






1)
容器(Container),是一种数据结构,如list,vector,和deques ,以模板类的方法提供。为了访问容器中的数据,可以使用由容器类输出的迭代器;
容器(container)用于存放数据的类模板。可变长数组、链表、平衡二叉树等数据结构在STL中都被实现为容器。
序列容器
vector
内部数据结构:可变长动态数组。
向量,将元素置于一个动态数组中加以管理,可以随机存取元素(用索引直接存取),数组尾部添加或移除元素非常快速。但是在中部或头部安插元素比较费时;
erase():从指定容器删除指定位置的元素或某段范围内的元素
vector::erase()方法有两种重载形式
如下:
iterator erase( iterator _Where);
iterator erase( iterator _First, iterator _Last);
返回值是一个迭代器,指向删除元素下一个元素;
for (auto it = vec.begin(); it != vec.end(); ) {
if (*it == 2) {
it = vec.erase(it);
continue;
} else {
it++;
}
}
capacity:返回容器当前能够容纳的元素数量
size:返回容器的大小
Vector的容器之所以重要,有以下两个原因:
1. 容器的大小一旦超过capacity的大小,vector会重新配置内部的存储器,导致和vector元素相关的所有reference、pointers、iterator都会失效。
2.内存的重新配置会很耗时间。
1).
reserve表示容器预留空间,但并不是真正的创建对象,需要通过insert()或push_back()等创建对象。
resize既分配了空间,也创建了对象。resize(4) 默认都是0
2).
reserve只修改capacity大小,不修改size大小,resize既修改capacity大小,也修改size大小。
deque
内部数据结构:可变长数组。
双端队列,可以随机存取元素(用索引直接存取),数组头部和尾部添加或移除元素都非常快速。但是在中部或头部安插元素比较费时;
deque 和 vector 有很多类似的地方。在 deque 中,随机存取任何元素都能在常数时间内完成(但慢于vector)。它相比于 vector 的优点是,vector 在头部删除或添加元素的速度很慢,在尾部添加元素的性能较好,而 deque 在头尾增删元素都具有较好的性能(大多数情况下都能在常数时间内完成)
list
内部数据结构:双向链表
双向链表,不提供随机存取(按顺序走到需存取的元素,O(n)),在任何位置上执行插入或删除动作都非常迅速,内部只需调整一下指针;
它们之所以被称为顺序容器,是因为元素在容器中的位置同元素的值无关,即容器不是排序的。将元素插入容器时,指定在什么位置(尾部、头部或中间某处)插入,元素就会位于什么位置。
关联容器
关联容器一般是用平衡二叉树实现的,在关联容器中查找元素和插入元素的时间复杂度都是 O(log(n))
set、multiset、map、multimap,关联容器内的元素是排序的。插入元素时,容器会按一定的排序规则将元素放到适当的位置上,因此插入元素时不能指定位置。
默认情况下,关联容器中的元素是从小到大排序(或按关键字从小到大排序)的,而且用<运算符比较元素或关键字大小。因为是排好序的,所以关联容器在查找时具有非常好的性能。
set:排好序的集合,不允许有相同元素。
multiset:排好序的集合,允许有相同元素。
map:每个元素都分为关键字和值两部分,容器中的元素是按关键字排序的。不允许有多个元素的关键字相同。
multimap:和 map 类似,差别在于元素的关键字可以相同。
不能修改 set 或 multiset 容器中元素的值。因为元素被修改后,容器并不会自动重新调整顺序,于是容器的有序性就会被破坏,再在其上进行查找等操作就会得到错误的结果。因此,如果要修改 set 或 multiset 容器中某个元素的值,正确的做法是先删除该元素,再插入新元素
set<int> se;
type = const int &
容器适配器
栈 stack、队列 queue、优先级队列 priority_queue。它们都是在顺序容器的基础上实现的,屏蔽了顺序容器的一部分功能,突出或增加了另外一些功能。
STL中的statck是一种容器适配器。所谓的容器适配器,是以某种容器作为底部容器,在底部容器之上修改接口,形成另一种风貌。stack默认以双端队列deque作为底部容器。stack没有提供迭代器,通过push/pop接口对栈顶元素进行操作。
栈(stack) 后进先出的值的排列 <stack> ,在默认情况下,stack 就是用 deque 实现的。当然,也可以指定用 vector 或 list 实现
队列(queue) 先进先出的值的排列 <queue> 默认是衍生自deque容器的
优先队列(priority_queue) 元素的次序是由作用于所存储的值对上的某种谓词决定的的一种队列 <queue>
容器适配器都有以下三个成员函数:
push:添加一个元素。
top:返回顶部(对 stack 而言)或队头(对 queue、priority_queue 而言)的元素的引用。
pop:删除一个元素。
容器适配器是没有迭代器的,因此 STL 中的各种排序、查找、变序等算法都不适用于容器适配器。
2)
迭代器(Iterator),提供了访问容器中对象的方法。例如,可以使用一对迭代器指定list或vector中的一定范围的对象。迭代器就如同一个指针。事实上,C++的指针也是一种迭代器。但是,迭代器也可以是那些定义了operator*()以及其他类似于指针的操作符地方法的类对象;
迭代器(iterator)是连接容器和算法的纽带,为数据提供了抽象,使写算法的人不必关心各种数据结构的细节。
迭代器提供了数据访问的标准模型——对象序列,使对容器更广泛的访问操作成为可能。
迭代器(Iterator)是指针(pointer)的泛化,它允许程序员以相同的方式处理不同的数据结构(容器)。
迭代器是一种检查容器内元素并遍历元素的数据类型。
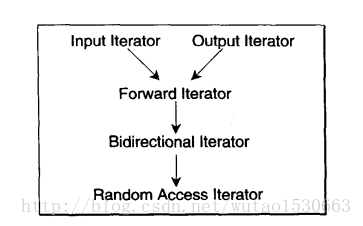
迭代器
1、输入迭代器(istream_iterator)——提供对数据的只读访问。
istream_iterator<int> a(cin);
cout<<*a<<endl;
*a = 4; 错误 不可修改
2、输出迭代器(ostream_iterator)——提供对数据的只写访问
cout<<"input:";
ostream_iterator<int>myout(cout,"\n");
for (int i = 0; i<5; i++) {
*myout = i;
myout++;
}
3、前向迭代器(forward iterator正向迭代器)——提供读写操作,并能向前推进迭代器。只能使用++操作符来单向遍历容器(不能用--)。
4、双向迭代器(bidirectional iterator)——提供读写操作,并能向前和向后操作。可以用++和--操作符来双向遍历容器。其他与前向迭代器一样,也支持解除引用、也是多通的、也是可读写或只读的。
list set multiset map multimap
5、随机访问迭代器(random access iterator)——提供读写操作,并能在数据中随机移动。可直接访问容器中的任意一个元素的双向迭代器。
Vector、deque
只有顺序容器和关联容器支持迭代器遍历,各容器支持的迭代器的类别如下:
容器 支持的迭代器类别 容器 支持的迭代器类别 容器 支持的迭代器类别
vector 随机访问 deque 随机访问 list 双向
set 双向 multiset 双向 map 双向
multimap 双向 stack 不支持 queue 不支持
priority_queue 不支持
6、反向迭代器 (reverse_iterator)是一种反向遍历容器的迭代器,也就是从最后一个元素到第一个元素遍历容器。反向迭代器的自增(或自减)的含义反过来了:对于反向迭代器,++运算符将访问前一个元素,–运算符将访问下一个元素。
for(list<int>::reverse_iterator rit = test_list.rbegin(); rit != test_list.rend();)
{
if (8 == *rit)
{
list<int>::iterator it = –rit.base() ; // 用(++rit).base()也可;
list<int>::iterator it_after_del = test_list.erase(it);
rit = list<int>::reverse_iterator(it_after_del);
}
else
{
++rit;
}
}
7、常量迭代器
vector<int>::const_iterator iter1 = iVec.begin(); //常量迭代器
const vector<int>::iterator iter2 = iVec.begin(); //常量迭代型
你是否疑惑,为什么C++标准化委员会使用常量迭代器(const_iterator)代替常量迭代型(const iterator)?
为什么不用const_iterator代替 const iterator ?
原因很简单:常量迭代器不是常量迭代型。这意味着你能够改变常量迭代器的长度(例如:用++来增加长度)。然而,你不能改变常量迭代器所指向的对象的值。
让我们进一步阐明一下。如果你把迭代器考虑成指向T的指针,那么常量迭代器不是指向T的常量指针,而是指向常量T的非常量指针。
在接下来的例子中,常量迭代器的长度成功地增加了。而另一方面,想要通过迭代器,而改变其中的元素值的企图却失败了,因为它是常量迭代器。
std::vector<double> results;
results:push_back(98.99);
results:push_back(86.33);
std::vector<double>::const_iterator it = vi.begin();
++it; file://正确,改变迭代器,而不是其中的元素
*it = 100.5; file://错误,不能用const_iterator改变其中元素
总之,const_iterator的使用者,不允许通过其迭代器,而改变其指向的元素值。
3)
算法(Algorithm),是用来操作容器中的数据的模板函数。例如,STL用sort()来对一个vector中的数据进行排序,用find()来搜索一个list中的对象,函数本身与他们操作的数据的结构和类型无关,因此他们可以在从简单数组到高度复杂容器的任何数据结构上使用;
<algorithm>是所有STL头文件中最大的一个(尽管它很好理解),
它是由一大堆模版函数组成的,可以认为每个函数在很大程度上都是独立的,其中常用到的功能范围涉及到比较、交换、查找、遍历操作、复制、修改、移除、反转、排序、合并等等。
<numeric>体积很小,只包括几个在序列上面进行简单数学运算的模板函数,包括加法和乘法在序列上的一些操作。
<functional>中则定义了一些模板类,用以声明函数对象。
STL中算法大致分为四类:
1、非可变序列算法:指不直接修改其所操作的容器内容的算法。
2、可变序列算法:指可以修改它们所操作的容器内容的算法。
3、排序算法:对序列进行排序和合并的算法、搜索算法以及有序序列上的集合操作。
4、数值算法:对容器内容进行数值计算。
4)
仿函数(functors)
就是使一个类的使用看上去象一个函数其实现就是类中实现一个操作符(),这个类就有了类似函数的行为,就是一个仿函数类了。
仿函数产生的原因:
由于函数指针毕竟不能满足STL对抽象对象的需求,也不能满足软件积木的需求——函数指针无法和STL其它组件(如配接器adapter)搭配使用,产生更灵活的变化。
特别注意:
仿函数都是传值,而不是传址的。因此算法并不会改变随参数而来的仿函数的状态。
bool my_count(int num)
{
return (num < 5);
}
int a[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::vector<int> v_a(a, a+10);
cout << "count: " << std::count_if(v_a.begin(), v_a.end(), my_count);
在上面我们传递进去了一个函数指针作为count_if的比较条件。但是现在根据新的需求,不再统计容器中小于5的变量个数,改为了8或者3。那么最直接的方法就是加一个参数threshold就可以了,就像下面这样
bool my_count(int num, int threshold)
{
return (num < threshold));
}
但是这样的写法STL中是不能使用的,而且当容器中的元素类型发生变化的时候就不能使用了,更要命的是不能使用模板函数。
template<typename T>
struct my_count1
{
my_count1(T a)
{
threshold = a;
}
T threshold;
bool operator()(T num)
{
return (num < threshold);
}
};
int a[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
std::vector<int> v_a(a, a+10);
cout << "count: " << std::count_if(v_a.begin(), v_a.end(), my_count1<int>(8));
5)
适配器(adapters)
适配器(Adapter)在STL组件的灵活组合运用功能上,扮演着轴承、转换器的角色。它事实上是一种设计模式。
即将一个class的接口转换为另一个class的接口,使原本因接口不兼容而不能合作的classes,可以一起运作。
STL 主要提供如下三种配接器:
1、改变仿函数(functors)接口,称之为 function adapter
functor adapters(亦称为 function adapters)是所有配接器中数量最为庞大的一个族群,其配接灵活程度也非前二者所能及,可以配接、配接、再配接。这些配接操作包括,
(1)系结(bind)、否定(negate)、组合(compose),
(2)以及对一般函数或成员函数的修饰(使其成为一个仿函数)
2、改变容器(containers)接口,称之位 container adapter
STL 提供的两个容器 queue 和 stack,其实都不过是一种配接器,是对 deque (双端队列)接口的修饰而成就自己的容器风貌。如果按照该标准衡量其他容器的话,序列式容器的 set 和 map 其实是对其内部所维护的 RB-tree 接口的改造:
(1)deque:stack、queue
(2)RB-tree:set、map
3、改变迭代器(iterators)接口者,称之为 iterator adapter
STL 提供的应用于迭代器身上的配接器,这些接口所在的头文件为<iterator>,主要包括:
(1)insert iterators
所谓 insert iterators,可以将一般迭代器的赋值(=,assign)操作变为插入(insert)操作。
这样的迭代器包括专司尾端插入操作的 back_insert_iterator,专司头端插入的 front_insert_iterator,以及可在任意位置执行插入操作的 insert_iterator。
由于这三个 iterator adapters 的使用接口不太直观,给一般用户带来困扰,STL 提供三个相应函数,back_inserter()、front_inserter()、inserter()
对于第一点,赋值变插入,可通过 front_inserter() 的源码以清晰地显示:
template<class _Container> inline
front_insert_iterator<_Container> front_inserter(_Container& _Cont)
{ // return front_insert_iterator
return (_STD front_insert_iterator<_Container>(_Cont));
}
template<class _Container>
class front_insert_iterator
: public _Outit
{
typedef front_insert_iterator<_Container> _Myt;
typedef _Container container_type;
typedef typename _Container::value_type _Valty;
// 真正的赋值操作在这,它首先进行的是push_front
// 自然从 赋值 变成了 插入
// 显然 front_inserter 的参数必须是支持 push_front 成员方法的容器,
// vector 容器就不符合要求
_Myt& operator=(const _Valty& _Val)
{ // push value into container
container->push_front(_Val);
return (*this);
}
(2)reverse iterators
(3)iostream iterators
istream_iterator
ostream_iterator
6)
空间配置器(allocator)
为什么要有空间配置器呢?这主要是从两个方面来考虑的。
1、小块内存带来的内存碎片问题
单从分配的角度来看。由于频繁分配、释放小块内存容易在堆中造成外碎片(极端情况下就是堆中空闲的内存总量满足一个请求,但是这些空闲的块都不连续,导致任何一个单独的空闲的块都无法满足这个请求)。
2、小块内存频繁申请释放带来的性能问题。
关于性能这个问题要是再深究起来还是比较复杂的,下面我来简单的说明一下。
开辟空间的时候,分配器会去找一块空闲块给用户,找空闲块也是需要时间的,尤其是在外碎片比较多的情况下。如果分配器其找不到,就要考虑处理假碎片现象(释放的小块空间没有合并),这时候就要将这些已经释放的的空闲块进行合并,这也是需要时间的。
malloc在开辟空间的时候,这些空间会带有一些附加的信息,这样的话也就造成了空间的利用率有所降低,尤其是在频繁申请小块内存的时候。
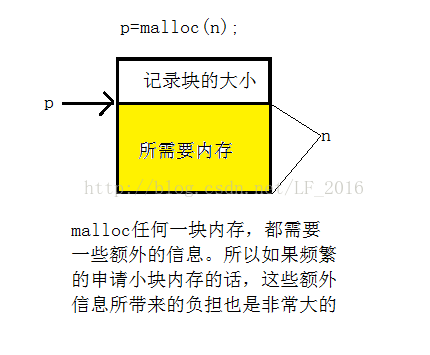
为了解决上面这些问题,所以就提出有了内存池的概念。
内存池最基本的思想就是一次向heap申请一块很大的内存(内存池),如果申请小块内存的话就直接到内存池中去要。这样的话,就能够有效的解决上面所提到的问题。
STL里面的空间配置主要分为两级,一级空间配置器(__malloc_alloc_template)和二级空间配置器(__default_alloc_template)。
在STL中默认如果要分配的内存大于128个字节的话就是大块内存,调用一级空间配置器直接向系统申请,如果小于等于128个字节的话则认为是小内存,则就去内存池中申请。
一级空间配置器很简单,直接封装了malloc和free处理,增加_malloc_alloc_oom_handle处理机制。
二级空间配置器才是STL的精华,二级空间配置器主要由memoryPool+freelist构成。
二级空间配置器:
二级空间配置器使用内存池+自由链表的形式避免了小块内存带来的碎片化,提高了分配的效率,提高了利用率。
SGI的做法是先判断要开辟的大小是不是大于128,如果大于128则就认为是一块大块内存,调用一级空间配置器直接分配。否则的话就通过内存池来分配,假设要分配8个字节大小的空间,那么他就会去内存池中分配多个8个字节大小的内存块,将多余的挂在自由链表上,下一次再需要8个字节时就去自由链表上取就可以了,如果回收这8个字节的话,直接将它挂在自由链表上就可以了。
为了便于管理,二级空间配置器在分配的时候都是以8的倍数对齐。也就是说二级配置器会将任何小块内存的需求上调到8的倍数处(例如:要7个字节,会给你分配8个字节。要9个字节,会给你16个字节),尽管这样做有内碎片的问题,但是对于我们管理来说却简单了不少。因为这样的话只要维护16个free_list就可以了,free_list这16个结点分别管理大小为8,16,24,32,40,48,56,64,72,80,88,86,96,104,112,120,128字节大小的内存块就行了。














 9561
9561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









