










通过知识注入和歧义学习缓解多模态情感分析
摘要
多模态情绪分析(MSA)利用互补的多模态特征来预测情绪的极性,这主要涉及到语言、视觉和音频模态。现有的多模态融合方法主要考虑不同模态的互补性,而忽略了模态之间的冲突所造成的歧义(即文本模态预测积极情绪,而视觉模态预测消极情绪)。为了很好地减少这些冲突,我们开发了一个新的多模态歧义学习框架,即RMA,通过知识注入和多模态歧义学习解决多模态歧义情绪分析。具体来说,我们引入和过滤外部知识,以增强跨模态情绪极性预测的一致性。即,我们明确地测量歧义,并动态地调整从属模态和主导模态之间的影响,以同时考虑多模态融合过程中多种模态的互补性和歧义。实验证明,我们提出的模型在三个公共多模态情绪分析数据集CMU-MOSI、CMU-MOSEI和MELD上具有优势。
1. 介绍
生物系统通过同时出现的多模态信号来感知世界。语言、视觉和语言模式是日常生活中最常见的三种多模态信号。与生物系统类似,多模态情绪分析(MSA)同时处理多个源信号[1–6]。MSA是情绪分析领域的一个基本而重要的问题,它引起了[7–12]研究者的广泛关注。现有的MSA方法可以分为以多模态表示为中心的方法和以多模态融合为中心的方法。前者的模型是精确和细粒度的表示,以帮助模型预测情绪极性[12–16]。后者的重点是通过跨模态的交互作用来学习跨模态的语义相关性,并通过跨模态的信息传递来增强单模态的表征[7,8,17-19]。
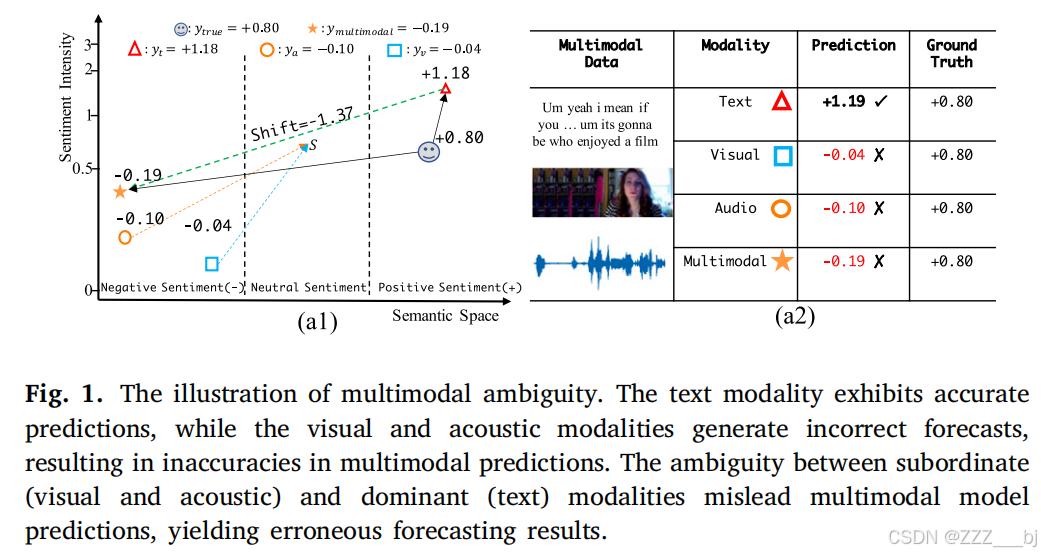
事物都有两面性虽然多模态融合方法通过利用互补的多模态数据有效地提高了多模态情绪分析模型的性能,但它们也会误导使用相互冲突的多模态数据的情绪极性预测。相互冲突的多模态数据可能来自于数据收集或特征提取模型,导致不同的模式来预测不一致的情绪极性。尽管在MSA领域已经取得了实质性进展,但冲突多模态数据产生的歧义[20]对预测结果的误导仍然是一项具有挑战性的任务[19,21,22]。多模态歧义是指模态之间的冲突,例如,当文本模态预测积极情绪,而视觉模态预测消极情绪时。单模态性能的差距是由于提取单模态特征和多模态信号中采用的收集方法的差异。表现优异的模态称为主导模态,而表现不佳的模态称为从属模态。图1显示了多模态歧义过程中的决策过程。使用相互冲突的多模态数据(即主导模态和从属模态)进行联合学习可能会导致歧义,从而误导模型决策。具体来说,我们利用跨模态融合模型[8]和单一transformer[23]来获得多模态和单一模态预测。文本模态与视觉和声学模态的预测结果不一致。文本模态预测+为0.23,视觉模态和声学模态分别预测−为0.24和−为1.01。多模态预测为−0.13,跨模态相互作用导致位移值为−0.36。具有跨模态相互作用的多模态预测会产生错误的预测。我们总结如下:(i)与文本模态(主导模态)相比,视觉和声学的低表现模态(从属模态)可能会导致冲突。(ii)只考虑多模态互补性的多模态融合方法可能会在相互冲突的情况下产生错误的预测。因此,研究将是有意义的: (i)如何为每个模态产生一致的情绪极性预测,以减轻冲突的场景。(ii)如何动态调整互补和冲突的多模态数据的跨模态交互作用,以产生正确的情绪极性预测。
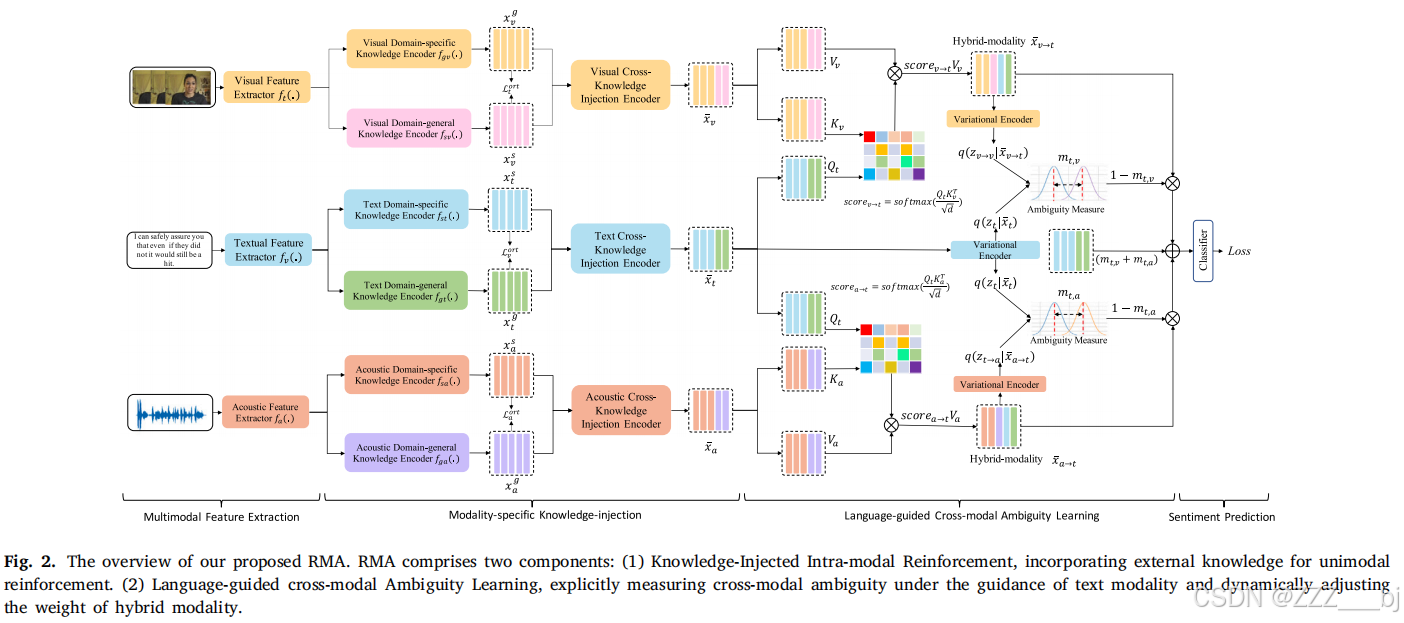
为了回答上述研究问题,我们提出了一种新的多模态歧义学习框架,即RMA,通过知识注入和多模态模糊学习来解决多模态模糊的情绪分析。RMA通过引入和过滤领域通用知识来提高单个模态的性能,这保证了每个模态尽可能多地产生一致的情绪极性预测。(ii)RMA明确地测量了模式之间的歧义,并动态地在冲突的场景中动态调整从属模式对主导模式的影响。具体地说,我们使用一个外部多模态情绪分析数据集来预先训练三个领域通用编码器,以提供外部领域通用知识。我们使用正交损失来确保域通用和域特定的编码器学习一个模态的两个不同的方面。为了避免过分强调领域通用知识,我们设计了一个交叉知识编码器来引入和过滤领域通用知识。为了准确地测量跨模态模糊性,我们设计了一个语言引导的跨模态模糊性学习模块,它明确地测量了主导模态和混合模态之间的模糊性。在冲突场景下,我们根据模糊值动态调整混合模态对优势模态的影响。多模态融合方法通常需要跨模态交互技术来增强模态。例如,当利用视觉模态来加强文本模态时,信息需要从视觉模态转移到文本模态。总之,我们工作的主要贡献可以概括为:
- 我们为每个模态引入和过滤外部域的通用知识,以确保每个模态产生一致的预测结果。
- 我们设计了一个语言引导的跨模态模糊性学习模块,明确地测量了在多模态融合前的主导模式和混合模式之间的模糊性。该模块基于模糊性值动态控制从属模态对主导模态的影响,同时在多模态融合中同时考虑了多模态的互补性和模糊性。
- 我们进行了大量的实验来证明以下方法的有效性: (i)领域通用知识注入的有效性,它可以引入和过滤特定领域的知识,以增强模式。(ii)语言引导的歧义学习模块的有效性,该模块在多模态融合过程中可以同时考虑多模态的互补性和冲突。
- 与多模态大型语言模型相比,我们提出的模型在公开的多模态情绪分析数据集CMU-MOSI、CMUMOSEI和MELD上仍然取得了出色的性能。
2.相关工作
2.1 多模态语义分析
2.2 知识注入
在自然语言处理领域,预先训练过的语言模型通过结合外部知识来提高性能。这些方法主要涉及引入外部知识来加强表示[34–38]。这些方法的主要策略是设计一个轻量级的预先训练过的适配器,用于学习外部知识,然后将该适配器嵌入到模型中,以增强表示[29]。例如,Wang等人[39]为Roberta设计了不同的适配器,引入了来自多个领域的外部知识来提高性能,而[29]直接为每个模态引入了外部知识,增强了原始表示。在本文中,我们将外部知识概念化为领域通用知识,而将原始数据集中的知识视为领域特定知识。领域通用知识包括能够增强领域特定知识的信息。我们引入了领域的通用知识,并有选择地过滤了增强其相关性的组件。
3. 方法
图2展示了所提出的框架,包括两个组成部分:知识注入模态内强化和语言引导的跨模态歧义学习。
为了改进单模态表示,我们引入了来自外部多模态情绪分析数据集的领域通用知识作为补充信息。图3说明了我们学习每种模态的领域通用知识和领域特定知识的方法。我们设计了域通用的编码器𝑓𝑔{𝑡,𝑣,𝑎}和域特定的编码器𝑓𝑠{𝑡,𝑣,𝑎},每个模态的参数分别为𝜃𝑔{𝑡,𝑣,𝑎}和𝜃𝑠∗。前者学习领域通用知识𝑥𝑔{𝑡,𝑣,𝑎},后者学习领域特定知识𝑥𝑠{𝑡,𝑣,𝑎}。
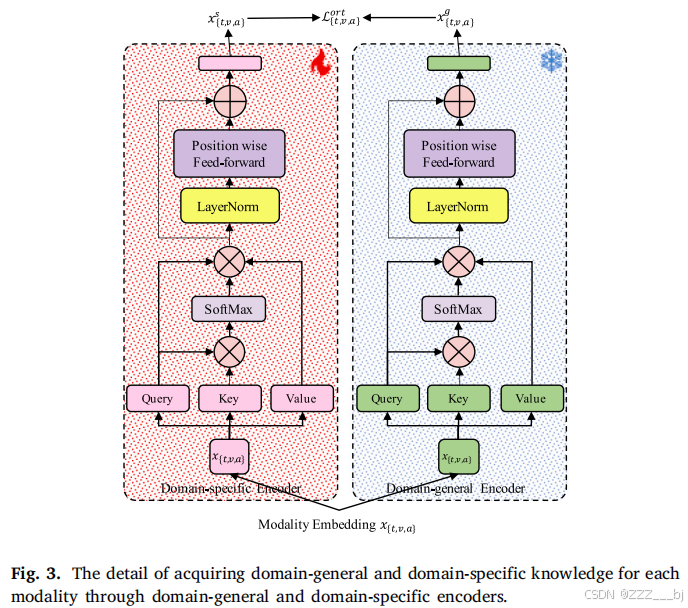

其中,𝑥{𝑡,𝑣,𝑎}表示由𝑓{𝑡,𝑣,𝑎}以参数𝜃{𝑡,𝑣,𝑎}进行提取的样本𝑋{𝑡,𝑣,𝑎}的特征。在之前的工作[8]之后,知识编码器使用了一个一层的transformer[23]来学习模态的顺序信息。领域特定的知识编码器𝑓𝑠{𝑡,𝑣,𝑎}在训练过程中通过梯度下降进行更新。使用外部多模态情绪分析数据集对领域特定知识编码器𝑓𝑔{𝑡,𝑣,𝑎}进行了预训练,其参数在训练阶段保持冻结。领域通用知识𝑥𝑔{𝑡,𝑣,𝑎}和领域特定知识𝑥{𝑡,𝑣,𝑎},来自不同的模式,代表了信息的两个不同的部分。为了加强它们的差异,我们引入了一个正交损失[14]来约束通用和特定领域的知识。

其中‖‖2𝐹为弗罗比尼乌斯范数。由于领域通用知识编码器的参数冻结,这种正交损失确保了特定领域的编码器专注于学习特定领域的知识。
为了充分利用领域的通用知识,我们引入了一个交叉知识注入编码器(CKIE)模块。图4说明了我们过滤引入的领域特定知识和增强单一模态的方法。它利用域通用表示来加强特定领域的表示,从而提高单模态的性能。
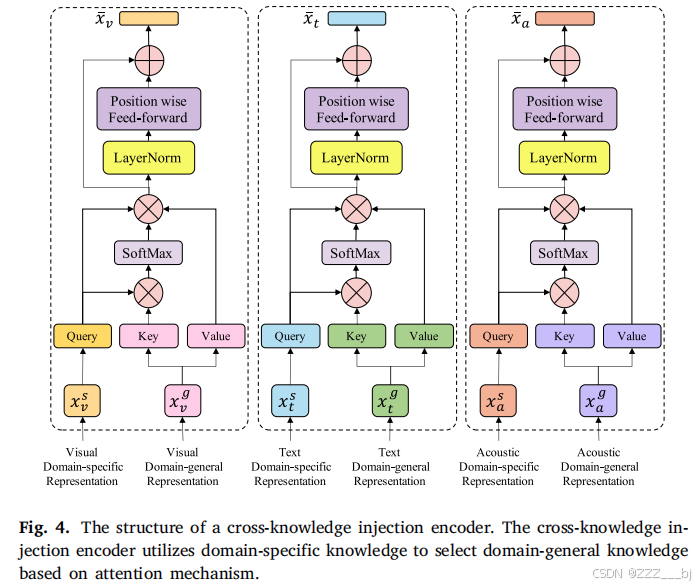

其中,𝑥∗表示强化的单模态表示。CKIE利用领域通用知识和领域特定知识之间的注意力权重来选择领域通用知识并加强单模态。

其中,𝑊∗𝑞𝑠、𝑊∗𝑘𝑔和𝑊∗∗𝑣𝑔表示可学习的参数。𝑥𝑠∗和𝑥𝑔∗表示领域特定知识表示和领域通用知识表示。
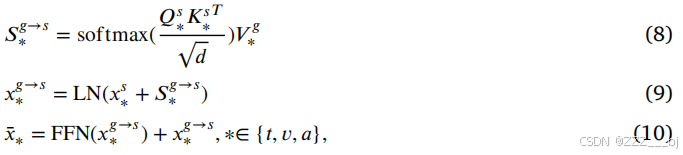
其中,𝑥∗表示增强的单峰表示。符号FFN和LN分别表示前馈层和LayerNorm层。
3.2 语言引导的跨模态歧义学习
我们的目标是测量从属模态向主导情态传递补充信息时的歧义。跨模态序列通过跨模态交互包括潜在的语义相关性[8,17],对齐这些语义信息可以更好地利用互补的多模态数据。具体地说,我们利用主导模态从从属模态中查询信息,所查询的信息被表示为混合模态。我们首先在主导模态的指导下,计算主导模态和从属模态之间的跨模态对齐分数(CAS)。

其中,下标𝛼和𝛽分别表示主导模态和从属模态。score𝛼→𝛽分别表示文本模式与视觉和音频模式的对齐分数。CAS计算跨模态token之间的相似性,以对齐异步的跨模态序列。


根据跨模态对齐分数的定义,我们计算基于跨模态对齐分数的混合模态表示。

其中,𝑥𝑣→𝑡和𝑥𝑎→𝑡表示主导和从属模态之间的对齐混合模态表示**。当主导[17]和从属模态是一致的[17]时,混合模态可以加强主导模态,当主导和从属模态之间出现歧义时,它也可能引入额外的噪声**[28]。
为了缓解这一问题,我们基于语言引导的跨模态歧义度量动态调整了混合模态表示的权重。具体来说,我们使用一个变分自编码器来估计增强文本模态𝑥𝑡、混合模态𝑥𝑣→𝑡和𝑥𝑎→𝑡的后验分布。我们假设先验分布遵循高斯分布。具体来说,对于视觉-文本和音频-文本的混合模态,变分后验分布的形成表示如下:
其中,𝑞分别表示参数为𝜃𝑎→𝑡、𝜃𝑣→𝑡和𝜃𝑡的变分编码器。同时,我们利用KL散度分别估计𝑞𝜃𝑣→𝑡(𝑧𝑣→𝑡∣𝑥𝑣→𝑡),𝑞𝜃𝑎→𝑡(𝑧𝑎→𝑡∣𝑥𝑎→𝑡),和𝑞𝜃(𝑧𝑡∣𝑥𝑡)之间的分布差,分别表示为𝐷𝐾𝐿(𝑞(𝑧𝑣→𝑡∣𝑥𝑣→𝑡)∥𝑞(𝑧𝑡∣𝑥𝑡))和𝐷𝐾𝐿(𝑞(𝑧𝑎→𝑡∣𝑥𝑎→𝑡)∥𝑞(𝑧𝑡∣𝑥𝑡)),。基于多模态数据的𝑖th样本𝑥𝑖={𝑥𝑖𝑡,𝑥𝑖𝑣,𝑥𝑖𝑎},我们可以得到训练数据集的分布:
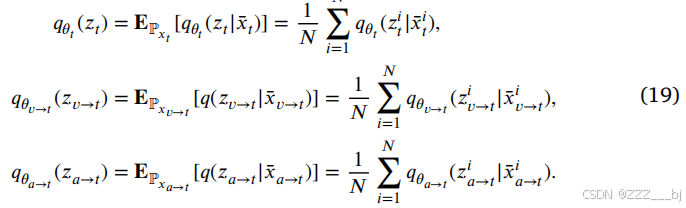
通过计算先验分布𝑥𝑖𝑡、𝑥𝑖𝑣→𝑡和𝑥𝑖𝑎→𝑡之间的KL散度,得到了𝑖th样本的歧义度。形式上,𝑖th样本对𝑥𝑖𝑣→𝑡和𝑥𝑖𝑡之间混合模态表示的歧义度度量如下:
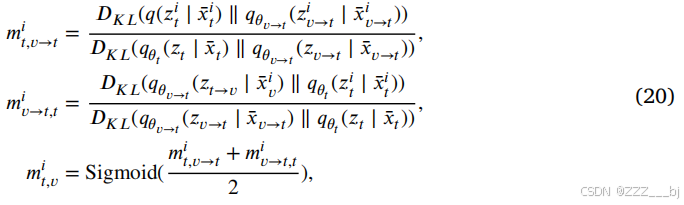
其中,𝐷𝐾𝐿(⋅)为KL散度。𝑚𝑖𝑣→𝑡,𝑡和𝑚𝑡,𝑣→𝑡是𝑥𝑡和𝑥𝑐→𝑡分布之间的距离度量。KL散度是一种非对称距离度量。我们以两个距离之间差异的平均值作为𝑖th样本的𝑚𝑖𝑡,𝑣的模糊度量。
同样,混合模态𝑥𝑖𝑎→𝑡和增强文本模态𝑥𝑖𝑡之间的歧义样本度量的计算如下:
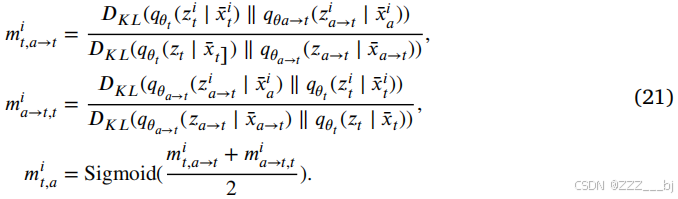
其中,𝑚𝑖𝑡,𝑎表示𝑖-样本在混合模态表示𝑥𝑎→𝑡和强化文本模态𝑥𝑡之间的歧义度量。为了充分利用模糊的多模态数据,我们基于显式的模糊度量,在跨模态交互过程中动态地调整了从下级模式到主导模式的信息流。
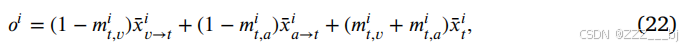
其中,𝑜𝑖表示主导模态和从属模式之间融合的输出。输出的𝑜𝑖通过一个多层感知器来获得最终的预测值𝑦。混合模态表征(𝑥𝑎→𝑡,𝑥𝑎→𝑡)与强化𝑥𝑡之间的距离(𝑚𝑖𝑡,𝑣,𝑚𝑖𝑡,𝑎)越大,从下级模态转移到主导模态的跨模态信息的权重就越小。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









