







目录
8.find_first_of,find_last_of 和 find_first_not_of,find_last_not_of
C语言中的字符串
C语言中,字符串是以’\0’结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数。
标准库中的string类
string类
1. 字符串是表示字符序列的类。
2. 标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了 专门用于操作单字节字符字符串的设计特性。
3. string类是使用char(即作为它的字符类型,使用它的默认char_traits和分配器类型(关于模 板的更多信息,请参阅basic_string)。
4. string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用 char_traits和allocator作为basic_string的默认参数(根于更多的模板信息请参考 basic_string)。
5. 注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如UTF-8) 的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际 编码的字符)来操作。
string类其实是
basic_string这个类模板实例化出来的类的一个typedef。
此外,除了string,wstring u16string u32 string它们都是
basic_string这个类模板实例化出来的模板类,区别在于它们对应的模板参数的类型不同。它们的底层就是一个动态的字符数组,string呢就是一个
char类型的字符数组,wstring就是对应的wchar_t的字符数组,u16string就是char16_t的字符数组,u32string就是char32_t的字符数组。


为什么有这么多种的string类呢?
C语言阶段有了解过ASCII编码,这里面的所有符号和字母都一个对应的ASCII码值。
char s[] = "hello world";内存里存的并不是字母本身,而是它们对应的ASCII码值(这里以16进制显示)。那我们去打印的时候其实是去对照这个表找到这个ASCII码对应的字母然后打印出来。
最早的计算机是美国人发明的,他们的语言是英语,英语,不就是26个英文字母+一大堆标点符号组成的吗?另外,计算机刚刚开始发明,美国人只要能解决他们的问题就行,所以就有了现在的简单字符。而计算机只认识二进制,而人只认识字符。所以,一定要有一套规则,用来进行二进制和字符的转化,这个就叫做ASCII码表。
那这样的话,随着计算机的发展,只有一个ASCII编码还够用吗?世界上还有很多国家,很多种语言呢。比如现在我们要让计算机能显示中文,用ASCII码就不行了。而且ASCII只定义了128个字符(一个字节就够用了),中国的汉字大约有10万个呢!那基于这样的原因呢,有人就又发明了Unicode——万国码(兼容ASCII)。
各个国家的情况也不同,有的国家文字少,有的多,所以Unicode又进行了划分,分为
UTF-8、UTF-16、UTF-32这些。所以呢,为了应对这些不同的编码,就产生了这些不同的字符类型,所以就有了basic_string这个泛型字符串类模板,我们可以用它实例化出不同类型的字符串类。




总结:
1. string是表示字符串的字符串类
2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。3. string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator> string;
4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include头文件以及using namespace std;
string类的常用接口说明
string类对象的常见构造

| (constructor)函数名称 | 功能说明 |
| string() 空字符串构造函数(默认构造函数) | 构造空的string类对象,即空字符串 |
| string(const string&s) (重点) | 拷贝构造函数 |
| string (const string& str, size_t pos, size_t len = npos) | 复制 str 中从字符位置 pos 开始并跨越 len 字符的部分(如果 str 太短或 len 是string::npos,则直到 str 的末尾) |
| string(const char* s) (重点) | 用C-string来构造string类对象 |
| string (const char* s, size_t n) | 拿s指向字符串的前n个字符去构造string对象 |
| string (size_t n, char c) | 拿n个字符c去构造string对象 |
template <class InputIterator>string (InputIterator first, InputIterator last) | 迭代器初始化 |
int main() { //空字符串string() cout << "string():" << endl; string s1; cout << "s1 = " << s1 << endl; cout << "-----------------------------------------------" << endl; //string(const char*) cout << "string(const char*):" << endl; string s2("hello world"); string s3 = "hello world";//单参数构造函数的隐式类型转换 cout << "s2 = " << s2 << endl; cout << "s3 = " << s3 << endl; cout << "-----------------------------------------------" << endl; //string (const string& str, size_t pos, size_t len = npos) cout << "string (const string& str, size_t pos, size_t len = npos):" << endl; string s4(s2, 0, 7); string s5(s2, 0,100);//str比较短 string s6(s2, 0);//不传参,len缺省值默认为npos cout << "s4 = " << s4 << endl; cout << "s5 = " << s5<< endl; cout << "s6 = " << s6<< endl; cout << "-----------------------------------------------" << endl; //string(const char* s, size_t n) cout << "string(const char* s, size_t n):" << endl; string s7("hello world", 8); cout << "s7 = " << s7 << endl; cout << "-----------------------------------------------" << endl; //string (size_t n, char c) cout << "string (size_t n, char c):" << endl; string s8(11,'x'); cout << "s8 = " << s8 << endl; cout << "-----------------------------------------------" << endl; //string(const string & str) cout << "string(const string & str):" << endl; string s9 = "hello world!"; string s10(s9); cout << "s10 = " << s10 << endl; return 0; }

关于npos: 它是一个静态成员变量,值是-1,但是因为这里它的类型是
size_t(无符号整型),所以它在这里其实是整型的最大值,而字符串长度是不可能大于这个值的,所以这里也是会取到结尾。

string类对象的容量操作

| 函数名称 | 功能说明 |
| size | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty | 检测字符串是否为空串,是返回true,否则返回false |
| clear | 清空有效字符 |
| reserve | 为字符串预留空间 |
| resize | 将有效字符的个数该成n个,多出的空间用字符c填充 |
1.size和length
size和length都是返回字符串有效字符长度。
int main() { string s("hello world"); cout <<"size:" << s.size() << endl; cout << "length:" << s.length() << endl; return 0; }
那他们俩的功能一样,为什么要设置两个呢?
其实跟一些历史原因有关,string呢其实出现的比STL早,string其实严格来说是不属于STL的,它是C++标准库产生的,在STL出现之前就已经在标准库出现了。
string其实最早之前设计的就是length,因为字符串的长度嘛,用length就很合适。但是后面STL出现之后,里面的其它数据结构用的都是size,那为了保持一致,就给string也增加了一个size。所以size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。

2.max_size
int main() { string s("hello world"); //cout <<"size:" << s.size() << endl; //cout << "length:" << s.length() << endl; cout << "max_size:" << s.max_size() << endl; return 0; }
真正在实际中字符串可以并不能开这么长,而且在不同平台下这个值也可能不一样。

3.capacity
返回当前string对象的容量(即当前给它分配的空间有多大)
我们看到这里返回的s的容量是15,但是它是不包含'\0'的空间的,因为它认为
'\0'不是有效字符,所以这里实际上是16个字节的空间。


4.resize和reserve
vs和g++下string结构的说明
注意:下述结构是在32位平台下进行验证,32位平台下指针占4个字节
vs下string的结构:
string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字
符串的存储空间:
1.当字符串长度小于16时,使用内部固定的字符数组来存放
2.当字符串长度大于等于16时,从堆上开辟空间
union _Bxty
{ // storage for small buffer or pointer to larger one
value_type _Buf[_BUF_SIZE];
pointer _Ptr;
char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;
这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
最后:还有一个指针做一些其他事情。
故总共占16+4+4+4=28个字节
g++下string的结构
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
1.空间总大小
2.字符串有效长度
3.引用计数struct _Rep_base { size_type _M_length; size_type _M_capacity; _Atomic_word _M_refcount; };4.指向堆空间的指针,用来存储字符串。

string扩容容量测试:
int main()
{
string s;
size_t old = s.capacity();
cout << "capacity:" << old << endl;
for (int i = 0; i < 100; i++)
{
s.push_back('x');
if (s.capacity() != old)
{
cout << "new capacity:" << s.capacity() << endl;
old = s.capacity();
}
}
return 0;
}
首先我们上面说过了,它这里没有算\0的空间,所以这里看到的容量为15实际为16,容量31但实际是32 。
其次我们看到它好像第一次扩容是2倍扩,后面每次都差不多是一个1.5倍扩。但其实在VS上,它这个结构跟我们理解的顺序表还是有一点不同,刚开始的数据并没有存到动态开辟的数组上,而是存到上面所说的_Buf数组里面。我们可以调式观察一下:

我们看到,它是存到这个_Buf数组里面了,这个数组的大小是16(不带
\0就是15),所以如果string对象的大小如果小于等于16,就存到这个Buf数组上,大于16才存到ptr指向的动态开辟的数组上,就不往Buf里面存了。这样虽然可能多开辟16字节空间,但可以避免小空间多次扩容减少内存碎片。
reserve:
上面我们看到如果我们一直插入数据他是会去不断扩容的,那其实我们是有方法去减少扩容的。如果我们知道要插入多少数据的话,我们可以去调
reserve

reserve可以帮助我们更改容量大小,这样如果我们知道需要多大的空间,就可以一次开到位,就不用再一次一次的扩容了。
就拿我们上面那个例子来说:我们现在直接reserve100个容量,但是注意,我们指定100,它不一定开的就是100,可能由于对齐等一些原因多开一些空间,但是肯定不会比100小。
int main()
{
string s;
s.reserve(100);
size_t old = s.capacity();
cout << "capacity:" << old << endl;
for (int i = 0; i < 100; i++)
{
s.push_back('x');
if (s.capacity() != old)
{
cout << "new capacity:" << s.capacity() << endl;
old = s.capacity();
}
}
return 0;
}
如果我们知道需要多少空间的前提下,
reserve就可以帮助我们提前把空间开好,然后就可以减少扩容,提升效率,因为频繁扩容也是需要付出代价的。另外reserve只是开空间改变容量,它是不会改变size的。
resize:
1.reserve可以去改变容量,帮我们开空间;那resize呢,不仅可以开空间,而且还能对开好的空间进行初始化。

int main()
{
string s1("hello world");
s1.reserve(100);
size_t capacity1 = s1.capacity();
size_t sz1 = s1.size();
cout << "after reserve capacity:" << capacity1 << endl;
cout << "after reserve size:" << sz1<< endl;
string s2("hello world");
s2.resize(100);
size_t capacity2 = s2.capacity();
size_t sz2 = s2.size();
cout << "after resize capacity:" << capacity2 << endl;
cout << "after resize size:" << sz2 << endl;
return 0;
}
我们看到
capacity和size都变了,因为它是会对开好的空间进行初始化的,相当于插入了新字符,所以size也变了。

2.这里我们没有指定第二个参数,既要填入的字符,默认给的是
\0,当然我们也可以自己指定要填入的字符:


3.当然我们刚才传的第一个参数n是大于当前字符串长度的,那么他就去扩容,如果我们传的n小于当前字符串长度,它还可以帮我们删除多出来的内容:
int main()
{
string s2("hello world");
s2.resize(100,'*');
size_t capacity2 = s2.capacity();
size_t sz2 = s2.size();
cout << "after resize capacity:" << capacity2 << endl;
cout << "after resize size:" << sz2 << endl;
cout << "s2:" << s2 << endl;
cout << endl;
s2.resize(3);
size_t capacity3 = s2.capacity();
size_t sz3 = s2.size();
cout << "after resize capacity:" << capacity3 << endl;
cout << "after resize size:" << sz3 << endl;
cout << "s2:" << s2 << endl;
return 0;
}
我们看到只是size变了,capacity并没有改变。因为一般情况下是不会轻易缩容的,缩容的话一般是不支持原地缩的,我们之前学习realloc扩容有原地扩和异地扩两种方式,而且原地扩也是有条件的,后面要有足够的空间才能原地扩。而缩容呢?可以原地缩吗?由于底层内存管理的一些原因,是没法原地缩的。如果支持原地缩,是不是就要支持释放一部分,我们申请一块空间,不用了只释放其中的一部分。但是是不支持只释放一部分的,就像我们free是不是要求传的指针必须是指向其实位置的。所以如果真的要缩容的话,只能异地缩,就是开一块新的小空间,把需要的数据拷贝过去,然后把原空间释放掉。所以缩容是要付出性能的代价的,系统原生是不支持的,我们需要自己去搞。所以不到万不得已不要轻易缩容。
5.shrink_to_fit
string是提供了一个可以缩容的接口的——
shrink_to_fitint main() { string s2("hello world"); s2.resize(100,'*'); cout << "after resize capacity:" << s2.capacity() << endl; cout << "after resize size:" << s2.size() << endl; cout << "s2:" << s2 << endl; cout << endl; s2.resize(3); cout << "after resize capacity:" << s2.capacity()<< endl; cout << "after resize size:" << s2.size() << endl; cout << "s2:" << s2 << endl; cout << endl; s2.shrink_to_fit(); cout << "after resize capacity:" << s2.capacity() << endl; cout << "after resize size:" << s2.size() << endl; cout << "s2:" << s2 << endl; return 0; }
shrink是异地扩容,以空间换时间,尽量少用。


6.clear
clear会清空有效字符size减为0但capacity不变
int main() { string s2("hello world"); s2.resize(100,'*'); cout << "after resize capacity:" << s2.capacity() << endl; cout << "after resize size:" << s2.size() << endl; cout << "s2:" << s2 << endl; cout << endl; s2.clear(); cout << "after resize capacity:" << s2.capacity() << endl; cout << "after resize size:" << s2.size() << endl; cout << "s2:" << s2 << endl; return 0; }


7.empty
empty:检测字符串释放为空串,是返回true,否则返回false
int main() { string s2("hello world"); s2.resize(100,'*'); s2.clear(); cout << "s2:" << s2 << endl; if(s2.empty()) cout <<"s2是空字符串" << endl; }


string类对象的遍历操作
| 函数名称 | 功能说明 |
| operator[] | 返回pos位置的字符,const string类对象调用 |
| begin+ end | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| rbegin + rend | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
那现在大家思考一个问题,如果我们想遍历一个string对象,可以有哪些方式?
1.用[ ]遍历
int main() { string s2("hello world"); for (int i = 0; i < s2.size(); i++) { cout << s2[i] << endl; } }

2.范围for。
int main() { string s2("hello world"); for (auto e : s2) { cout << e << endl; } }

3.迭代器
正向迭代器
int main() { string s1("hello world"); string::iterator it = s1.begin(); while (it != s1.end()) { cout << *it << " "; it++; } return 0; }
首先这里的it就是我们定义的一个string类的迭代器(
string::iterator是类型),那这么理解迭代器呢?现阶段可以认为它是一个像指针一样的东西(不一定是指针)。begin:返回指向字符串第一个字符的迭代器。
end:返回指向最后一个字符后面位置的迭代器。
范围for其实它的底层也是使用迭代器实现。





反向迭代器
int main() { string s1("hello world"); string::reverse_iterator it = s1.rbegin(); while (it != s1.rend()) { cout << *it << " "; it++; } return 0; }
注意:虽然是反向迭代器,但it依然是++进行遍历而不是--
正向迭代器也可以完成反向遍历,但不如反向迭代器直观简便。
int main() { string s1("hello world"); string::iterator it = s1.end()-1; while (it != s1.begin()) { cout << *it << " "; it--; } return 0; }




const迭代器(正向&反向)
我们看到函数func的形参s是const string对象的引用,
const对象不能被修改,那我们上面讲普通迭代器的时候说了,可以认为它是一个像指针一样的东西,那我们对它解引用是不是就可以修改它了,所以这里我们就不能用普通迭代器了,相当于权限的放大,所以这里才报错了。
我们看到begin是有两个版本的,如果是const对象调用begin,那么返回的是const迭代器const_iterator。这里s调用begin返回的是const迭代器,我们用const迭代器迭代器接收就行了。普通迭代器可以读容器的数据,也可以去修改,但是const迭代器就只能读,不能修改。
void Print(const string& s) { string::const_iterator it = s.begin(); while (it != s.end()) { cout << *it << " "; it++; } } int main() { string s1("hello world"); Print(s1); return 0; }
反向迭代器也是同理:
void Print(const string& s) { string::const_reverse_iterator it = s.rbegin(); while (it != s.rend()) { cout << *it << " "; it++; } } int main() { string s1("hello world"); Print(s1); return 0; }



由于迭代器的类型有点长,可以用auto简化一下:
void Print(const string& s) { auto it = s.begin(); while (it != s.end()) { cout << *it << " "; it++; } } int main() { string s1("hello world"); Print(s1); return 0; }

我们看到这里C++11又提供了一套迭代器:cbegin cend crbegin crend,它们只返回const迭代器。
比如正向迭代器,它期望普通对象去调用begin和end,const对象就调cbegin和cend的那一套,更规范一点,但是不必要,而且一般也不太喜欢用这些新的。
string类对象的访问操作

1.operator[]

int main()
{
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
s1[i]++;
cout << s1[i] << " ";
}
cout << endl;
return 0;
}

int main()
{
const string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
s1[i]++;
cout << s1[i] << " ";
}
cout << endl;
return 0;
}

operator[]是有普通版本和const版本的,普通对象调[]就返回char&,可以去修改它,const对象就返回const char&,不能修改。
2.at
at作用跟[]是一样的,而且它同样也有const和非const版本:int main() { string s1("hello world"); for (int i = 0; i < s1.size(); i++) { s1.at(i)++; cout << s1.at(i) << " "; } cout << endl; return 0; }
两者区别在于:用
[]如果越界访问的话是直接报错的,它内部是断言去判断的。at如果报错会抛异常,可以被捕获。



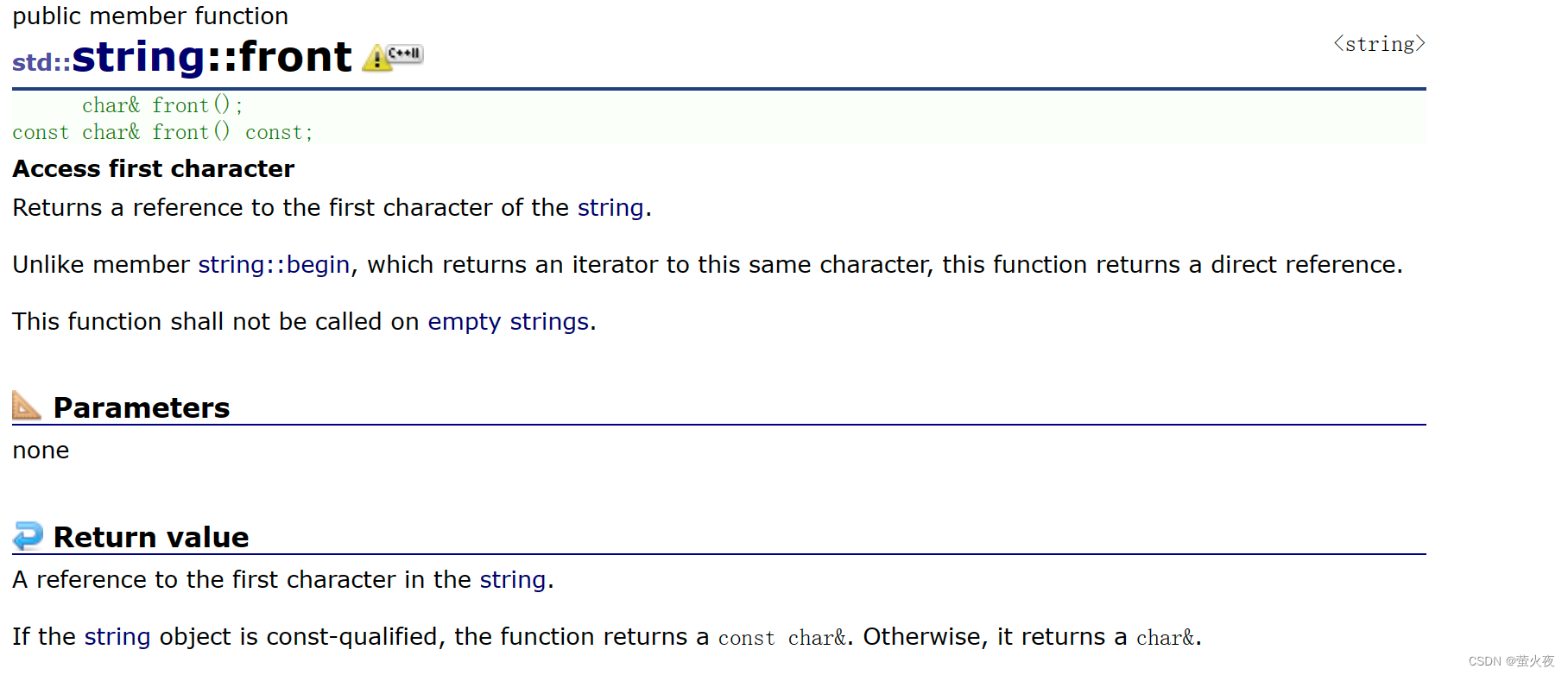
3.back和front
int main()
{
std::string str("hello world.");
str.front() = 'H';
str.back() = '!';
std::cout << str << '\n';
return 0;
}
string类对象的修改操作
| 函数名称 | 功能说明 |
| operator+= | 在字符串后追加字符串str |
| append | 在字符串后追加一个字符串 |
| push_back | 在字符串后尾插字符c |
| assign | 为字符串分配一个新值,替换其当前内容。 |
| replace | |
| insert | |
| erase | |
| swap | |
| pop_back |
0.npos
先解释npos是什么,npos会在一些函数的缺省参数中用到。
npos是一个const静态成员变量,值为-1,但是呢,因为这里它的类型是size_t(无符号整型),所以它在这里其实是整型的最大值。有些函数参数没有传参的话默认传npos,会将操作执行到字符串末尾,比如erase:
如果调用erase不传参,意为字符串从0位置到末尾全部删除。
int main() { std::string s1 = "hello world"; s1.erase(); cout << s1<<endl; }


1.push_back
追加一个字符

int main()
{
string str("hello world");
str.push_back('!');;
cout << str << endl;
return 0;
} 2.append
2.append
追加一个字符串

int main()
{
std::string str;
std::string str2 = "Writing ";
std::string str3 = "print 10 and then 5 more";
// used in the same order as described above:
str.append(str2); // "Writing "
std::cout << str << '\n';
str.clear();
str.append(str3, 6, 2); // "10"
std::cout << str << '\n';
str.clear();
str.append("dots are cool", 4); // "dots"
std::cout << str << '\n';
str.clear();
str.append("here: "); // "here: "
std::cout << str << '\n';
str.clear();
str.append(10u, '.'); // ".........."
std::cout << str << '\n';
str.clear();
str.append(str3.begin() + 8, str3.end()); // " and then 5 more"
std::cout << str << '\n';
return 0;
} 3.operator+=
3.operator+=
相比于push_back和append,+=更方便。不过其实+=的底层也是用的
push_back和append,对他们进行了一层封装。

int main()
{
std::string name("John");
std::string family("Smith");
name += " K. "; // c-string
name += family; // string
name += '\n'; // character
std::cout << name;
return 0;
}
4. insert和erase


int main()
{
std::string str("This is an example sentence.");
std::cout << str << '\n';
str.erase(10, 8);//从pos位置开始删除8个字符
std::cout << str << '\n';// "This is an example sentence."
str.erase(str.begin() + 9);//删除第10个位置的字符
std::cout << str << '\n';// "This is a sentence."
str.erase(str.begin() + 5, str.end() - 9);//删除[5,9]区间的字符
std::cout << str << '\n';// "This sentence."
str.erase(4);//删除下标为4字符后面的所有字节
std::cout << str << '\n';// "This"
return 0;
}
对于string来说,频繁使用insert和erase好不好?
那其实是不推荐经常使用insert的,因为string底层是字符数组,插入元素要挪动数据,效率是比较低的,所以呢insert我们能少用就少用。
5.assign
assign其实是一种变相的赋值

int main()
{
std::string str("xxxxxxx");
std::string base = "The quick brown fox jumps over a lazy dog.";
str.assign(base);
std::cout << str << '\n';
str.assign(base, 4, 15);
std::cout << str << '\n';
return 0;
}
6.std::swap与std::string::swap
string里面呢,还有一个成员函数叫做swap:

int main()
{
string s1 = "hello world";
string s2 = "************";
cout << "before swap:"<<endl;
cout << "s1=" << s1 << endl;
cout << "s2=" << s2 << endl;
cout << endl;
cout << "after swap:" << endl;
s1.swap(s2);
cout << "s1=" << s1 << endl;
cout << "s2=" << s2 << endl;
return 0;
}
那除了这个swap之外,C++的库里面也有一个swap,它是一个模板函数。
所以我们也可以这样交换两个string对象:
int main()
{
string s1 = "hello world";
string s2 = "************";
cout << "before swap:"<<endl;
cout << "s1=" << s1 << endl;
cout << "s2=" << s2 << endl;
cout << endl;
cout << "after swap:" << endl;
//s1.swap(s2);
swap(s1, s2);
cout << "s1=" << s1 << endl;
cout << "s2=" << s2 << endl;
return 0;
}
这两个swap哪一个效率更高一点?
那肯定是string的swap是更高效的一点的,因为string::swap作为string的成员函数,它想交换这两个对象,可以直接改变指针的指向(交换它们两个的成员变量)。
库里的swap 是构造一个临时变量,然后又有两个赋值,而string的拷贝是需要深拷贝的,所以它这里是比较低效的。
但设计者为了避免对string调用效率低的swap,又专门重载了一个string 版本的swap:

int main()
{
string s1 = "hello world";
string s2 = "************";
cout << "before swap:"<<endl;
cout << "s1=" << &s1 << endl;
cout << "s2=" << &s2 << endl;
cout << endl;
cout << "after swap:" << endl;
swap(s1, s2);
cout << "s1=" << &s1 << endl;
cout << "s2=" << &s2 << endl;
return 0;
} 
可以看到调用string参数的std::swap后地址发生了交换,如果使用的是模板swap,交换后的地址应该为一个新的地址,因为产生了临时变量。
7.replace、find、rfind、substr
| find + npos | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
replace其实就是可以把字符串中的一部分替换成新内容。

举其中两个例子:
在pos位置往后替换len个字符为str,len如果超过原字符串长度默认pos往后全替换,pos如果超出字符串长度会报错。
int main()
{
string s1("hello world");
s1.replace(5, 1, "%%%");
string s2("hello world");
string s3("string");
s2.replace(6, 100, s3);
cout << s1 << endl;
cout << s2 << endl;
return 0;
}


replace不建议多用,首先可能会需要挪动数据,其次,空间如果不够还得扩容,所以我们也尽量避免去用。
find:
find可以在字符串里查找字串或者字符,返回对应的下标。找不到返回npos

pos用来指定我们开始查找的位置的,pos的缺省值是0,我们自己不指定那就默认从0开始,我们指定了,就从指定的位置开始找。
int main()
{
string s1("hello world");
cout << s1.find('l') << endl;
cout << s1.find('l', 6) << endl;
cout << s1.find("world") << endl;
return 0;
}

rfind:
rfind和find区别在于find是从前往后找第一个匹配项,而rfind是从后往前找倒数第一个匹配项。
int main()
{
string s1("hello world hello");
cout << s1.rfind('l') << endl;
cout << s1.rfind('l', 5) << endl;
cout << s1.rfind("hello") << endl;
return 0;
}
substr:
它可以帮助我们获取string对象中指定的一个子串。
那有了substr,结合find可以实现这样一个场景:分离网址的协议、域名、资源名。
int main()
{
string s3("https://legacy.cplusplus.com/reference/string/string/rfind/");
// 协议
// 域名
// 资源名
string sub1, sub2, sub3;
size_t i1 = s3.find(':');
if (i1 != string::npos)
sub1 = s3.substr(0, i1);
else
cout << "没有找到i1" << endl;
size_t i2 = s3.find('/', i1 + 3);
if (i2 != string::npos)
sub2 = s3.substr(i1 + 3, i2 - (i1 + 3));
else
cout << "没有找到i2" << endl;
sub3 = s3.substr(i2 + 1);
cout << sub1 << endl;
cout << sub2 << endl;
cout << sub3 << endl;
return 0;
}8.find_first_of,find_last_of 和 find_first_not_of,find_last_not_of

find_fist_of:
从第一个字符寻找与str中匹配的任意字符并返回下标位置。

int main()
{
std::string str("Please, replace the vowels in this sentence by asterisks.");
std::size_t found = str.find_first_of("aeiou");
while (found != std::string::npos)
{
str[found] = '*';
found = str.find_first_of("aeiou", found + 1);
}
std::cout << str << '\n';
return 0;
}
find_last_of:
从最后一个字符寻找与str中匹配的任意字符并返回下标位置。

可以实现一个分离文件的文件名和路径的函数
void SplitFilename(const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0, found) << '\n';
std::cout << " file: " << str.substr(found + 1) << '\n';
}
int main()
{
std::string str1("/usr/bin/man");
std::string str2("c:\\windows\\winhelp.exe");
SplitFilename(str1);
SplitFilename(str2);
return 0;
}
find_first_not_of:
寻找第一个不匹配str中任意字符的位置

int main()
{
std::string str("look for non-alphabetic characters...");
std::size_t found = str.find_first_not_of("abcdefghijklmnopqrstuvwxyz ");
if (found != std::string::npos)
{
std::cout << "The first non-alphabetic character is : " << str[found]<<endl;
std::cout << "At position: " << found << '\n';
}
return 0;
}find_last_not_of:
寻找最后一个不匹配str中任意字符的位置

9 c_str
返回一个指向当前string对象对应的字符数组的指针,类型为
const char*。

想打印一个string对象,就可以有这样两种方式: 
但如果是这样:
int main()
{
string s1("hello world");
s1 += '\0';
s1 += '\0';
s1 += "*******";
cout << s1 << endl;
cout << s1.c_str() << endl;
return 0;
}


因为第一种方式直接打印string对象s1,它是去看s1对应的size的,size是多大,总共有多少字符,全部打印完。但是第二种打印
c_str返回的const char*的指针,它是遇到'\0'就停止了。可以理解成c_str就是返回C格式字符串。
10. getline 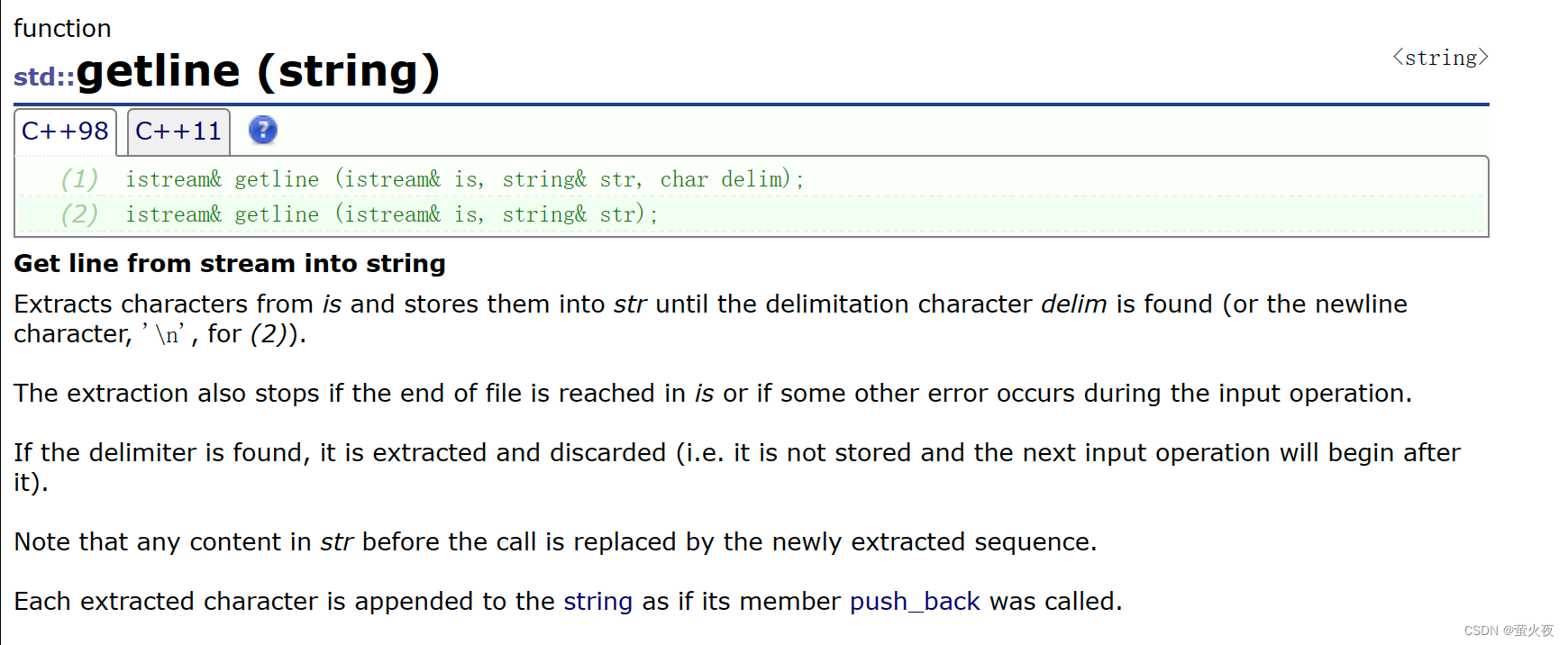
int main()
{
string line;
// 不要使用cin>>line,因为会它遇到空格就结束了
while(cin>>line)
{
size_t pos = line.rfind(' ');
size_t len = line.size() - pos -1 ;
cout << len << endl;
}
return 0;
}
C语言里的scanf,包括这里的cin,输入的时候默认是以空格或者换行来判定读取结束。cin读取不到空格,此代码相当于输入了两个只有一个单词的字符串,所以输出了两个值。
这样getline就起到作用了:
getline呢它读取到空格才结束,它还支持我们自己指定结束符。

int main()
{
string line;
// 不要使用cin>>line,因为会它遇到空格就结束了
// while(cin>>line)
while (getline(cin, line))
{
size_t pos = line.rfind(' ');
size_t len = line.size() - pos -1 ;
cout << len << endl;
}
return 0;
}
















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









