









使用一个东西,却不明白它的道理,不高明。
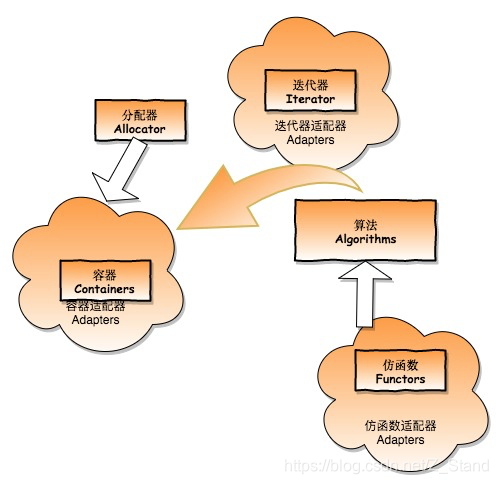
STL六大部件
- 容器 Containers 用来存放数据
- 分配器 Allocators 为容器内的数据分配存储空间
- 算法 Algorithms 计算数据
- 迭代器 Iterators 访问数据的式(算法使用其访问容器内大数据)
- 适配器 Adapters
- 仿函数 Functors 类似于函数的功能

六大组件之间的关系示意图如下:
容器和容器之间的实现关系图如下(这个图是候捷老师总结的):
大体意思是,左侧的序列式容器中,heap相关的算法实现使用的是上一层的vector,而priority_queue优先级队列的实现使用的是上一层的heap。
缩进的容器代表的是被实现的容器,之上未缩进的代表的是底层结构。像stack和queue(缩进)了容器适配器底层是用deque实现的。
同时对于关联式容器,set,map,mutiset,multimap(缩紧)的底层实现都是rb_tree(未缩进);且hash_set,hash_map等容器的底层是hashtable。
图中显示的是C++11 版本之前的容器内容,当C++11推出之后,slist就变成了forward_list,hash_set和hash_map就变成了unordered_set和unordered_map;hash_multiset 和 hash_multimap就变成了unordered_multiset和unordered_multimap

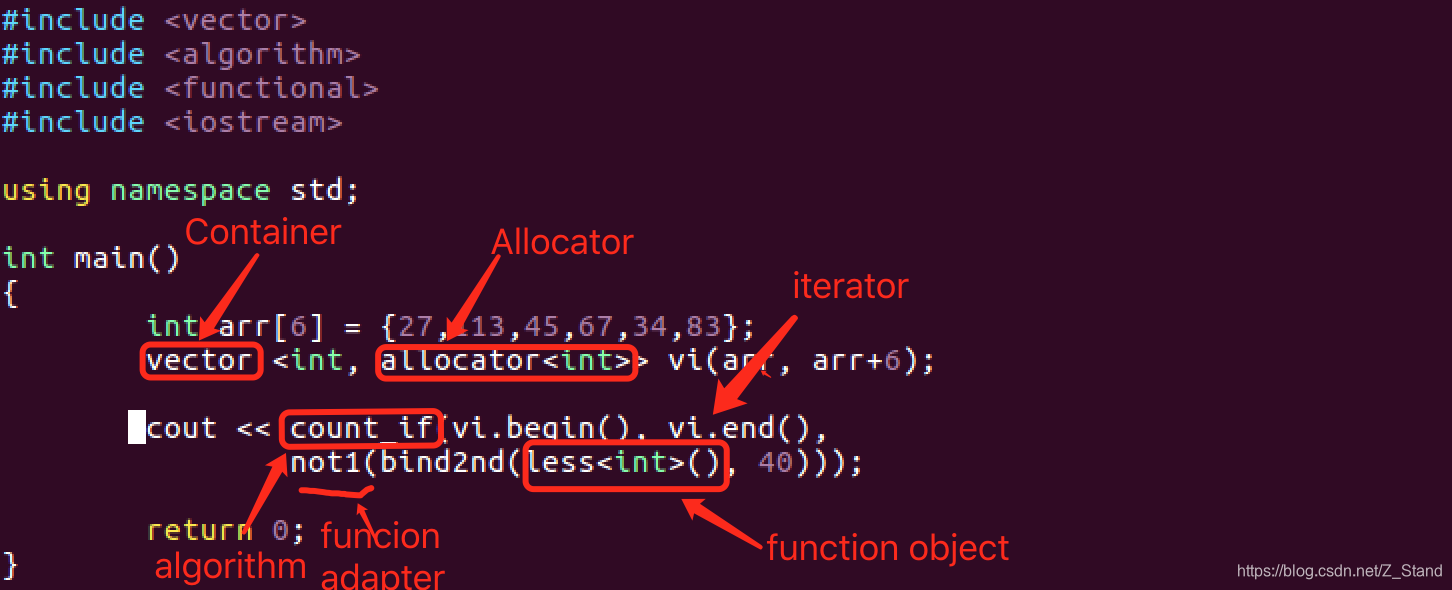
举例如下代码:
核心功能是计算数组arr中大于40的元素的个数
所有的容器区间都是 前闭后开区间[ ),所以遍历容器的形态可以如下
Containter<T> c;
...
Container<T>::iterator ite = c.begin();
for(; ite != c.end(); ++ ite)
...
C++11 的新特性,提供range-based for statement,来简化以上的容器遍历形态
for ( dec1 : coll ) {
statement
}
for ( int i : {2,3,4,5,7,8}) {
std::cout << i << std::endl;
}
std::vector <double> vec;
...
for ( auto elem : vec) {
std::cout << elem << std::endl;
}
for (auto &elem :vec) {
elem *= 3;
}
容器的使用
Array
静态数组,空间大小是直接分配好的
基本接口如下
- size()
- front() 返回第一个元素
- back() 返回最后一个元素
- data() 返回第一个元素的首地址
#include <iostream>
#include <array>
using namespace std;
int main()
{
array<int,100> arr_test;
for(int i = 0;i < 100; ++i) {
arr_test[i]=i;
}
cout << arr_test.size() << endl;
cout << arr_test.data() << endl;
return 0;
}
vector
基本接口如下:
- push_back()
- size()
- front() 第一个元素
- back() 最后一个元素
- data() 内存中的起始地址

vector的内存增长是两倍的方式,即 push_back 第一个元素时发现内存空间不够,allocator分配器会分配能够存放2个vector元素的内存空间;放第三个元素的时候,又会分配4个元素的内存空间;放第五个的时候又会分配 8个元素的存储空间。。。
同时每次分配新的大小的内存空间的时候会做一个元素的整体拷贝,即将之前的空间元素整体拷贝到新的扩容后的内存空间。
利用data()函数验证如下:
#include <vector> // vector
#include <iostream>
using namespace std;
int main()
{
vector<int> test_arr;
for(int i = 0; i<100;++i) {
test_arr.push_back(i);
if(i % 2 == 0)
cout << test_arr.data() << endl;
}
return 0;
}
可以看到最后的输出,当分配空间之后内存中的起始地址都会发生变化:
0x1885050 #两个元素空间
0x1885050
0x1885090 #四个元素空间
0x1885090
0x18850c0 #八个元素空间
0x18850c0
0x18850c0
0x18850c0
...
后续会进行相关的源码实现的分析,为什么要这样做?
list
基本操作如下
- push_back()
- size()
- max_size() 存放最多的元素的个数,只要内存足够,就能够一直分配
- front()
- back()

deque
双端队列
基本操作如下:
- push_back()
- size()
- front()
- back()
- max_size()
内存分配的示意图如下(元素内存中 的存放方式并不是连续的):
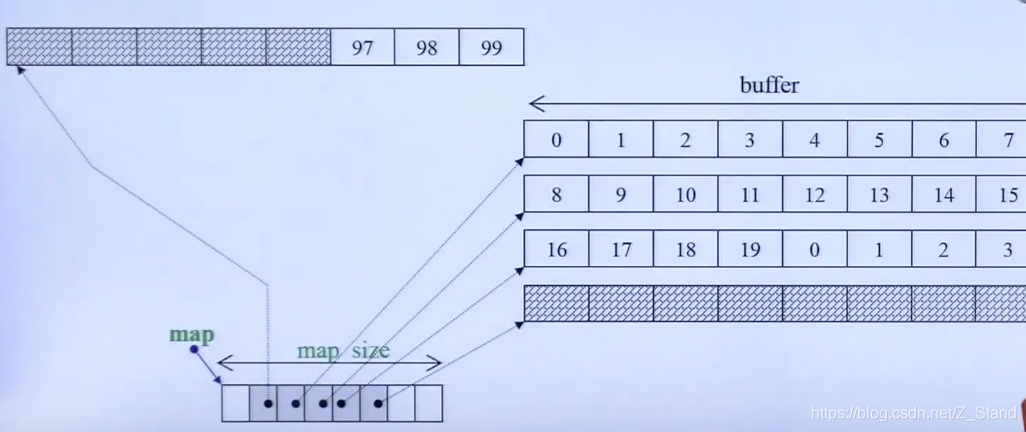
deque内部每一个区域存储一个指针,指针指向的是内存一段buffer区域,buffer里面存储的是一个个具体元素。当需要扩容的时候,会分配一个新的指针区域,并为这个指针区域分配对应的buffer。
mutiset
multiset和set的区别就是 muti允许元素重复,来体现multi的作用。
- insert() 插入元素
- size()
- max_size()
底层数据结构是红黑树的实现
这里它和multimap的基本是一致的,只是multimap容器的对外使用是允许key-value不同,而multiset的key-value是一样的。且元素插入本身有序,因为底层红黑树的结构就是有序的。
一些测试代码如下:
#include <iostream>
#include <string>
#include <ctime>
#include <set>
#include <algorithm>
#define MAX_LEN 1000000
using namespace std;
int main()
{
multiset<string> c;
for(int i = 0; i<MAX_LEN ;++i) {
try {
c.insert(to_string(i));
}
catch(exception &p) {
cout << "i = " << i << " " << p.what() << endl;
abort();
}
}
cout << "c.max_size: " << c.max_size() << endl;
cout << "c.size: " << c.size() << endl;
string target = to_string(23456);
cout << "find target is: " << target << endl;
/*对比全局的find函数和mutiset自带的函数查询效率*/
clock_t timestart = clock();
auto item = ::find(c.begin(),c.end(),target);
cout << "::find,milli-seconds: " << clock() - timestart << endl;
if (item != c.end()) cout << "found " << endl;
else cout << "not found" << endl;
timestart = clock();
auto pItem = c.find(target);
cout << "c.find,milli-seconds: " << clock() - timestart << endl;
if(pItem != c.end()) cout << "found" << endl;
else cout << "not found" << endl;
return 0;
}
输出如下,结果非常明显了:
c.max_size: 288230376151711743
c.size: 1000000
find target is: 23456
::find,milli-seconds: 6629
found
c.find,milli-seconds: 5
found
multimap
基本接口如下:
- insert() 插入元素
- size()
- max_size()
- multiset 不允许使用 [ ] 进行insert
同样使用红黑树实现,底层数据按key有序。
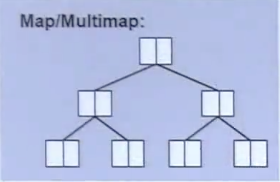
简单应用代码:
#include <iostream>
#include <string> //to_string()
#include <ctime> //clock()
#include <map>
#include <algorithm> // find()
#define MAX_LEN 1000000
using namespace std;
int main()
{
multimap<long, string> c;
for(int i = 0; i<MAX_LEN ;++i) {
try {
c.insert(make_pair(i,to_string(i*10)));
}
catch(exception &p) {
cout << "i = " << i << " " << p.what() << endl;
abort();
}
}
cout << "c.max_size: " << c.max_size() << endl;
cout << "c.size: " << c.size() << endl;
long target = 23456;
cout << "find target is: " << target << endl;
clock_t timestart = clock();
auto pItem = c.find(target);
cout << "c.find,milli-seconds: " << clock() - timestart << endl;
if(pItem != c.end()) cout << "found" << endl;
else cout << "not found" << endl;
return 0;
}
输出如下:
c.max_size: 256204778801521550 #怀疑这里的max_size与系统内存大小有关系
c.size: 1000000
find target is: 23456
c.find,milli-seconds: 5
found
unordered_multiset/set
基本操作接口:
- insert()
- size()
- max_size()
- bucket_count()
- load_factor()
- max_load_factor()
- max_bucket_count()
数据结构如下:
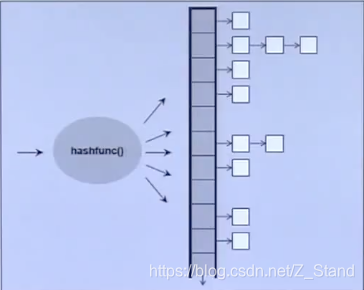
unordered_multiset/set 以及unordered_multimap/map的底层实现都是hash,为了解决hash冲突,也使用hash 链。为了防止链过长,使用链hash bucket的方式,当链的元素个数达到一定程度会分配一个双倍的存储空间,但是该链上的元素会打rehash重新分配。
简单应用代码:
#include <iostream>
#include <string> // to_string()
#include <ctime> // clock()
#include <unordered_set> // unordered_multiset
#include <algorithm> //::find()
#define MAX_LEN 1000000
using namespace std;
int main()
{
unordered_multiset<string> c;
for(int i = 0; i<MAX_LEN ;++i) {
try {
c.insert(to_string(i));
}
catch(exception &p) {
cout << "i = " << i << " " << p.what() << endl;
abort();
}
}
cout << "c.max_size: " << c.max_size() << endl;
cout << "c.size: " << c.size() << endl;
cout << "c.bucket_count: " << c.bucket_count() << endl;
cout << "c.load_factor(): " << c.load_factor() << endl;
cout << "c.max_load_factor(): " << c.max_load_factor() << endl;
cout << "c.max_bucket_count: " << c.max_bucket_count() << endl;
string target = to_string(23456);
cout << "find target is: " << target << endl;
/*对比全局::find函数提供的查找效率和容器本身提供的find函数查找效率的差异*/
clock_t timestart = clock();
auto item = ::find(c.begin(),c.end(),target);
cout << "::find,milli-seconds: " << clock() - timestart << endl;
if (item != c.end()) cout << "found " << endl;
else cout << "not found" << endl;
timestart = clock();
auto pItem = c.find(target);
cout << "c.find,milli-seconds: " << clock() - timestart << endl;
if(pItem != c.end()) cout << "found" << endl;
else cout << "not found" << endl;
for(int i = 0;i < 20; ++i)
cout << "bucket " << i << "'s element is: " << c.bucket_size(i) << endl;
return 0;
}
输出如下:
c.max_size: 384307168202282325
c.size: 1000000
c.bucket_count: 1056323
c.load_factor(): 0.94668
c.max_load_factor(): 1
c.max_bucket_count: 384307168202282325
find target is: 23456
::find,milli-seconds: 75920
found
c.find,milli-seconds: 2
found
bucket 0's element is: 0
bucket 1's element is: 1
bucket 2's element is: 0
bucket 3's element is: 1
bucket 4's element is: 2
bucket 5's element is: 2
bucket 6's element is: 3
bucket 7's element is: 2
bucket 8's element is: 2
bucket 9's element is: 2
bucket 10's element is: 1
bucket 11's element is: 3
bucket 12's element is: 0
bucket 13's element is: 1
bucket 14's element is: 1
bucket 15's element is: 3
bucket 16's element is: 1
bucket 17's element is: 0
bucket 18's element is: 1
bucket 19's element is: 0
以上的结果中bucket_count竟然比size的元素个数多,这个原理就是前面说到unordered_multiset的实现过程中对单个hash链上的元素个数超过一定的限制之后进行rehash,同时分配double的空间导致的。且bucket_count统计的是分配链空间的bucket,即使它没有存放实际的元素也会被统计到该数值之内。
后续会从源码层面分析以上容器各个操作接口及对应存储结构的外在表现,一群顶尖的工程师用优秀的代码风格开发了这样一批使用简单,内部逻辑复杂有趣的STL,学习无止境,向大佬看齐!

















 9514
9514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









