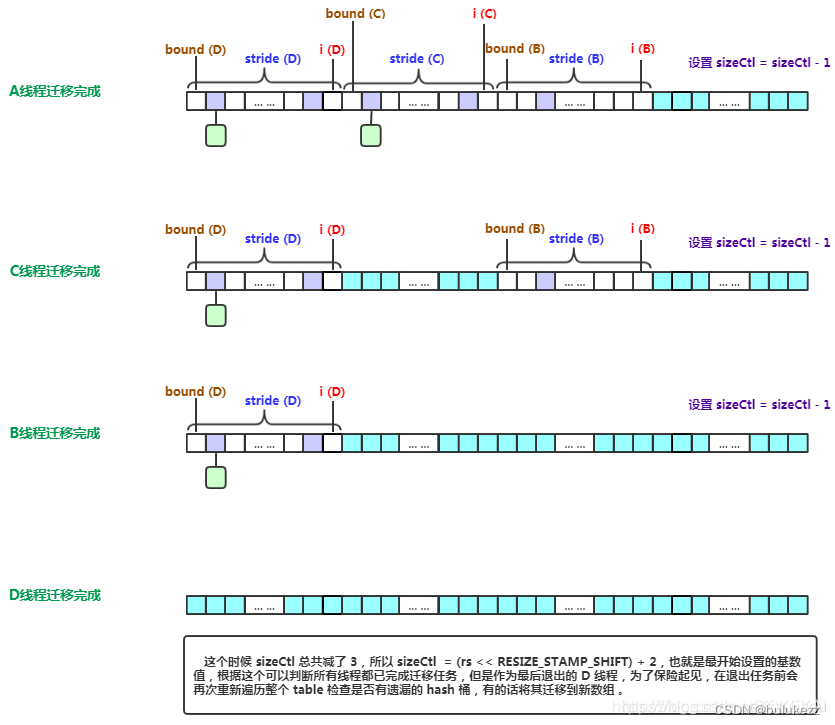
- 如果迁移完所有的节点并且发现自己是最后一个退出的线程,这时就可以将nextTable作为新的table,并更新sizeCtl为新容量的0.75倍,完成扩容
/**
* 数据转移和扩容.
* 每个调用tranfer的线程会对当前旧table中[transferIndex-stride, transferIndex-1]位置的结点进行迁移
*
* @param tab 旧table数组
* @param nextTab 新table数组
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//根据服务器CPU数量来决定每个线程负责的bucket桶数量,避免因为扩容的线程过多反而影响性能。
//如果CPU数量为1,则stride=1,否则将需要迁移的bucket数量(table大小)除以CPU数量,平分给
//各个线程,但是如果每个线程负责的bucket数量小于限制的最小是(16)的话,则强制给每个线程
//分配16个bucket数。
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//如果nextTable还未初始化,则初始化nextTable,这个初始化和iniTable初始化一样,只能由
//一个线程完成。
if (nextTab == null) { // nextTab为null,那么就初始化它
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n; //[transferIndex-stride, transferIndex-1]表示当前线程要进行数据迁移的桶区间
}
int nextn = nextTab.length;
// ForwardingNode结点,当旧table的某个桶中的所有结点都迁移完后,用该结点占据这个桶
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 标识一个桶的迁移工作是否完成,advance == true 表示可以进行下一个位置的迁移
boolean advance = true;
//循环的关键变量,最后一个数据迁移的线程将该值置为true,并进行本轮扩容的收尾工作
boolean finishing = false;
//下个循环是分配任务和控制当前线程的任务进度,这部分是transfer()的核心逻辑,描述了如何与其他线程协同工作。
for (int i = 0, bound = 0;;) { //进入循环
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
//i<0说明已经遍历完旧的数组tab;i>=n什么时候有可能呢?在下面看到i=n,所以目前i最大应该是n吧。
//i+n>=nextn,nextn=nextTab.length,所以如果满足i+n>=nextn说明已经扩容完成
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//利用CAS方法更新这个扩容阈值,在这里面sizectl值减一,说明新加入一个线程参与到扩容操作,参考sizeCtl的注释
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;//finishing和advance保证线程已经扩容完成了可以退出循环
i = n; //先退出,重新检查遍
}
}
else if ((f = tabAt(tab, i)) == null)//如果tab[i]为null,那么就把fwd插入到tab[i],表明这个节点已经处理过了
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)//那么如果f.hash=-1的话说明该节点为ForwardingNode,说明该节点已经处理过了
advance = true; // already processed
//迁移过程(对当前指向的bucket),这部分的逻辑与HashMap类似,拿旧数组的容量当做一
//个掩码,然后与节点的hash进行与&操作,可以得出该节点的新增有效位,如果新增有效位为
//0就放入一个链表A,如果为1就放入另一个链表B,链表A在新数组中的位置不变(跟在旧数
//组的索引一致),链表B在新数组中的位置为原索引加上旧数组容量。
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {// 桶的hash>=0,说明是链表迁移
/**
* 下面的过程会将旧桶中的链表分成两部分:ln链和hn链
* ln链会插入到新table的槽i中,hn链会插入到新table的槽i+n中
*/
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);//把已经替换的节点的旧tab的i的位置用fwd结点替换,fwd包含nextTab
advance = true;
}
//不是链表,那就是红黑树。下面红黑树基本和链表差不多
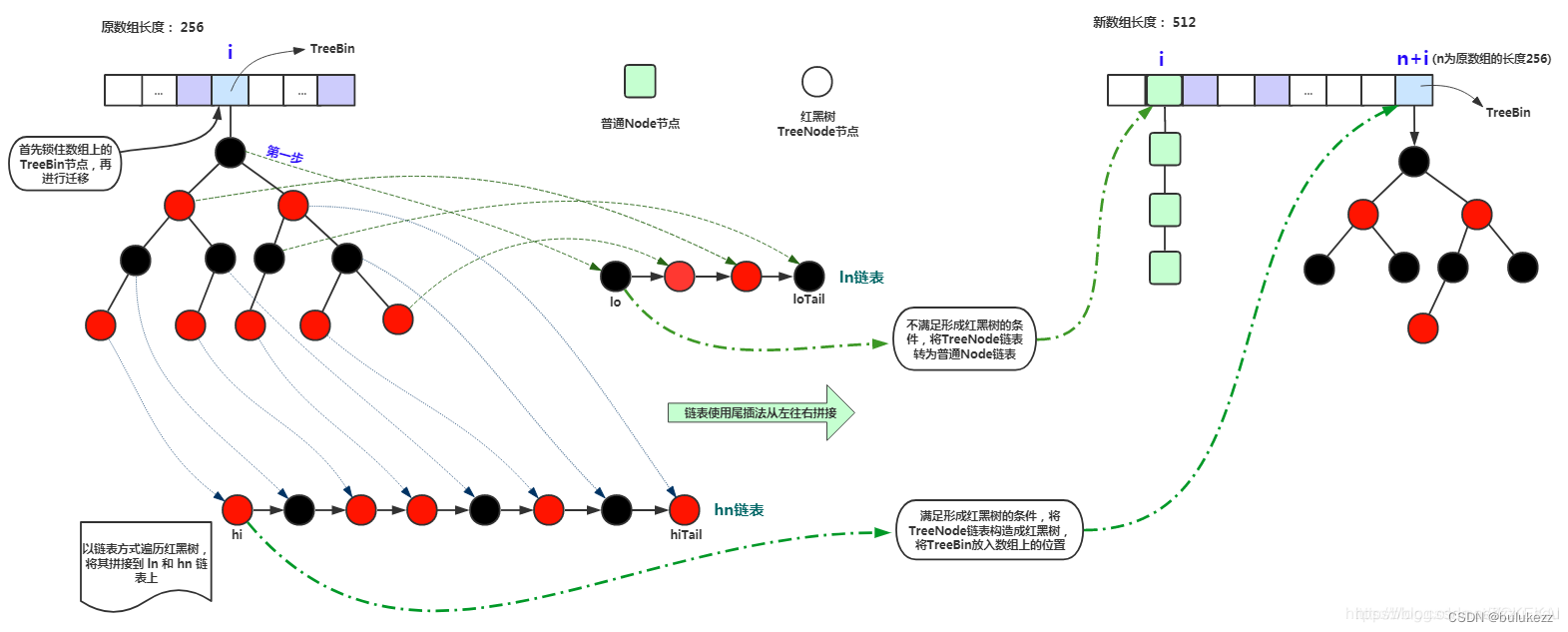
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//判断扩容后是否还需要红黑树结构
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd); // 设置ForwardingNode占位
advance = true; // 表示当前旧桶的结点已迁移完毕
}
}
}
}
}
}
2.4.4、ConcurrentHashMap#addCount方法
每次添加元素后,给元素数量加1,并判断是否到达扩容门槛,达到了则进行扩容处理。
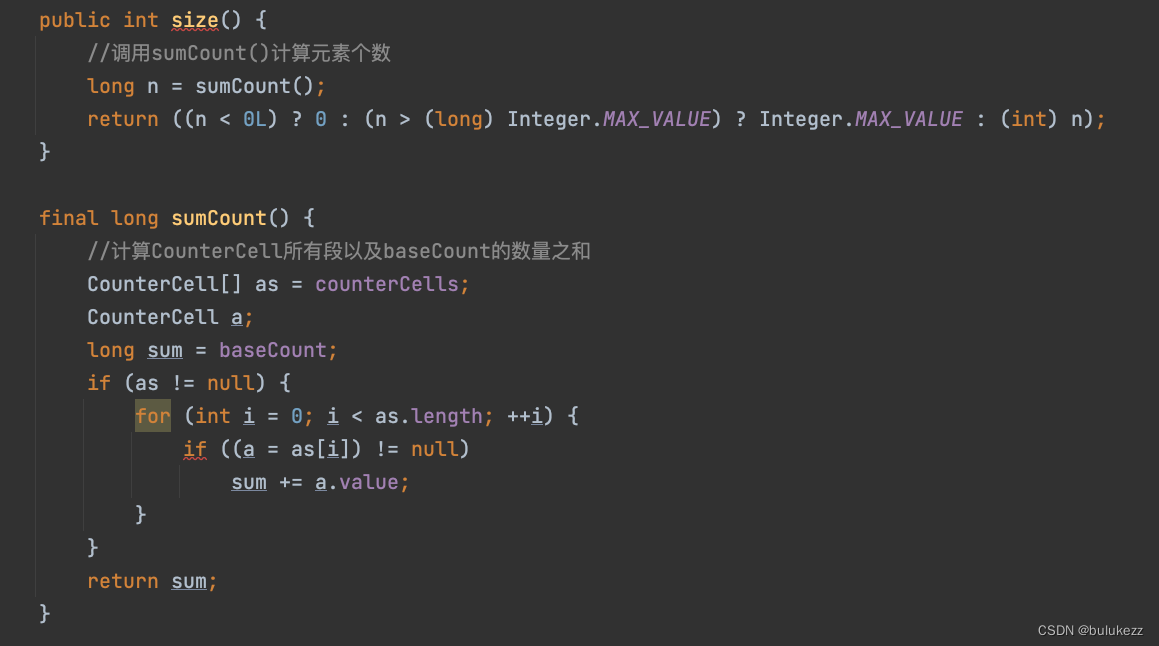
- 元素个数的存储类似于LongAddre,存储在不同的段,减少不同线程同时更新size时候的冲突
- 计算元素个数会把baseCount和各个段的值相加得到总的元素个数
- sizeCtl存储了扩容阈值,如果到达扩容阈值,则进行扩容逻辑
- 扩容时候更新sizeCtl高位存储扩容邮戳(resizeStamp),低位存储扩容线程数+1(1+nThreads)
private final void addCount(long x, int check) {
CounterCell[] as;
long b, s;
// 这里使用的思想跟LongAdder类是一模一样的
// 把数组的大小存储根据不同的线程存储到不同的段上(也是分段锁的思想)
// 并且有一个baseCount,优先更新baseCount,如果失败了再更新不同线程对应的段
// 这样可以保证尽量小的减少冲突
// 先尝试把数量加到baseCount上,如果失败再加到分段的CounterCell上
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a;
long v;
int m;
boolean uncontended = true;
// 如果as为空
// 或者长度为0
// 或者当前线程所在的段为null
// 或者在当前线程的段上加数量失败
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 强制增加数量(无论如何数量是一定要加上的,并不是简单的自旋)
// 不同线程对应不同的段都更新失败了
// 说明已经发生冲突了,那么就对counterCells进行扩容
// 以减少多个线程hash到同一个段的概率
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 计算元素个数
s = sumCount();
}
if (check >= 0) {
Node<K, V>[] tab, nt;
int n, sc;
// 如果元素个数到达了扩容门槛,则进行扩容
// 注意,正常情况下sizeCtl存储的是扩容门槛,即容量的0.75倍
while (s >= (long) (sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// rs是扩容时的一个邮戳标示
int rs = resizeStamp(n);
if (sc < 0) {
// sc<0说明正在扩容中
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
// 扩容已经完成了,退出循环
// 正常应该只触发nextTable=null这个条件,其他条件没看出来何时触发
break;
// 扩容未完成,则当前线程加入迁移元素中
// 并把扩容线程数加1
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 这里是触发扩容的那个线程进入的地方
// sizeCtl的高16位存储着rs这个扩容邮戳
// sizeCtl的低16位存储着扩容线程数+1,即(1+nThreads)
// 所以官方说的扩容时sizeCtl的值为-(1+nThreads)是错误的。
// 进入迁移元素
transfer(tab, null);
// 重新计算元素个数
s = sumCount();
}
}
}
2.4.5、ConcurrentHashMap扩容时机
- 新增元素,如果链表长度到达了阈值8,则会进行树化,树化会对数组长度进行判断,如果小于64则会先调用tryPresize把数组长度扩大到原来的2倍,这个时候会触发transfer方法
- 新增元素,在最后会调用addCount记录元素个数,累加后如果发现到达扩容阈值,则会触发tranfer方法。
- 当前处于扩容状态,其他线程做插入修改等操作的时候,如果在对应slot碰到了FowardingNode节点,则会去做协助迁移逻辑也会调用到tranfer方法
2.4.6、ConcurrentHashMap扩容图示
下图原文地址(原文写的特别好):图示地址
CPU核数与迁移任务hash桶数量分配(步长)的关系
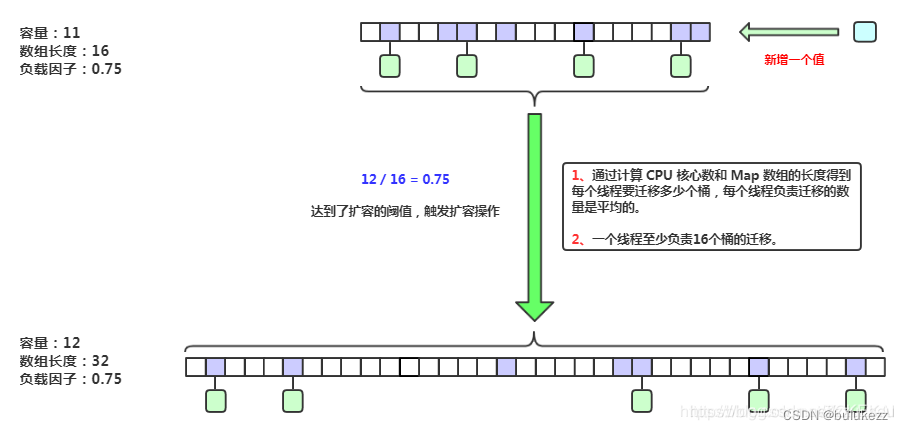
单线程下线程的任务分配与迁移操作
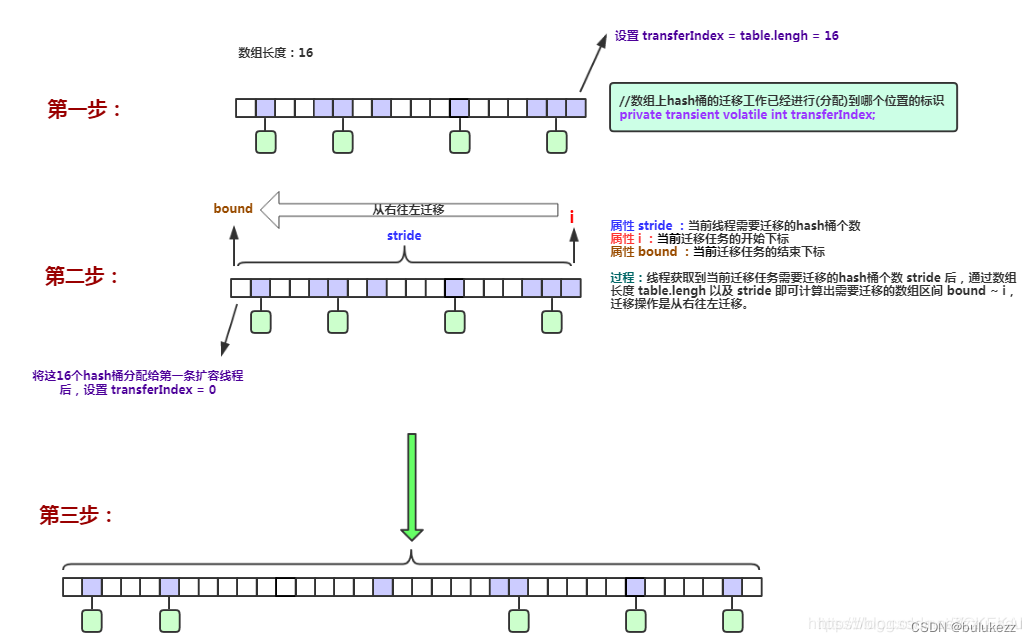
多线程如何分配任务?
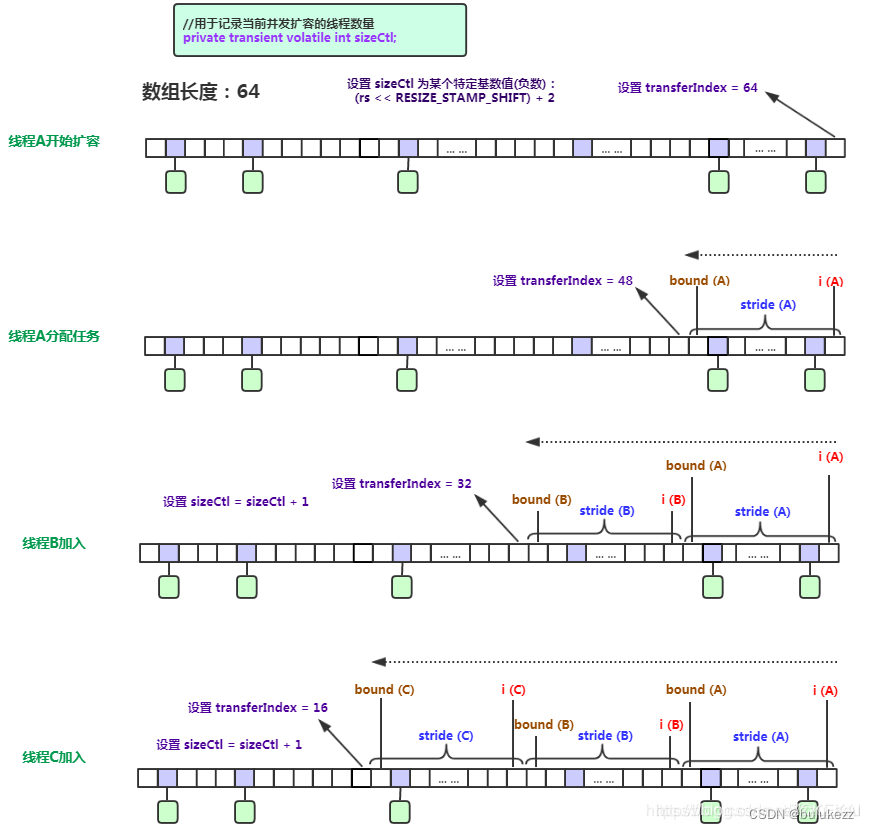
普通链表如何迁移?
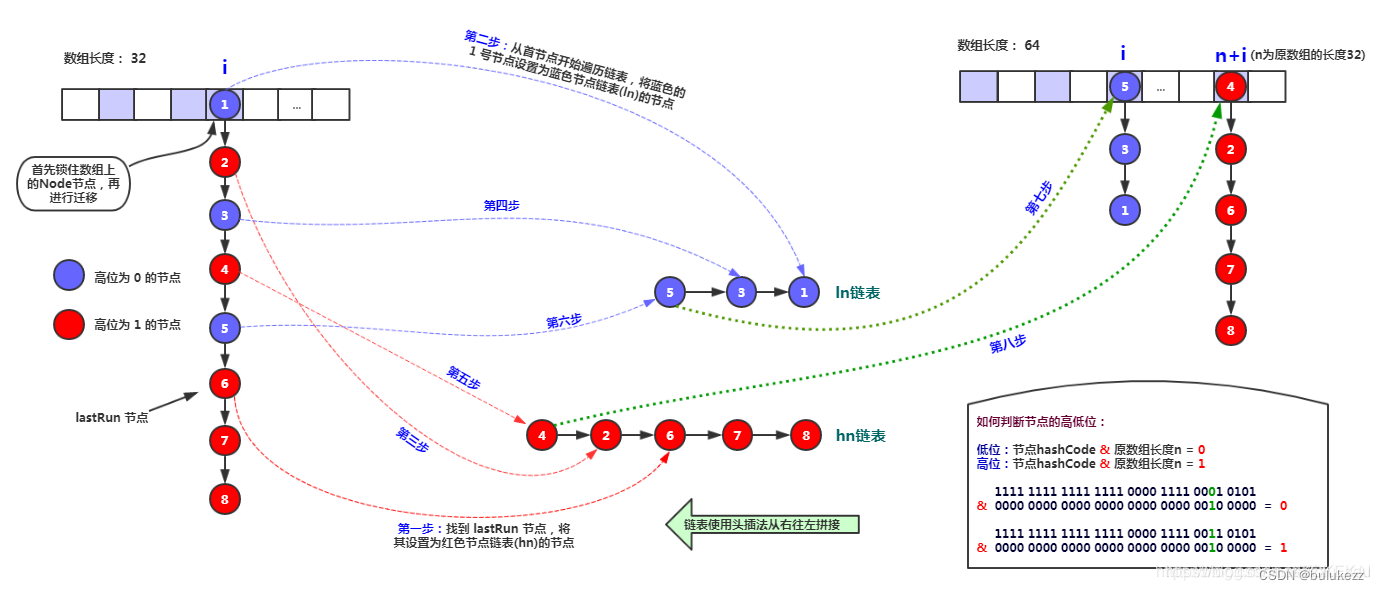
什么是 lastRun 节点?
红黑树如何迁移?
hash桶迁移中以及迁移后如何处理存取请求?
多线程迁移任务完成后的操作
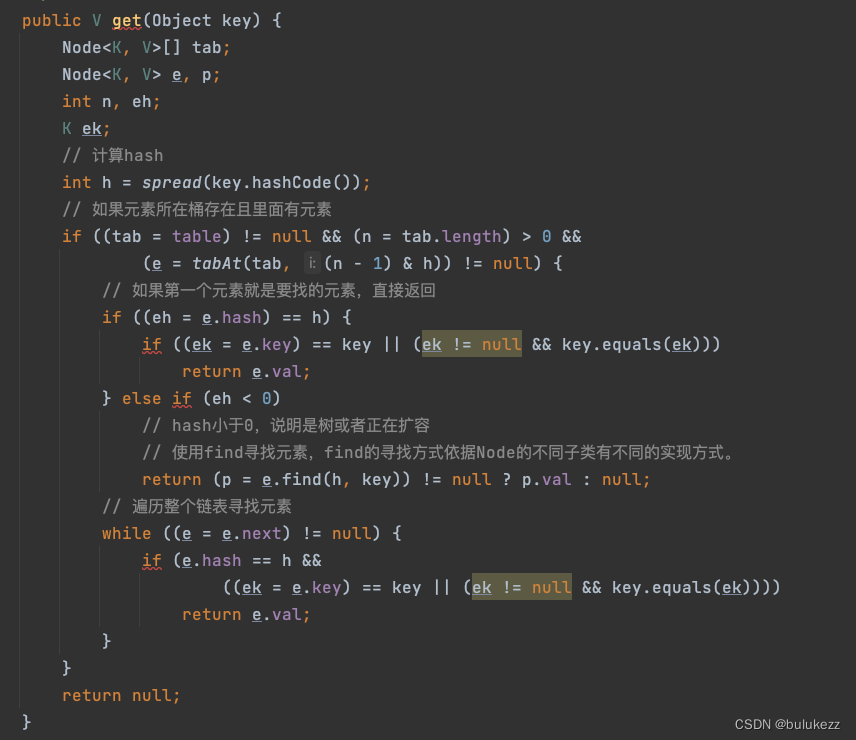
2.5、ConcurrentHashMap#get方法解析
- 计算hash值,定位到所在的桶
- 如果桶中存在元素并且第一个元素就是要找的元素,直接返回
- 如果头节点的hash值小于0,说明有可能是树节点或者是ForwardingNode节点,如果是fwd说明这个节点已经被迁移到新table了,则通过find方法直接到newTable查找。
- 如果是链表,遍历整个链表寻找元素
- 这里元素的获取是没有加锁的。
2.6、ConcurrentHashMap#size方法解析
元素个数的存储也是采用分段的思想,获取元素个数的时需要把所有段累加起来,这个不是强一致性的。
2.7、总结
值得学习的点:
- 尽量使用CAS+字段来避免加锁,减少上下文切换的事件。
- 使用分段锁的思想,来避免同一把锁带来的竞争效率低的问题
- 计数使用分段的思想,避免多线程更新带来的自旋消耗cpu问题
- 多线程协同扩容值得学习,通过维护一个全局可见的属性来进行协同扩容
- 使用volatile来可以避免获取的时候加锁,可以保证更新后立即可见。














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









