









 本文介绍了网络分析领域的数据可视化软件Gephi,它可运行于多系统。文中阐述其特点,如快速、简单、支持扩展,还说明了安装方法、Graph Streaming插件使用步骤,详细介绍布局、分割等工具功能,并通过实战展示如何美化导入的数据。
本文介绍了网络分析领域的数据可视化软件Gephi,它可运行于多系统。文中阐述其特点,如快速、简单、支持扩展,还说明了安装方法、Graph Streaming插件使用步骤,详细介绍布局、分割等工具功能,并通过实战展示如何美化导入的数据。
描述
Gephi 是一款网络分析领域的数据可视化处理软件,开发者对它寄予的希望是:成为 “数据可视化领域的Photoshop” ,可运行在Windows,Linux及Mac os系统。
项目地址:
https://github.com/gephi/gephi
https://github.com/gephi/gephi-plugins
特点
-
快速由内置的OpenGL引擎提供支持,Gephi能够利用非常大的网络推送信封。可视化网络多达一百万个元素。 所有操作(例如布局,过滤器,拖动)都会实时运行。
-
简单易于安装和使用,以可视化为中心的UI,像Photoshop™的图形处理一样。
-
支持模块化扩展Gephi及插件开发,该架构构建在Netbeans平台之上,可以通过精心编写的API轻松扩展或重用。
安装 Gephi
前往Gephi官网:https://gephi.org/users/download/,下载对应的版本进行安装。
Graph Streaming 插件使用
- 安装插件
在菜单栏选择 ‘’工具” -> “插件” -> “可用插件” 中找到Graph Streaming点击进行安装。安装完成后在左下方的菜单栏会显示Streaming的选项卡
- 新建项目
在菜单栏选择 “文件” -> “新建项目”,”工作区” -> “重命名” 输入”workspace1” 对项目进行重命名。 - 启动Server
在”Streaming”选项卡,点击”Master”展开子类,选中”Master Server”右键点击选择”start”,启动Server。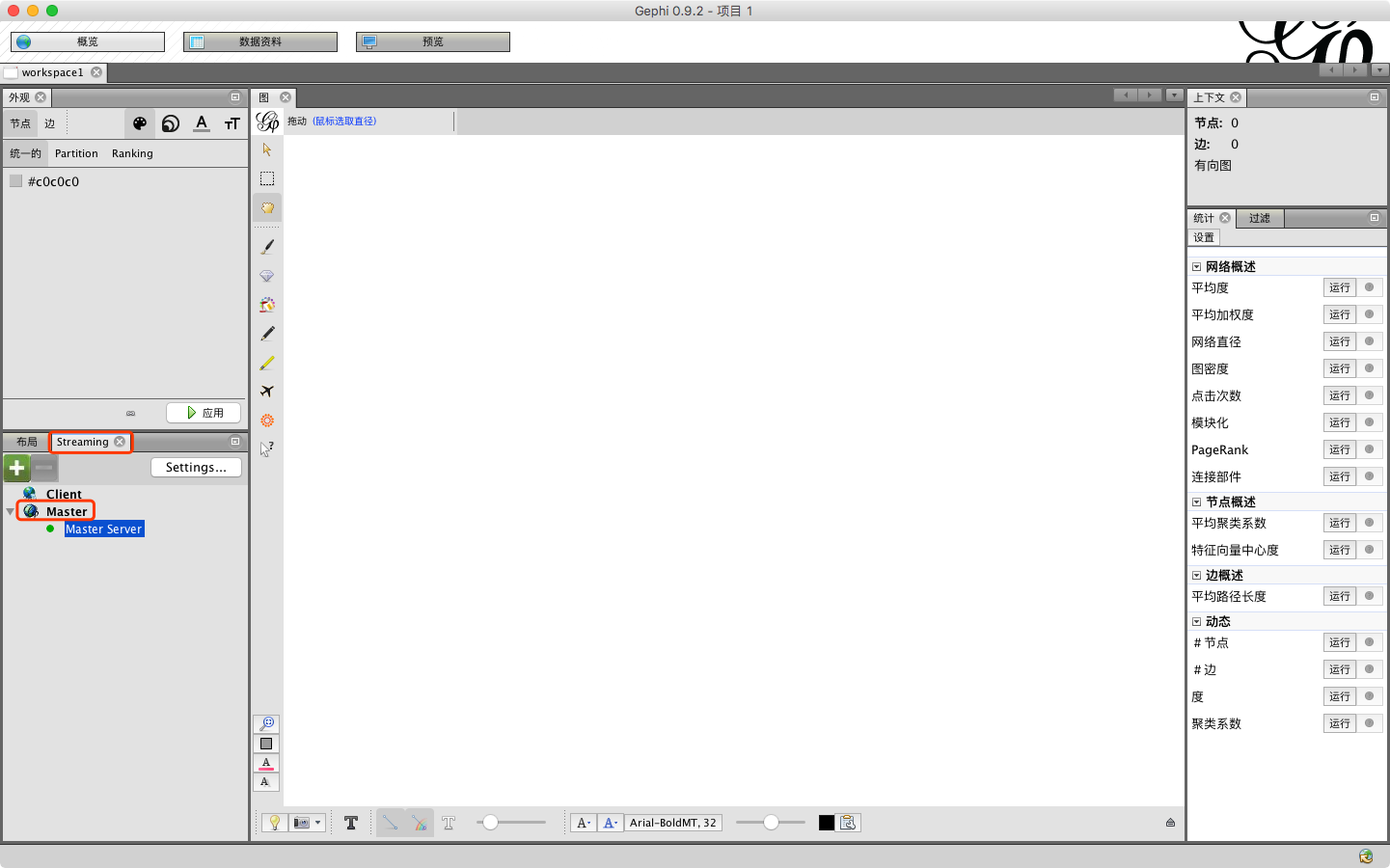
-
Gremlin 连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
# 查看使用的插件列表 gremlin> :plugin list ==>janusgraph.imports[active] ==>tinkerpop.server[active] ==>tinkerpop.gephi ==>tinkerpop.utilities[active] ==>tinkerpop.sugar ==>tinkerpop.credentials ==>tinkerpop.hadoop[active] ==>tinkerpop.spark[active] ==>tinkerpop.tinkergraph[active] # 使用 tinkerpop.gephi 插件 gremlin> :plugin use tinkerpop.gephi ==>tinkerpop.gephi activated gremlin> :plugin list ==>janusgraph.imports[active] ==>tinkerpop.server[active] ==>tinkerpop.gephi[active] ==>tinkerpop.utilities[active] ==>tinkerpop.sugar ==>tinkerpop.credentials ==>tinkerpop.hadoop[active] ==>tinkerpop.spark[active] ==>tinkerpop.tinkergraph[active] # 创建简单的 Modern 图 gremlin> graph = TinkerFactory.createModern() ==>tinkergraph[vertices:6 edges:6] # 连接到 tinkerpop.gephi 插件 gremlin> :remote connect tinkerpop.gephi ==>Connection to Gephi - http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 1.0, 0.5], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33 gremlin> :> graph Connect to localhost:8080 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection refused (Connection refused) # 连接到 tinkerpop.gephi 插件,设置port值 gremlin> :remote connect tinkerpop.gephi ==>Connection to Gephi - http://localhost:8080/workspace1 with stepDelay:1000, startRGBColor:[0.0, 1.0, 0.5], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33 gremlin> :remote config port 8088 ==>Connection to Gephi - http://localhost:8088/workspace1 with stepDelay:1000, startRGBColor:[0.0, 1.0, 0.5], colorToFade:g, colorFadeRate:0.7, startSize:10.0,sizeDecrementRate:0.33 gremlin> :> graph ==>tinkergraph[vertices:6 edges:6] ==>false
至此,图数据库中的数据已经导入到Gephi中。


Gephi 工具介绍
布局、分割、排序、过滤、统计
- 布局(Layout): 根据算法规则自动美化图形的工具。
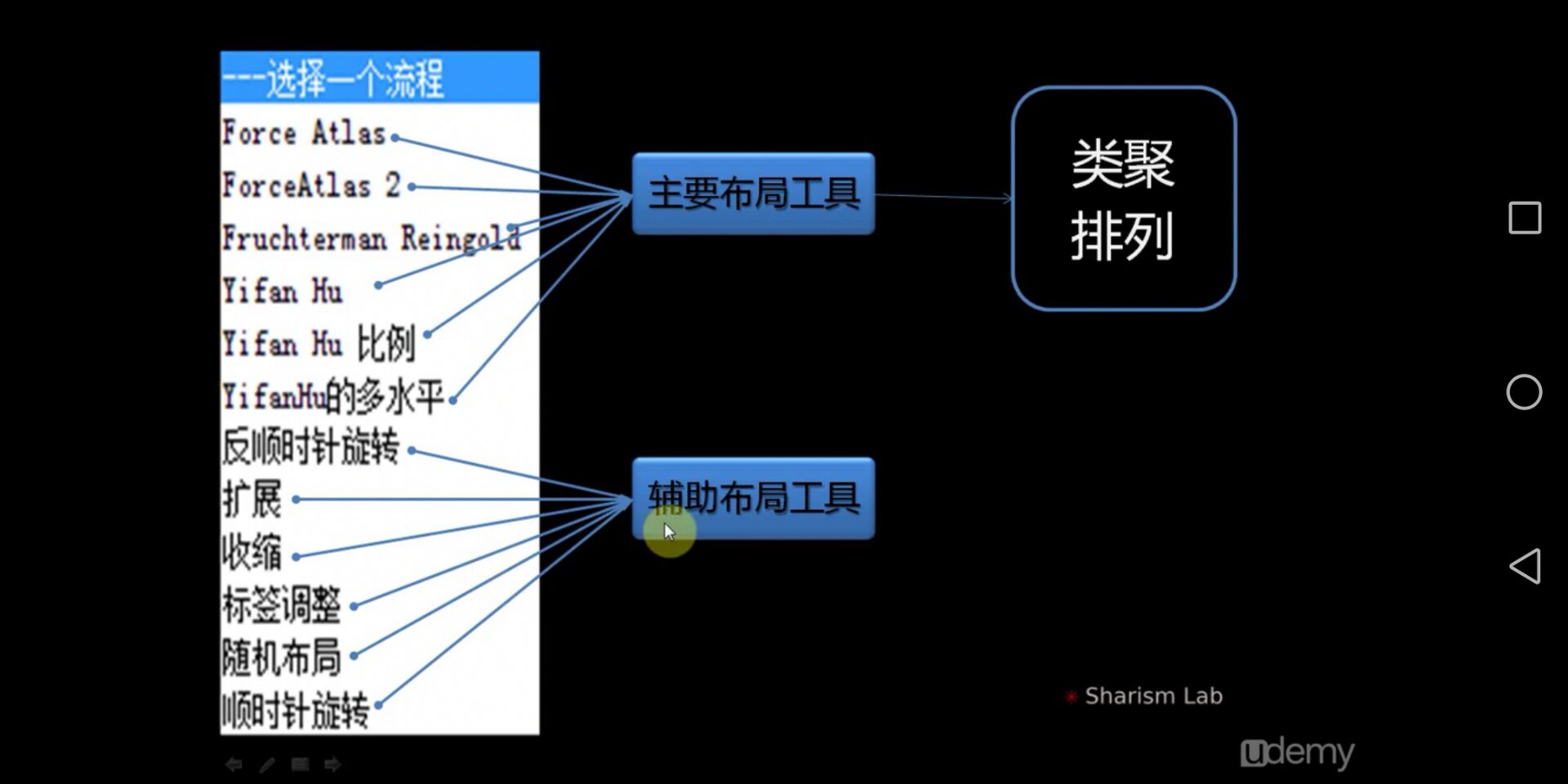 Gephi提供12中布局方式,前6种是主要布局工具,后面6种是辅助布局工具。
Gephi提供12中布局方式,前6种是主要布局工具,后面6种是辅助布局工具。
最常用的是:力导向算法(Force Atlas和 ForceAtlas2)、圆形布局和胡一凡布局(Yifan Hu、Yifan Hu比例、Yifan Hu多水平)。- Force Atlas及Force Atlas2
Force Atlas及Force Atlas2为力引导布局,力引导布局方法能够产生相当优美的网络布局,并充分展现网络的整体结构及其自同构特征,所以在网络节点布局技术相关文献中该方法占据了主导地位。
力引导布局即模仿物理世界的引力和斥力,自动布局直到力平衡;Force Atlas布局使图更紧凑,可读性强,并且显示大于hub的中心化权限(吸引力分布选项),自动稳定提高布局的衔接。 - Fruchterman Reingold布局
Fruchterman和Reingold基于再次改进的弹性模型提出了FR算法。该算法遵循两个简单的原则:有边连接的节点应该互相靠近;节点间不能离得太近。FR算法建立在粒子物理理论的基础上,将图中的节点模拟成原子,通过模拟原子间的力场来计算节点间的位置关系。算法通过考虑原子间引力和斥力的互相作用,计算得到节点的速度和加速度。依照类似原子或者行星的运动规律,系统最终进入一种动态平衡状态。 - Yifan Hu多水平布局
Yifan Hu、Yifan Hu比例、Yifan Hu多水平为胡一凡布局,Yifan Hu多水平布局适用于非常大的图形,特点是粗化图形,减少计算量,运行速度比较快。
- Force Atlas及Force Atlas2
- 分割(Partition): 分割也是一种归类,把值相同的节点或边用不同的颜色标示出来,还可把值相同的节点组合成一个节点。
- 度中心性(Degree Centrality): 在网络分析中刻画节点中心性(Centrality)的最直接度量指标,一个节点的节点度越大就意味着这个节点的度中心性越高,该节点在网络中就越重要。
- 中介中心性(Between Centrality): 度量一个节点出现在网络中最短路径上的频率。
- 接近中心性(Closeness Centrality): 反映在网络中某一节点与其他节点之间的接近程度。将一个节点到所有其他节点的最短路径距离的累加起来的倒数表示接近性中心性。即对于一个节点,它距离其他节点越近,那么它的接近性中心性越大。
- 特征向量中心性(Eigenvector Centrality): 一个节点的重要性既取决于其邻居节点的数量(即该节点的度),也取决于其邻居节点的重要性。
- 离心率: 从一个给定起始节点到距其最远节点的距离。
- 排序(Ranking): 根据一些值对节点和标签进行归类和排序,并把排序以大小、颜色的形式应用到节点和标签上。
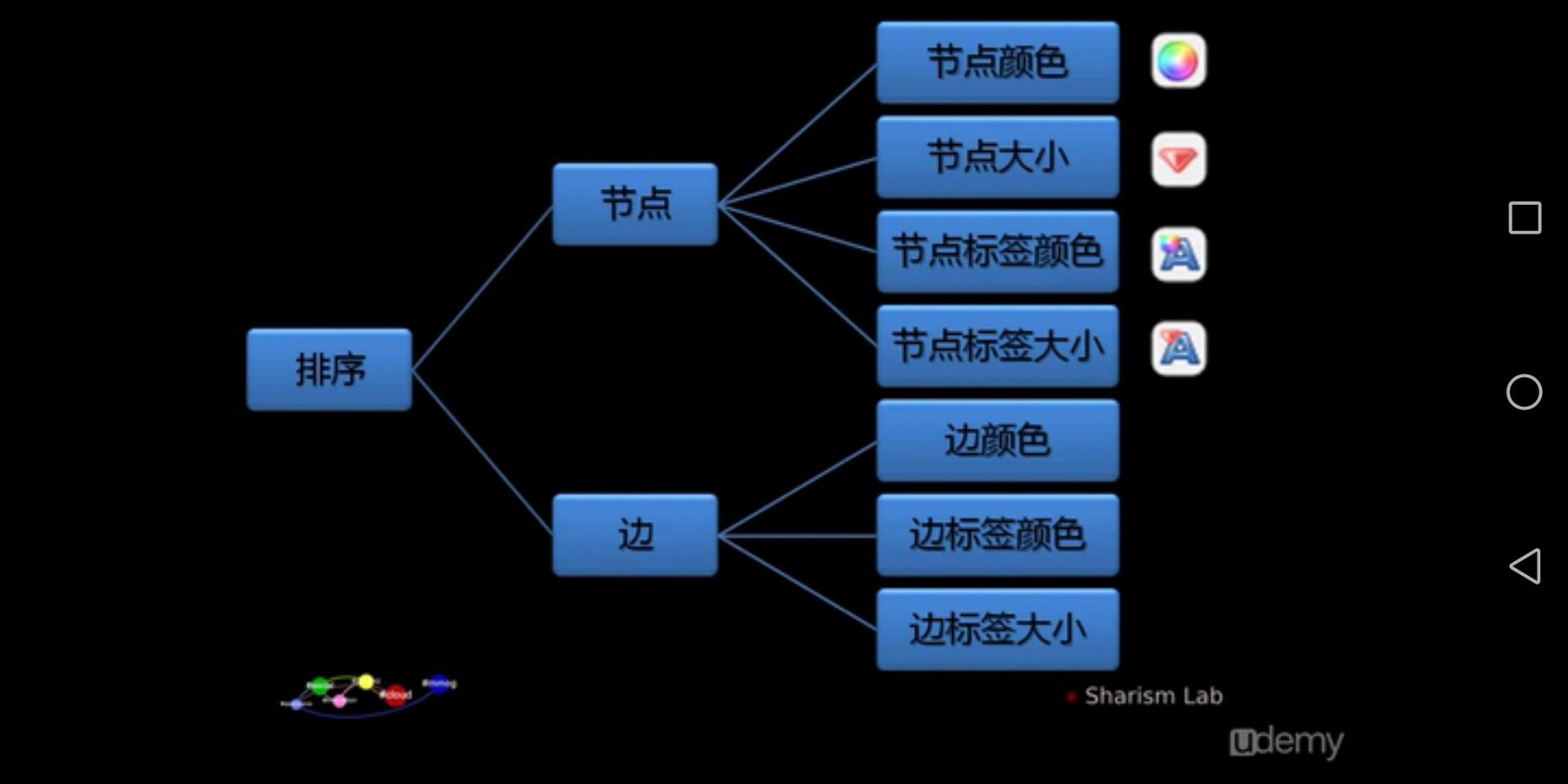
- 过滤(Filters): 在作图过程中经常需要把一些值相同的节点或边选择出来,此时需要用到过滤工具,通过过滤功能实现选择或者将符合条件的节点和边过滤出来。
- 统计(Statistics): 根据内置的算法对节点和边的属性值做运算,并把运算结果存入节点和边的属性里面,供分割和排名使用。
- degree(平均度): 计算每个节点的度,并统计相同度的节点数量
平均度: 有向图: 所有点的度数总和/节点数*2 无向图: 所有点的度数总和/节点数
在图上能够,看出每个度所占的百分比,能够看到每种度用不同颜色标示
通过这个可以看出哪些节点的度高,反应出连接他的点就多,就越关键 - weightedDegree(平均加权度): 加权入度 加权出度 加权度
有向图: 取得每个点的边,如果该边的源为该节点,那么该边的权重为加权出度,反之亦然。计算出每个点的加权出度,入度和度
其实平均度是平均加权度的一个特例,平均度的每条边的权重为1
加权度为加权出度和入度的总和
计算同样入度出度的节点个数
无向图: 取得每个点的边,将边的权重求和,即为该点的加权度
平均加权度: 有向图:加权度总和/2*节点数 无向图: 加权度总和/节点数 - GraphDistance(网络直径): 指网络任意两节点间距离的最大值。
- graphdensity(图密度):
无向图: 边数2 / (节点数节点数-节点数)
有向图: 边数 / (节点数节点数-节点数)
大概理解: (节点数节点数-节点数) 这个计算出最多的连接边数(不包含连自己) , 用实际边数除以最大可能边数,即为密度, 结果越大表示图中节点连接越紧密 - hits(点击次数): 分析经典的基于超链接分析的主题搜索
计算2个值
authority: 每个节点入度的比值。 简单的,就是总的节点的入度和,除以该节点入度和,提现节点重要性,或者页面的重要性,被链接的多,说明入度多,就跟重要
计算每个引入(指向该节点)该节点(有入度的节点)的节点的hub(初始为1)总和,用该值除以所有点的authority值
hub:
计算每个引入(指向该节点)该节点(有出度的节点)的节点的 authority (初始为1)总和,用该值除以所有点的 hub 值 - modularity(模块化): 一种聚类算法
- 平均路径长度: 指所有点对之间的最短路径的算术平均值。
- degree(平均度): 计算每个节点的度,并统计相同度的节点数量


Gephi 实战
在Graph Streaming插件使用中我们已经把数据成功导入到了Gephi中,看下目前的预览效果。
就是一坨很丑的看不懂的东西,接下来我们将使用Gephi来美化它。
- 布局
选择”Force Atlas”布局,属性”斥力强度”修改为 10000,”由尺寸调整”打钩选中,然后点击”运行”。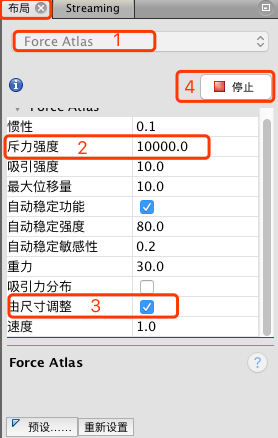
预览效果如下:
- 外观
选择”节点” -> “Partition” -> “name”,以节点的”name”属性来对节点的颜色进行区分,点击”应用”按钮。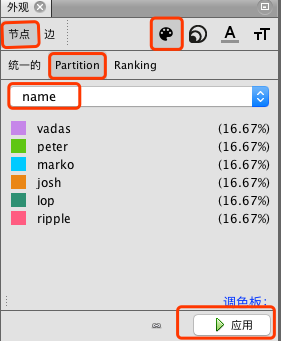
选择”节点” -> “大小” -> “统一的”,设置节点大小为40,点击”应用”按钮。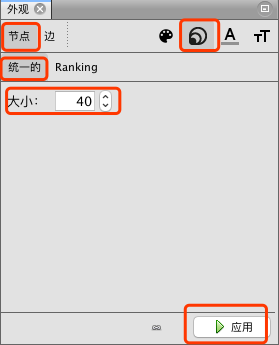
选择”节点” -> “边” -> “Ranking” -> “边的权重”,设置边的颜色,点击”应用”按钮。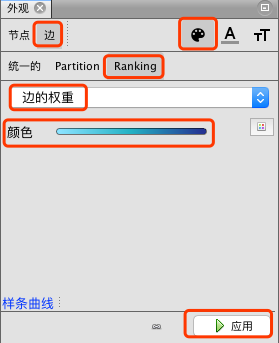
预览效果如下: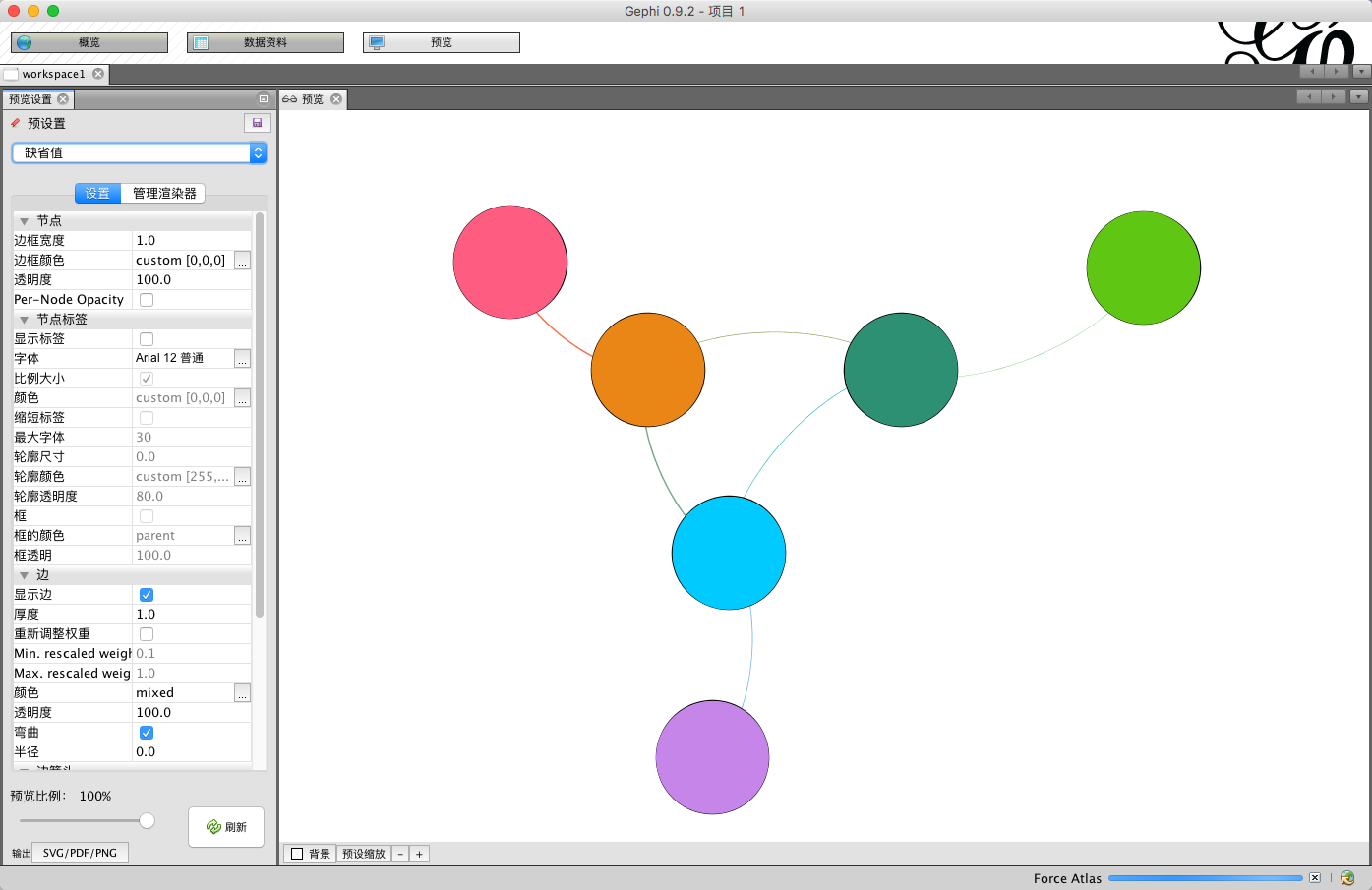
- 预览
选择 “节点标签” -> “显示标签” -> “选中打钩”,在”字体”中调整字体的大小等。
选择 “边标签” -> “显示标签” -> “选中打钩”,点击”刷新”。
效果如下: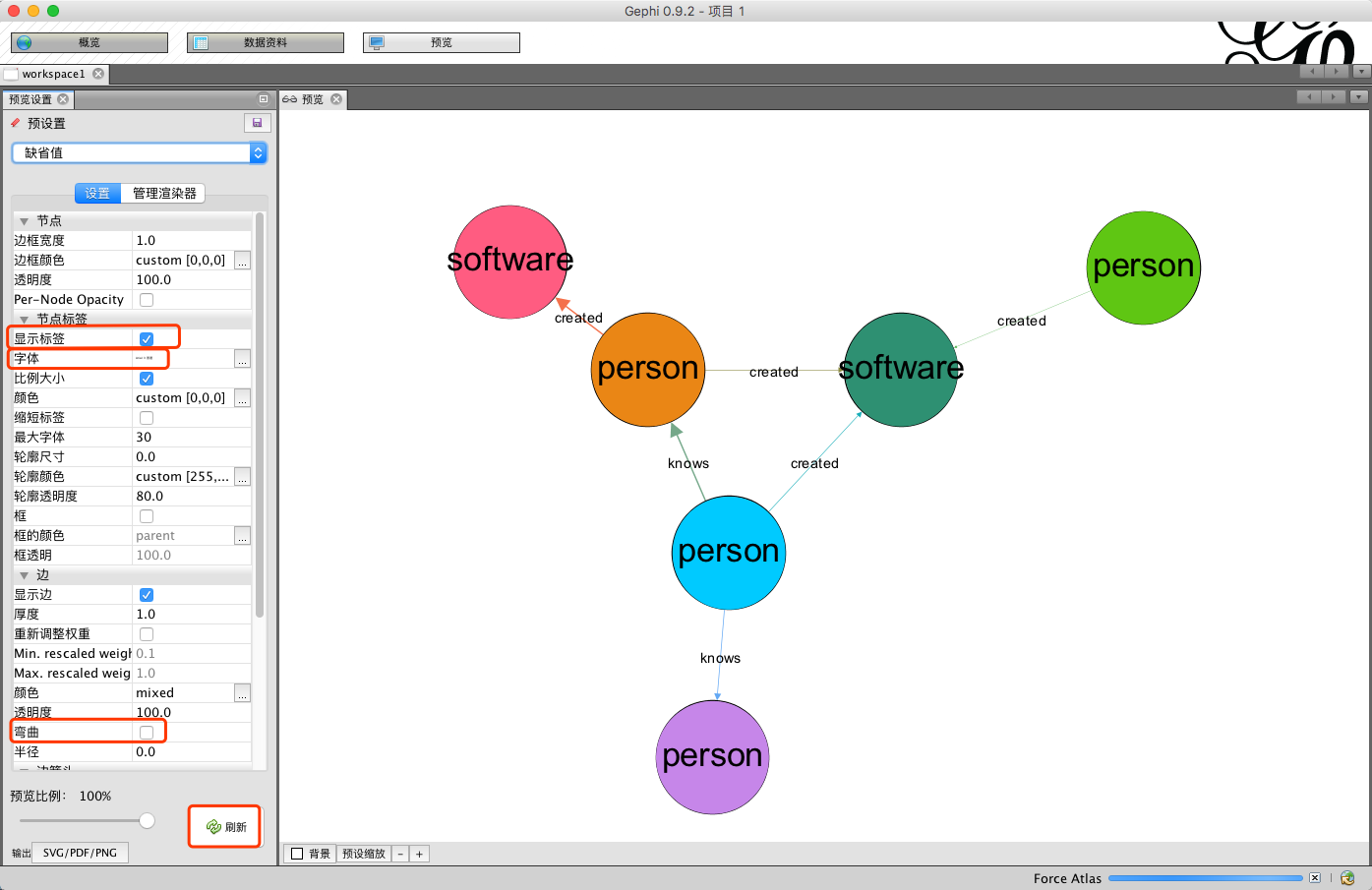







更多
Tinkerpop Gephi Plugin 文档:http://tinkerpop.apache.org/docs/current/reference/#gephi-plugin


















 2570
2570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











