







定义一个一维数组
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
那么数组名 arr 表示什么呢?
通常来说数组名就是数组首元素的地址,但是有2个例外:
- sizeof(数组名),数组名单独放在sizeof()内部,这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名也表示整个数组,这里取出的是整个数组的地址除此之外所有遇到的数组名都表示数组首元素的地址。
一下是代码演示:
int main()
{
int arr[10] = { 1,2,3,4,5,6 };
printf("%d\n", sizeof(arr)); //计算出的是整个数组的大小
printf("%p\n", arr); //数组的地址,也是数组首元素的地址
printf("%p\n", arr+1); //数组首元素后第二个元素的地址
printf("%p\n", &arr[0]); //数组首元素的地址
printf("%p\n", &arr[0]+1); //数组第二个元素的地址
printf("%p\n", &arr);//数组的地址
printf("%p\n", &arr+1);//+1,跳过整个数组
return 0;
}
执行结果为:
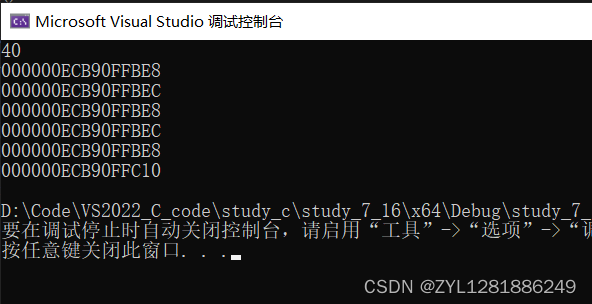
我们可以从结果中看出 sizeof(arr) 计算出来的是整个数组的大小。arr 地址与 &arr地址的值上相同,但通过地址加一可以看出,前者实际表示的是数组首元素的地址,后者则是表示整个数组的地址,只是在值上二者一致。
相信读者也许遇到过这样的困惑:
下面是一个实现冒泡排序函数的代码
void bubble_sort(int arr[10])
{
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]); //计算数组的长度
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
bubble_sort(arr);
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
以上的代码存在问题嘛? 相信对数组名传参不是很熟悉的读者会认为不存在问题。尔最终的执行结果为:
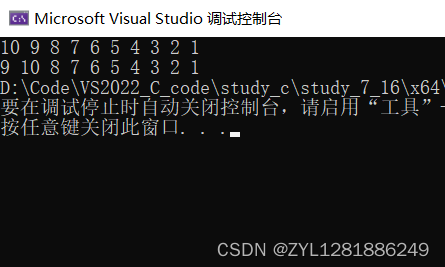
我们发现代码并没有正确的执行,但这是为什么呢?
其实在函数调用 bubble_sort(arr); arr表示的是数组首元素的地址,并不是将整个数组当成参数。因此在bubble_sort函数内部计算的 int sz = sizeof(arr) / sizeof(arr[0]) 并不是数组的长度, sizeof(arr)计算的是数组指针的大小而并非数组的大小。因此冒泡排序函数的正确写法因该如下:
void bubble_sort(int arr[10], int sz)//这里的arr的本质是指针
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]); //计算数组的大小
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//冒泡排序 - 升序
//趟数
//arr作为数组进行了传参
//数组传参,传递的是地址,传递的是首元素的地址
//
bubble_sort(arr,sz);//arr 是数组首元素的地址
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
执行结果正确:
















 1773
1773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









