[root@master ~]# hive
Logging initialized using configuration in jar:file:/usr/local/soft/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive> create external table students_hbase(
> id string,
> name string,
> age string,
> gender string,
> clazz string
> ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> with serdeproperties ("hbase.columns.mapping" = "
> :key,
> info:name,
> info:age,
> info:gender,
> info:clazz
> ")
> tblproperties("hbase.table.name" = "default:stu");
OK
Time taken: 1.402 seconds
hive> show tables;
OK
students_hbase
Time taken: 0.077 seconds, Fetched: 1 row(s)
hive> desc students_hbase;
OK
id string from deserializer
name string from deserializer
age string from deserializer
gender string from deserializer
clazz string from deserializer
Time taken: 0.093 seconds, Fetched: 5 row(s)
hive> select * from students_hbase limit 10;
OK
1500100001 施笑槐 22 女 文科六班
1500100002 吕金鹏 24 男 文科六班
1500100003 单乐蕊 22 女 理科六班
1500100004 葛德曜 24 男 理科三班
1500100005 宣谷芹 22 女 理科五班
1500100006 边昂雄 21 男 理科二班
1500100007 尚孤风 23 女 文科六班
1500100008 符半双 22 女 理科六班
1500100009 沈德昌 21 男 理科一班
1500100010 羿彦昌 23 男 理科六班
Time taken: 0.179 seconds, Fetched: 10 row(s)
hive> select clazz,gender,count(*) from students_hbase group by clazz,gender;
OK
文科一班 女 41
文科一班 男 31
文科三班 女 44
文科三班 男 50
文科二班 女 38
文科二班 男 49
文科五班 女 41
文科五班 男 43
文科六班 女 49
文科六班 男 55
文科四班 女 42
文科四班 男 39
理科一班 女 47
理科一班 男 31
理科三班 女 33
理科三班 男 35
理科二班 女 43
理科二班 男 36
理科五班 女 37
理科五班 男 33
理科六班 女 37
理科六班 男 55
理科四班 女 41
理科四班 男 50
Time taken: 35.317 seconds, Fetched: 24 row(s)
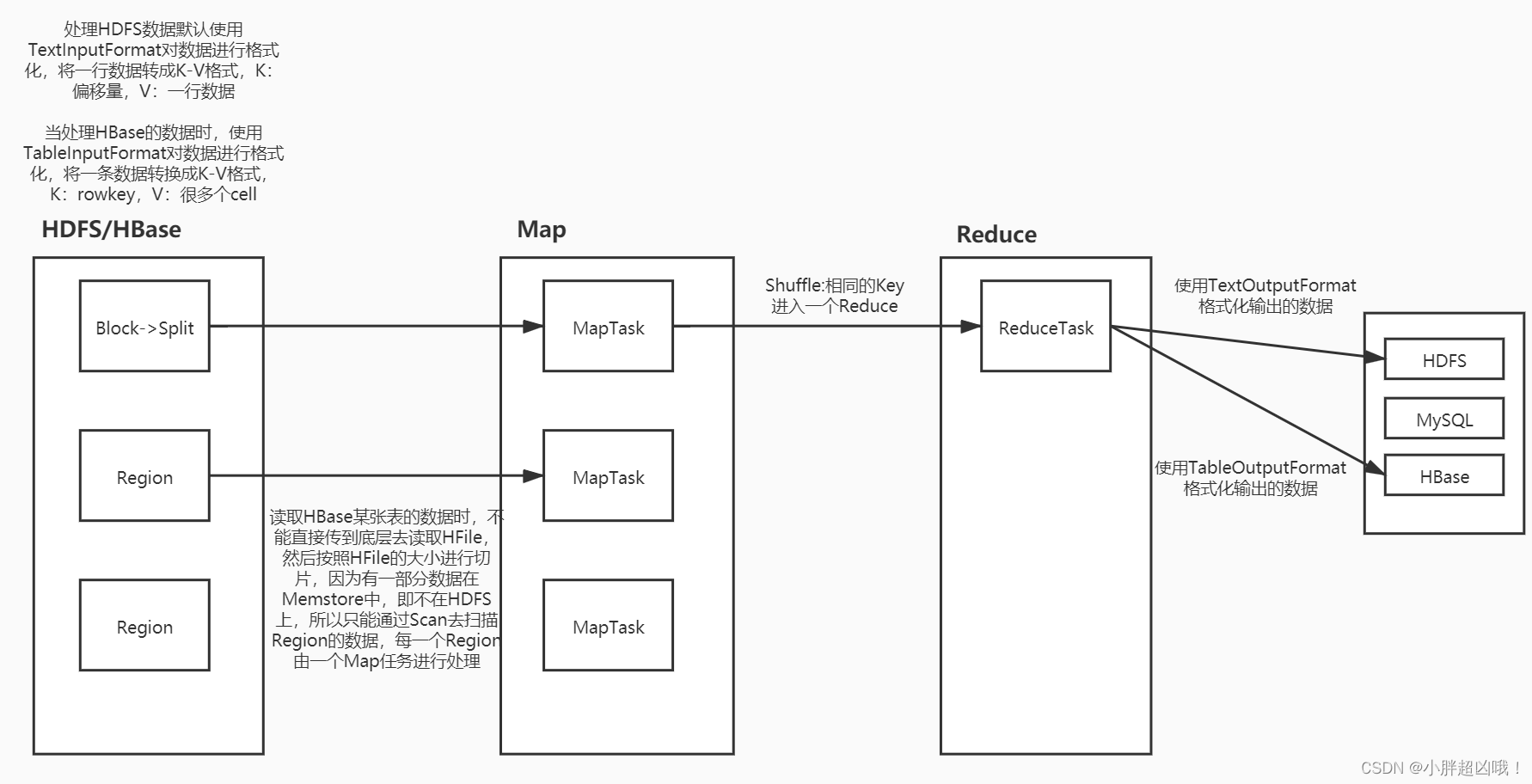
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version> 1.4.6</version>
</dependency>
package com.shujia;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//统计班级人数 最后写入HDFS
public class Demo05MRReadHBase {
//Map端
public static class ReadHBaseMapper extends TableMapper<Text, IntWritable>{
@Override
/**
* key 对应rowkey
* value 对应hbase的一条数据
*/
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes()));
context.write(new Text(clazz),new IntWritable(1));
}
}
//Reduce端
public static class MyReducer extends Reducer<Text,IntWritable,Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int cnt=0;
for (IntWritable value : values) {
cnt+=value.get();
}
context.write(key,new IntWritable(cnt));
}
}
//Driver端
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181");
conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJobName("Demo05MRReadHBase");
job.setJarByClass(Demo05MRReadHBase.class);
TableName stu = TableName.valueOf("stu");
Scan scan = new Scan();
//配置Map端
TableMapReduceUtil.initTableMapperJob(
stu
,scan
,ReadHBaseMapper.class
,Text.class
,IntWritable.class
,job
);
//配置Reduce端
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//配置输入输出路径
Path path = new Path("/data/mr/stu_cnt");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(path)){
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job,path);
job.waitForCompletion(true);
}
}
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 带依赖jars插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
[root@master jars]# ls
hadoop-1.0-SNAPSHOT.jar HIve-1.0-SNAPSHOT.jar
HBase-1.0-SNAPSHOT.jar HiveUDF-1.0.jar
[root@master jars]# rz -E
rz waiting to receive.
[root@master jars]# ls
hadoop-1.0-SNAPSHOT.jar
HBase-1.0-SNAPSHOT.jar
HBase-1.0-SNAPSHOT-jar-with-dependencies.jar
HIve-1.0-SNAPSHOT.jar
HiveUDF-1.0.jar
[root@master jars]# hadoop jar HBase-1.0-SNAPSHOT-jar-with-dependencies.jar com.shujia.Demo05MRReadHBase
[root@master jars]# hdfs dfs -cat /data/mr/stu_cnt/*
文科一班 72
文科三班 94
文科二班 87
文科五班 84
文科六班 104
文科四班 81
理科一班 78
理科三班 68
理科二班 79
理科五班 70
理科六班 92
理科四班 91

























 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









