






Hello,大家好!!!这里是小周为您带来的呕心沥血之作------C语言秘籍!!
C语言秘籍分为初阶和高阶两部!!跟着小周学定会让你C语言功力大成,称霸武林,话不多说,我们接着上回继续开讲!!!!!
四、数组
1、一维数组的创建和初始化
1.1 数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name [const_n]
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小eg:如果我想把1 2 3 4 5 6 7 8 9 10放在一块连续的空间中,该如何存放呢?
int arr[10]
// int 这10个数都是整型,所以创建的数组就是int类型
// arr 数组名,名字随意,最后有意义
// [10] 数组有10个元素,[]中是数组的大小int main()
{
int arr1[10];
return 0;
}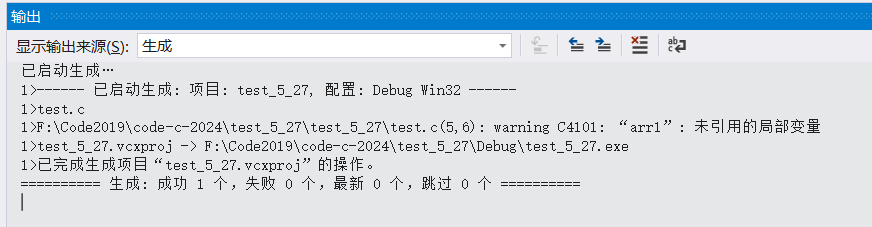
这个警告“arr1”: 未引用的局部变量,是因为我们只将arr1创建了,但是并没有使用,使用之后就可以解决这个问题
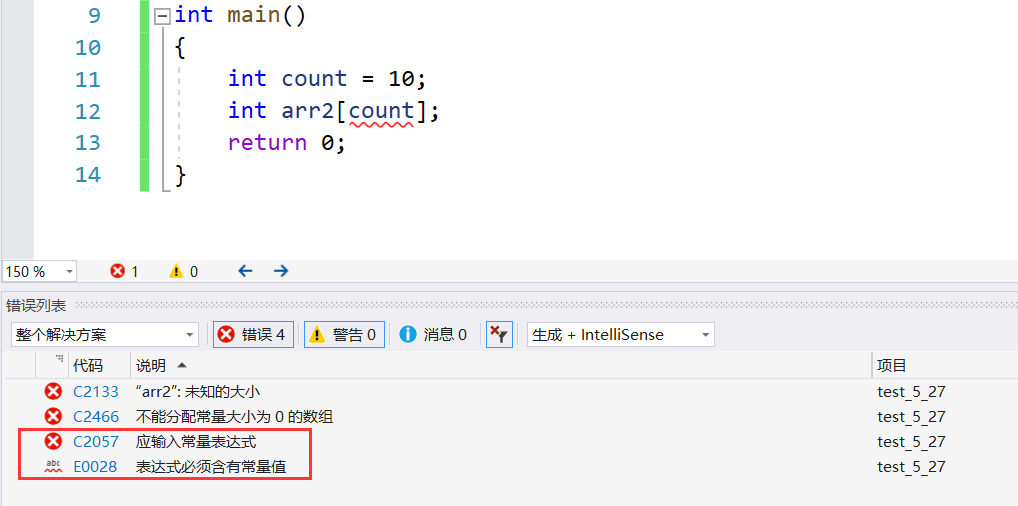
那我们数组的大小如果是变量,那这个数组还能创建成功吗?
在VS2019这个编译器上是不被允许的
int main()
{
int count = 10;
int arr2[count];//必须是常量表达式才可以
//VS2019 VS2022 这样的IDE不支持C99中的变长数组
//C99标准之前数组的大小只能是常量表达式
//C99标准中引入了变长数组的概念,使得数组在创建的时候可以使用变量,但是这样的数组不能初始化
//局部变量或者数组存放在栈区,存放在栈区上的数据,如果不初始化,默认是随机值
return 0;
}1.2 数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)
运行结果如下
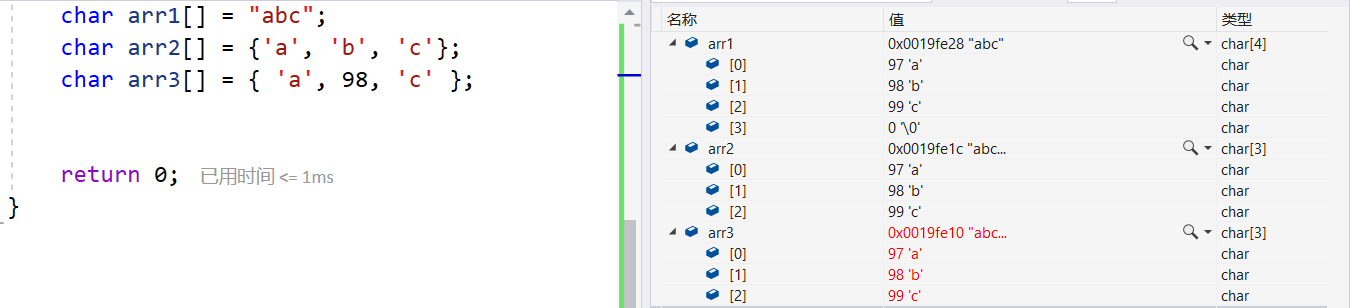
我们发现,arr1和arr2在内存中存储的内容是不一样的,字符串还有一个\0存在,这个要注意
字符数组arr3中出现数字会转成对应的ASCII码
数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
1.3 一维数组的使用
对于数组的使用我们之前介绍了一个操作符:[],下标引用操作符。它其实就是数组访问的操作符
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };//数组的完全初始化
// 下标 0 1 2 3 4 5 6 7 8 9
//如何使用?如下
printf("%d\n", arr[5]);//[] 下标引用操作符,访问数组下标为5的元素
printf("%d\n", arr[0]);//[] 下标引用操作符,访问数组下标为0的元素
int i = 0;
//计算数组大小
int sz = sizeof(arr) / sizeof(arr[0]);// 整个数组大小/首元素大小=10
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);//循环打印每个数组元素
}
return 0;
}总结:
-
数组是使用下标来访问的,下标是从0开始。
-
数组的大小可以通过计算得到。
1.4 一维数组在内存中的存储
知道了一维数组的使用之后,那它在内存中是什么样的呢?我们一起来看看
//%p -- 是用来打印地址的
int main()
{
int arr[10] = { 1,2,3,4,5 };
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}运行结果如下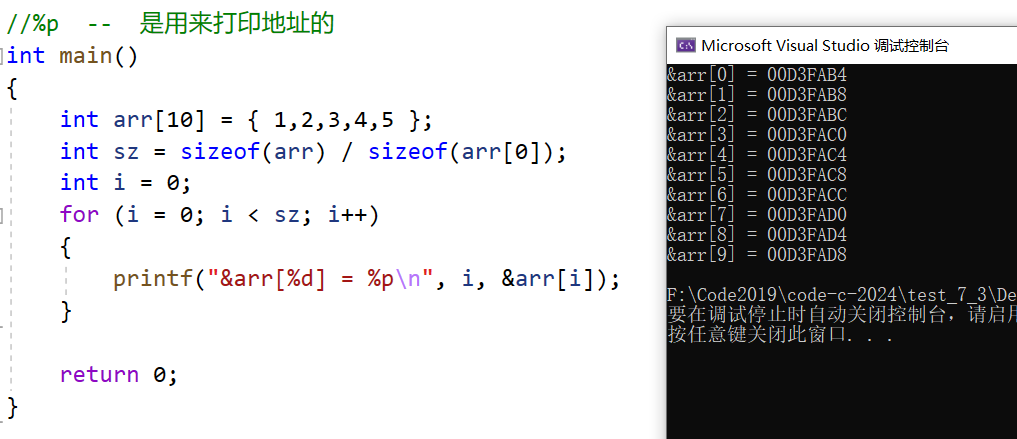
补充:
16进制:0 1 2 3 4 5 6 7 8 9 a b c d e f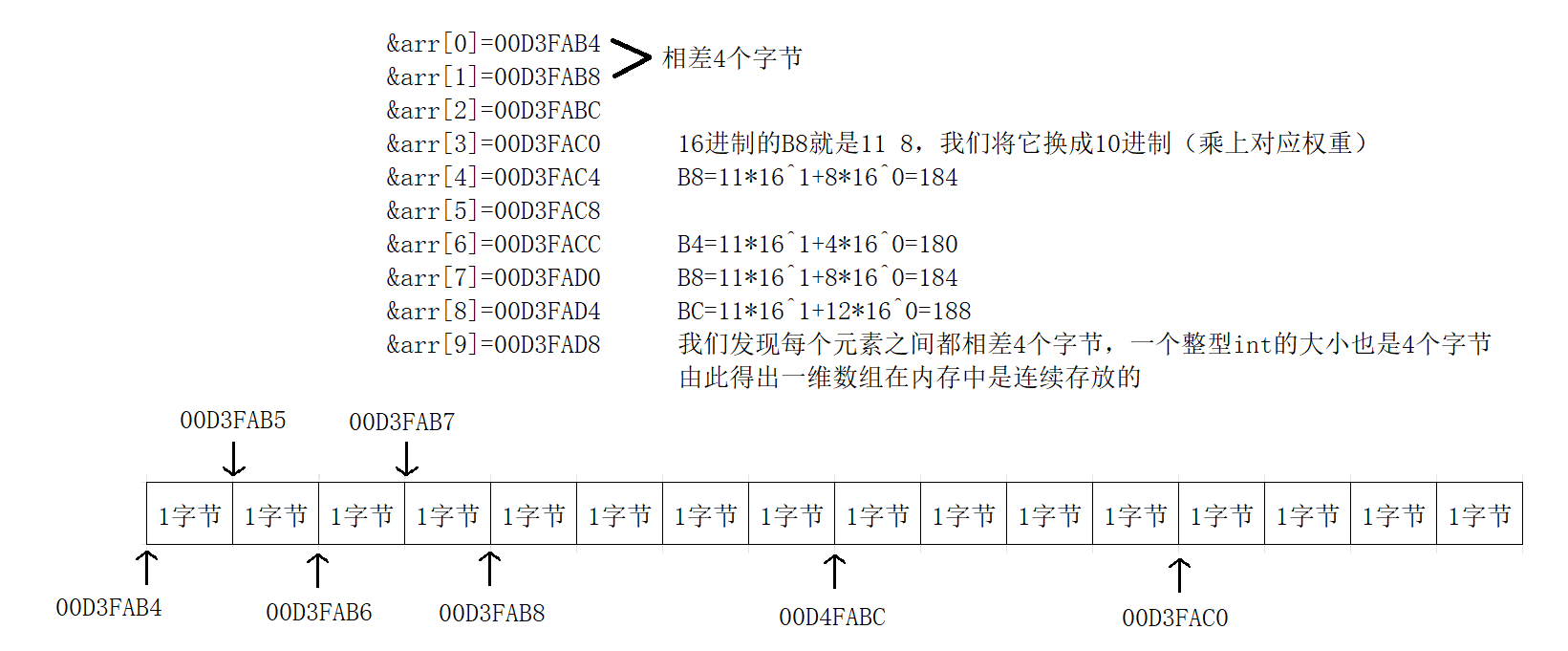
仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址,也在有规律的递增。
由此可以得出结论:数组在内存中是连续存放的。
2、二维数组的创建和初始化
2.1 二维数组的创建
二维数组的创建是在一维数组的基础上进行延申,多了一个维度
type_t arr_name [const_n][const_n]
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小.第一个表示行,第二个表示列//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];2.2 二维数组的初始化
二维数组的初始化与一维数组略有不同
int arr[3][4] = {1,2,3,4};
int arr[3][4] = {{1,2},{4,5}};
int arr[][4] = {{2,3},{4,5}};//二维数组如果有初始化,行可以省略,列不能省略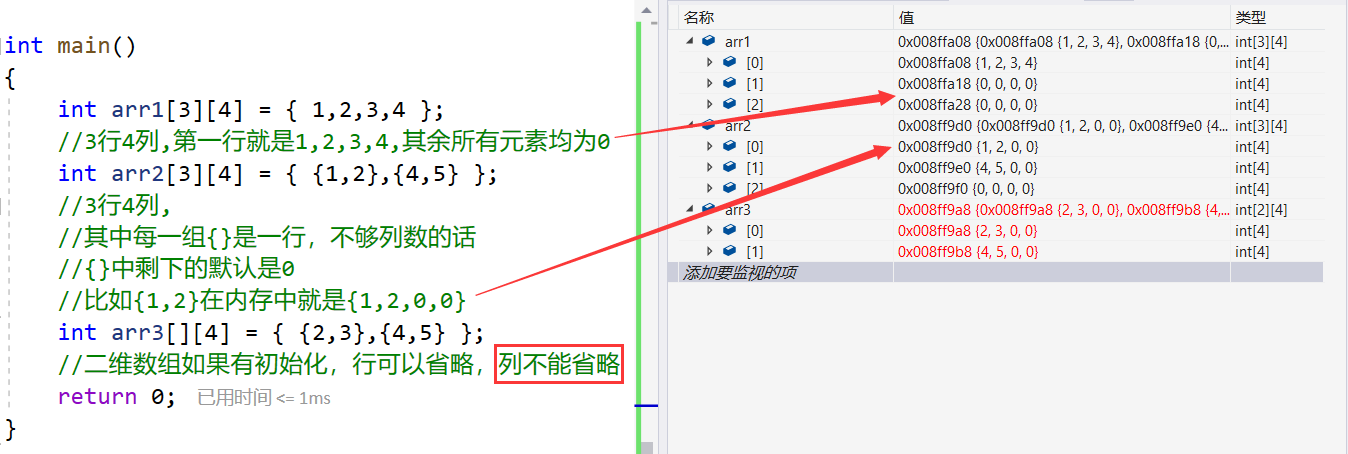
在这里需要注意,二维数组的行和列都是从0开始的
2.3 二维数组的使用
二维数组的使用也是通过下标的方式
//先创建一个二维数组
int main()
{
int arr[3][4] = { {1,2,3,4},{2,3,4,5},{3,4,5,6} };
return 0;
}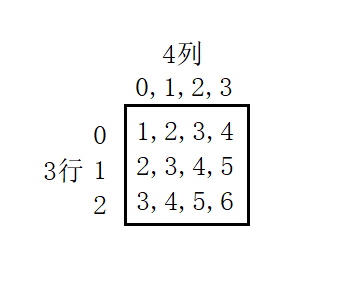
如果我们想访问第3行,第4列的元素6,该如何做到呢?
int main()
{
int arr[3][4] = { {1,2,3,4},{2,3,4,5},{3,4,5,6} };
printf("%d\n", arr[2][3]);//注意是从第0行,第0列开始计算,所以是arr[2][3]
return 0;
}2.4 二维数组在内存中的存储
int main()
{
int arr[4][5] = { 0 };
int i = 0;
//行号
for (i = 0; i < 4; i++)
{
int j = 0;//列号
for (j = 0; j < 5; j++)
{
printf("&arr[%d][%d] = %p\n",i,j, &arr[i][j]);
}
}
return 0;
}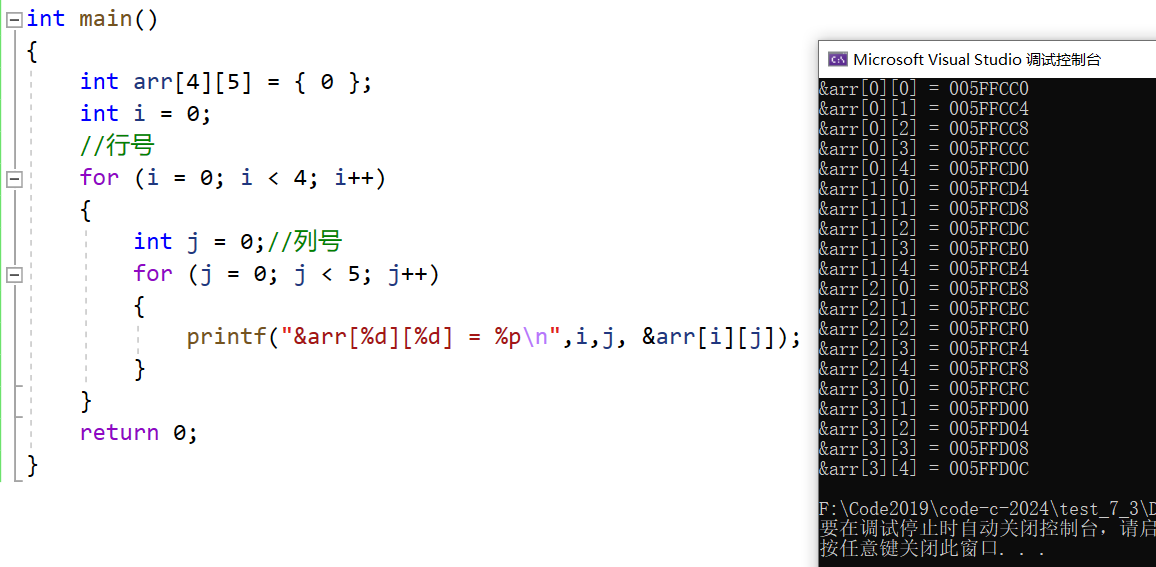
先遍历第一行的每一列,再遍历后续的每一行就可以成功遍历二维数组的每一个元素
每个元素相邻间依然相差4,具体计算参照一维数组在内存中的存储
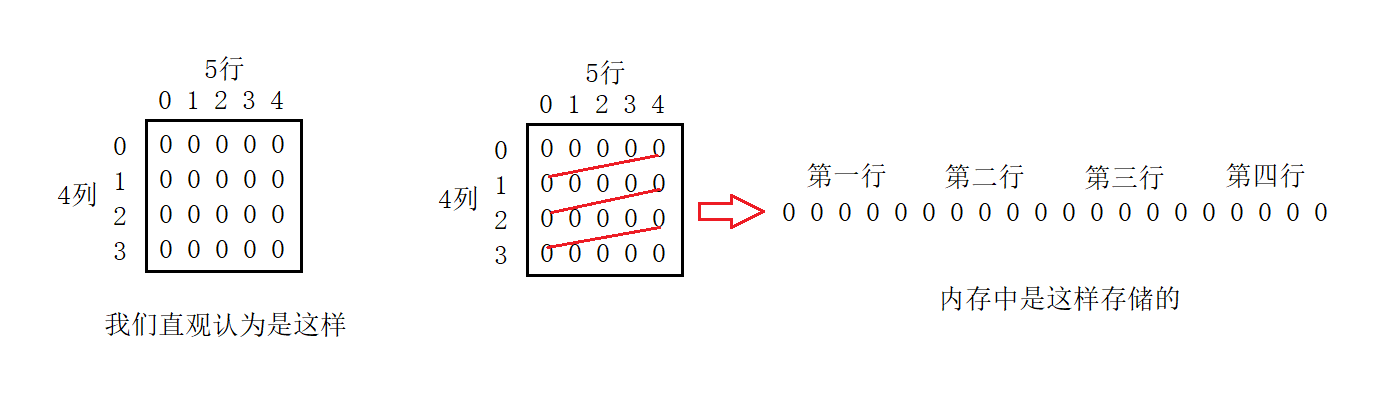
通过结果我们可以分析到,其实二维数组在内存中也是连续存储的
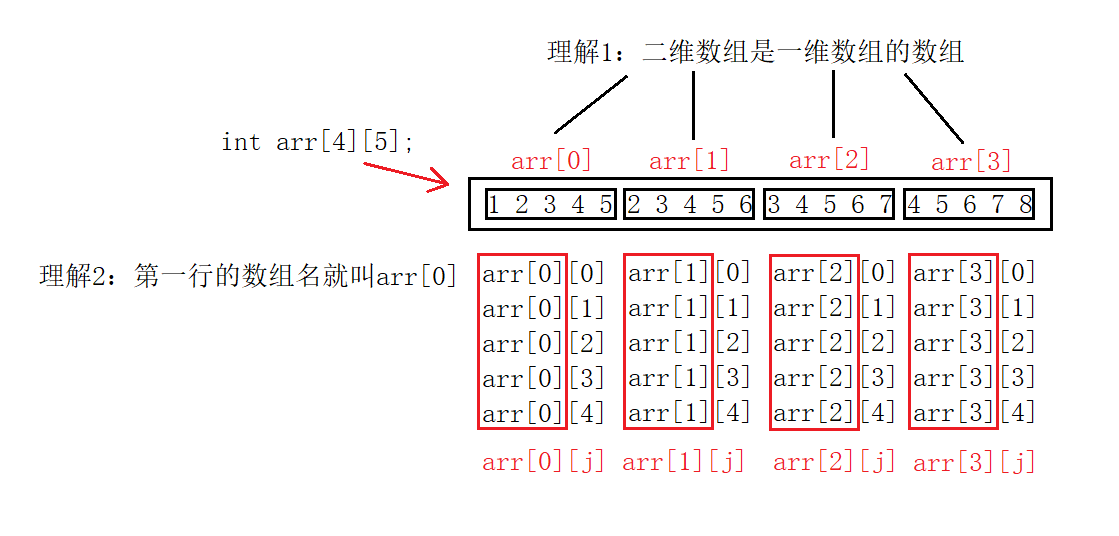
一些深度理解:
3、数组越界
数组的下标是有范围限制的。
数组的下标规定从0开始的,如果数组有n个元素,最后一个元素的下标就是与元素个数n-1。所以数组的下标如果小于0,或者大于n-1,就代表数组越界访问了,即超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,要自己做好越界的检查
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i <= 10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0;
}
我们发现访问下标为10的元素时,出现了一个随机的数字,这就造成了数组的越界访问
4、数组作为函数参数
//输入10个整数,对这组数进行排序 //排序有很多的方法 //1. 冒泡排序 //2. 选择排序 //3. 插入排序 //4. 快速排序 //....
往往我们在写代码的时候,会将数组作为参数传个函数,比如:我要实现一个冒泡排序
4.1 冒泡排序的思想
冒泡排序---两两相邻的元素进行比较
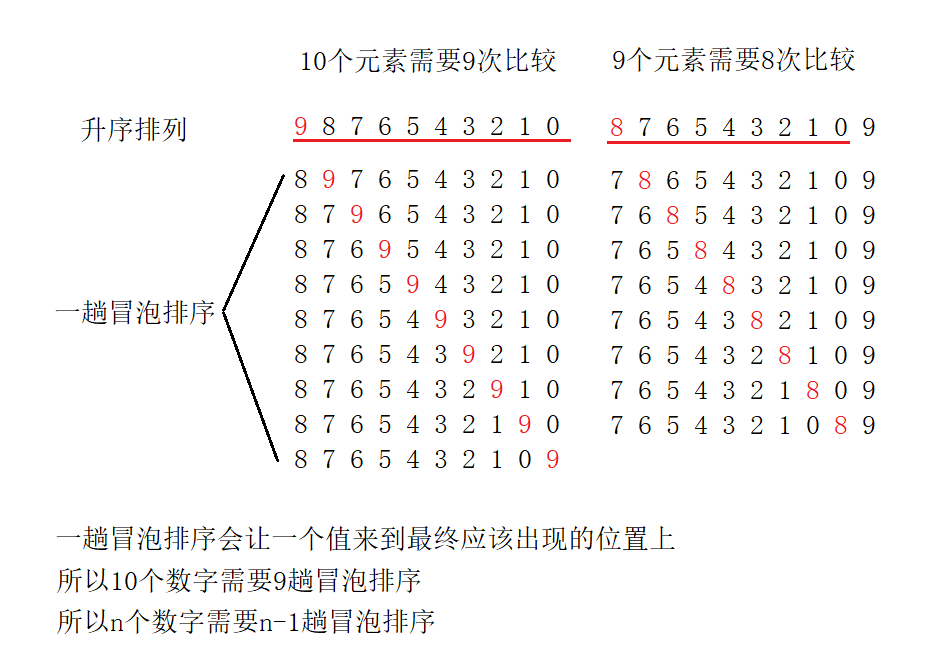
4.2 冒泡排序代码
接着我们来书写代码
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);//10
//输入数据
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//排序
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
//输出结果
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
成功实现所需功能,接着我们就冒泡排序封装在函数中尝试一下:
void bubble_sort(int arr[10])
{
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
//输入数据
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
scanf("%d", &arr[i]);
}
//冒泡排序-升序
bubble_sort(arr);//让这个函数来完成数组arr中数据的排序
//输出结果
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}再次运行,我们发现

并没有按照我们预期的那样,成功实现,那么问题出现在哪里了呢?调试发现sz=1!数组大小怎么会为1呢?

难道数组作为函数参数的时候,不是把整个数组的传递过去?
4.3 探索数组名
int main()
{
int arr[10] = { 1,2,3,4,5,6 };
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("%p\n", &arr[0]);
printf("%p\n", &arr[0]+1);
printf("%p\n", &arr);//数组的地址
printf("%p\n", &arr+1);//+1,跳过整个数组
printf("%d\n", sizeof(arr));
return 0;
}运行发现
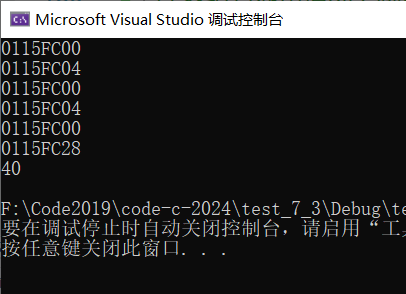
数组名的地址在一般情况下就是数组的首地址,而&arr则取出的是整个数组的地址,这一点上可以通过+1来证明,&arr+1运行后的地址减去&arr的地址,刚好是40,正是包含10个整型元素的一个数组的大小
//数组名该怎么理解? //数组名通常情况下就是数组首元素的地址 //但是有2个例外: //1. sizeof(数组名),数组名单独放在sizeof()内部,这里的数组名表示整个数组,计算的是整个数组的大小 //2. &数组名,这里的数组名也表示整个数组,这里取出的是整个数组的地址 //除此之外所有遇到的数组名都表示数组首元素的地址
4.4 冒泡排序代码(封装在函数形式)
void bubble_sort(int arr[10], int sz)//这里的arr的本质是指针
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//冒泡排序 - 升序
//趟数
//arr作为数组进行了传参
//数组传参,传递的是地址,传递的是首元素的地址
//
bubble_sort(arr, sz);//arr 是数组首元素的地址
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}我们只要将数组大小在主函数计算后,传到函数中就可以解决这个问题了
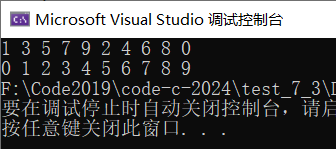
成功!
那我们再思考一下,面对下面的这种特殊情况可以更加优化一点吗?
0 1 2 3 4 5 6 7 8 9//初始序列就是符合要求的升序序列void bubble_sort(int* arr, int sz)//这里的arr的本质是指针
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
//每一趟开始前就假设已经有序了
int flag = 1;
//一趟每部比较的对数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = 0;
}
}
if (flag == 1)
break;//序列已经有序
}
}
int main()
{
int arr[10] = { 0 };
//输入
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//冒泡排序 - 升序
//趟数
//arr作为数组进行了传参
//数组传参,传递的是地址,传递的是首元素的地址
//
bubble_sort(arr, sz);//arr 是数组首元素的地址
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}没错只要在每次冒泡排序前加上一个标志就能解决这个特殊情况了,效率会有所提高!!!
数组的讲解就到这里啦!!!如果这篇文章对你有收获的话,就给小周一键三连吧!!!!!
敬请期待接下来的三子棋和扫雷游戏哦!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









