









文章目录
优化背景
auto tune 是lazy compaction 方法论中的一种优化方式,主要用来限制compaction/flush的I/O。
随着写入并发的增大,Internal ops :flush, L0->L1 compaction 以及 Higher Level compactions 之间的资源竞争,会造成上层的WriteStall 从而降低写吞吐,增加读延时。
优化演进思路
Rocksdb 的 RateLimiter
Ratelimiter 在 Flush/Compaction 写入之前做一个用户层的缓存,缓存大小可以自己配置。
这个缓存主要用来控制 Flush/Compaction 写入的速度,每当填充满这个缓存的时候才会触发write系统调用,降低频繁的internal I/O对上层用户请求的影响。
控制参数如下:
-
rate_limit_bytes_per_sec:控制 compaction 和 flush 每秒总的写入量 -
refill_period_us:控制 tokens 多久再次填满,譬如rate_limit_bytes_per_sec是 10MB/s,而refill_period_us是 100ms,那么每 100ms 的流量就是 1MB/s。 -
fairness:用来控制 high 和 low priority 的请求,防止 low priority 的请求饿死。
可以通过如下配置设置。
options.rate_limiter.reset(NewGenericRateLimiter(
static_cast<int64_t>(kNumL0Files * kNumKeysPerFile *
kBytesPerKey) /* rate_bytes_per_sec */,
10 * 1000 /* refill_period_us */, 10 /* fairness */,
RateLimiter::Mode::kReadsOnly));
缺点:设置好之后这个限制的写入速率是固定的,适合写入速率较稳稳定的workload场景。如果上层压力不断变化,可能这个rate限制的写入速率就偏小或者偏大,并不能达到提升吞吐,降低延时的目的。
Rocksdb的 auto tune
为了让底层rate limiter 限制的write rate能够根据上层请求压力情况动态变化,而不用人主动得去调整设置的写入速度,社区开发了一个版本的auto tune。支持根据Flush/Compaction的I/O 压力来动态调整rate_limit_bytes_per_sec 配置,从而达到动态调整write rate的目的。
通过如下代码进行配置,每隔10s 根据 Flush+Compaction的I/O情况 调整一次 rate_limiter的写入速度。
if (auto_tuned_) {
static const int kRefillsPerTune = 100;
std::chrono::microseconds now(NowMicrosMonotonic(env_));
if (now - tuned_time_ >=
kRefillsPerTune * std::chrono::microseconds(refill_period_us_))//refill_period_us_为100ms
{
Tune();
}
}
详细代码在Tune 函数中。
主要是通过两个水位 在 当前配置的rate_limit_bytes_per_sec 的一段范围内进行微调整[max_bytes_per_sec_ / kAllowedRangeFactor, max_bytes_per_sec_] , kAllowedRangeFactor。
详细的几个控制参数如下:
-
kLowWatermarkPct = 50
• 控制水位,认为flush/compaction IO 速度超过了50%. -
kHighWatermarkPct = 90
• 控制水位, 认为flush/compaction IO速度超过了 90%. -
kAdjustFactorPct = 5
• 微调当前写入速率的变量 ,5%调整增量. -
kAllowedRangeFactor = 20
• 一个控制因子,最低的写入速率不能低于max_bytes_per_sec_/kAllowedRangeFactor 。
d r a i n e d _ p c t = ( n u m _ d r a i n s − p r e v _ n u m _ d r a i n s ) ⋅ 100 e l a p s e d _ i n t e r v a l s drained\_pct = \frac{(num\_drains − prev\_num\_drains) · 100}{elapsed\_intervals} drained_pct=elapsed_intervals(num_drains−prev_num_drains)⋅100
以上公式用来表示后台I/O情况,其中num_drains 和 prev_num_drains 是在统计Flush/Compaction的过程进行变更的。
总的来说,Rocksdb 原生实现的auto tune 虽然能够进行写入速率的动态调整,仍然有两个问题:
- 它所监控的I/O 是 Flush和Compaction 总的I/O情况,并不是两者分开的。
不能分开调整Flush 也就是调整的值 无法准确体现在上层吞吐。Flush的优先级 高于 compaction,因为其直接导致write-stall。而如果每次预估增加的吞吐都是由compaction带来的,那这样的调整对Flush并没有优势。 - 调整方式是在一个范围内微调,治标不治本。(如果短时间内压力剧增,不论怎么限制rate,都无法降低后台I/O对上层请求的影响)
auto tuned compaction(rocskdb默认auto tune基础上的优化)
这个方法来源于:Auto-tuning RocksDB
针对rocksdb实现的auto tune的两个问题,该设计单刀直入:
- 在auto tune的时候区分Flush/Compaction,优先针对 Flush 的I/O达到水位的情况。
- 调整的过程是通过动态调整diable_auto_compactions 以及 level0_file_num_compaction_trigger 参数
Flush 速度慢了,直接会造成write-stall,从而对吞吐和延时有严重影响。diable_auto_compactions间接降低后台Compaction对 Flush的影响,同时增大level0_file_num_compaction_trigger,直接减少写放大。
当Flush的I/O水位高于50% 且 总的I/O水位高于90%,认为I/O压力较重,禁止compaction,并增大level0_file_num_compaction_trigger为最大。
当Flush的I/O比例低于50% 且 总的I/O水位低于90%,认为I/O压力较轻,开启compaction,并恢复level0_file_num_compaction_trigger 配置。
关于TuneCompaction的代码实现如下:
Status GenericRateLimiter::TuneCompaction(Statistics *stats) {
const int kLowWatermarkPct = 50; // 低水位
const int kHighWatermarkPct = 90; // 高水位
std::chrono::microseconds prev_tuned_time = tuned_time_;
tuned_time_ = std::chrono::microseconds(NowMicrosMonotonic(env_));
int64_t elapsed_intervals = (tuned_time_ - prev_tuned_time +
std::chrono::microseconds(refill_period_us_) -
std::chrono::microseconds(1)) /
std::chrono::microseconds(refill_period_us_);
// We tune every kRefillsPerTune intervals, so the overflow and division by
// zero conditions should never happen.
assert(num_drains_ - prev_num_drains_ <= port::kMaxInt64 / 100);
assert(elapsed_intervals > 0);
int64_t drained_high_pct = // Flush请求的增长速度
(num_high_drains_ - prev_num_high_drains_) * 100 /
elapsed_intervals;
int64_t drained_low_pct = // compaction请求的增长速度
(num_low_drains_ - prev_num_low_drains_) * 100 /
elapsed_intervals;
int64_t drained_pct = drained_high_pct + drained_low_pct; // 总的增速
if (drained_pct == 0) {
// Nothing
} else if (drained_pct <= kHighWatermarkPct && drained_high_pct <
kLowWatermarkPct) {
env_->EnableCompactions(); // 增速减缓,开启compaction,并开启level0文件限制
} else if (drained_pct >= kHighWatermarkPct && drained_high_pct >=
kLowWatermarkPct) {
env_->DisableCompactions(); // 增速增加,关闭compaction,关闭level0文件限制
RecordTick(stats, COMPACTION_DISABLED_COUNT, 1);
}
num_low_drains_ = prev_num_low_drains_;
num_high_drains_ = prev_num_high_drains_;
num_drains_ = prev_num_drains_;
return Status::OK();
}
其中EnableCompactions 和 DisableCompactions函数实现在了全局共享变量Env中,可以通过共享变量来进行相关option的动态变更(这里的意义在于提供了一种思路,可以通过Env 来实现rocksdb参数的动态调优)
bool auto_tuned_compaction;
bool disable_auto_compactions;
int level0_file_num_compaction_trigger;
int prev_level0_file_num_compaction_trigger;
// Unlimit level0 file num, and this function will be used with Env
void DisableCompactions() {
if (!disable_auto_compactions) {
prev_level0_file_num_compaction_trigger =
level0_file_num_compaction_trigger;
disable_auto_compactions = true;
level0_file_num_compaction_trigger = (1<<30);
}
}
// Limit Level0 file nums, and reset back the option
// and will be used in Env.
void EnableCompactions() {
if (disable_auto_compactions) {
disable_auto_compactions = false;
level0_file_num_compaction_trigger =
prev_level0_file_num_compaction_trigger;
}
}
当设置了Enable和Disable之后,会在下次触发write stall之前重置compaction相关的信息
WriteStallCondition ColumnFamilyData::RecalculateWriteStallConditions() {
auto write_stall_condition = WriteStallCondition::kNormal;
// Wether to enable the auto compaction by check auto_tuned_compaction
// to delay the write stall condition
if (current_ != nullptr) {
if (mutable_cf_options_.auto_tuned_compaction) {
mutable_cf_options_.disable_auto_compactions = // 设置enble/disable compaction
env_->disable_auto_compactions;
mutable_cf_options_.level0_file_num_compaction_trigger = // 设置level0文件数量
env_->level0_file_num_compaction_trigger;
}
}
......
}
关于这种Auto tuned compaction 存在的问题是:
如果有段时间用户并发压力处于一个高峰的稳态,可能导致L0文件数量过多,对读性能有一定的影响(具体数据还需要详细测试),同时持续高峰过久,也会因为pending-byes 过多再次出现write-stall的问题。
如下图,相关指标可以看看下文benchmark的说明,总之 蓝色的先代表的用户I/O吞吐,灰色的线代表的是rocksdb compaction的速度,可以看到compaction吞吐被限制在180M以下,但是用户I/O吞吐还是有抖动(预期应该是一个平滑的sin 曲线),rocksdb日志中出现的write-stall问题就是 超过64G的pending-bytes,持续写入压力过大,累积的compaction量过多。

也就是,当用户I/O压力持续稳定在一个高峰,如果不变更底层rocksdb的compaction逻辑或者LSM的数据结构的情况下,write-stall问题不可避免。
优点:
- 曲线波动的情况下,能够有效降低compaction/flush I/O对客户端性能的影响,保证了吞吐的稳定性
- 调优方式值得借鉴,能够对后续 rocksdb 参数的 自动调优 提供参考
Bench Mark
硬件配置
- cpu : Intel® Xeon® Gold 5218 CPU @ 2.30GHz 64 core
- mem: 500G
- Disk: nvme-ssd * 3.2T
- fs: xfs (rw,noatime,attr2,inode64,noquota)
软件配置
-
Value-size: 100B
-
Threads: 1
-
Compression: none
-
Bloomfilter: whole_key_filtering = true, NewBloomFilterPolicy(16,false)
-
Max_background_compactions: 2
-
db_bench 6.6.0
Value-size: 512B 4096B, 64K, 256K,1M (value较大时write-stall更明显)
测试模型
sin曲线变化的请求压力下: 开启comapction, 禁止compaction,开启rocksdb原生的auto tune(和ratelimiter的效果差不多),论文优化后的 auto tune 四种对比测试的statistics 数据。
这里主要展示的是纯写场景中New auto tune的优化方式对写性能的影响。
测试指标
-
Interval writes:单独的用户侧瞬时请求的吞吐,瞬时指的是打印statistics的时间间隔。如果没有后台IO的影响,这里应该看到一个sin形态的workload。 -
Cumulative writes: 也是用户侧的请求吞吐,并非是瞬时的,而是从开始测试到当前打印statistics时的平均吞吐,提供一个平均吞吐的参考。 -
Cumulative compactions: Flush+compaction 总的平均吞吐,表示一段时间的compaction量(如果disable compaction,则该指标应该和Cumulative writes一样/接近只有Flush)。
测试数据
以下为了简要说明效果,仅以64K value为例,展示详细的测试数据。
更加详细的数据 可以看看后文attach 的一个excel文件。
-
enable compaction
./db_bench \ -benchmarks="fillrandom,stats" \ -statistics \ -db=./test_db1 \ -wal_dir=./test_db1 \ -duration=350 \ -value_size=65536 \ -enable_pipelined_write=true \ -compression_type=None \ \ -sine_write_rate=true \ -sine_a=75000000 \ -sine_b=0.017942857 \ -sine_c=4.71 \ -sine_d=125000000 \ -stats_per_interval=1 \ -stats_interval_seconds=5 \ -max_write_buffer_number=6 \ -max_background_flushes=4 \ -max_background_compactions=2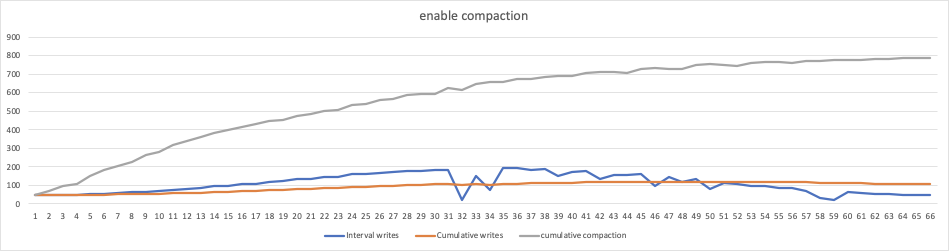
上图 未禁止compaction,cumulative comapaction速度不断增加(compaction的量不断增加,且增加的速度越来越快),达到了700M以上的吞吐;随着compaction量的增加 用户Interval writes 会受到影响(本身是sin 请求波形),后续35 以后不断降低,因为出现了write stall。 -
disable compaction
./db_bench \ -benchmarks="fillrandom,stats" \ -statistics \ -db=./test_db1 \ -wal_dir=./test_db1 \ -duration=350 \ -value_size=65536 \ -enable_pipelined_write=true \ -compression_type=None \ \ -sine_write_rate=true \ -sine_a=75000000 \ -sine_b=0.017942857 \ -sine_c=4.71 \ -sine_d=125000000 \ -stats_per_interval=1 \ -stats_interval_seconds=5 \ -max_write_buffer_number=6 \ -max_background_flushes=4 \ -max_background_compactions=2 \ -level0_slowdown_writes_trigger=10000 \ -level0_stop_writes_trigger=10000 \ -level0_file_num_compaction_trigger=10000 \ -disable_auto_compactions=true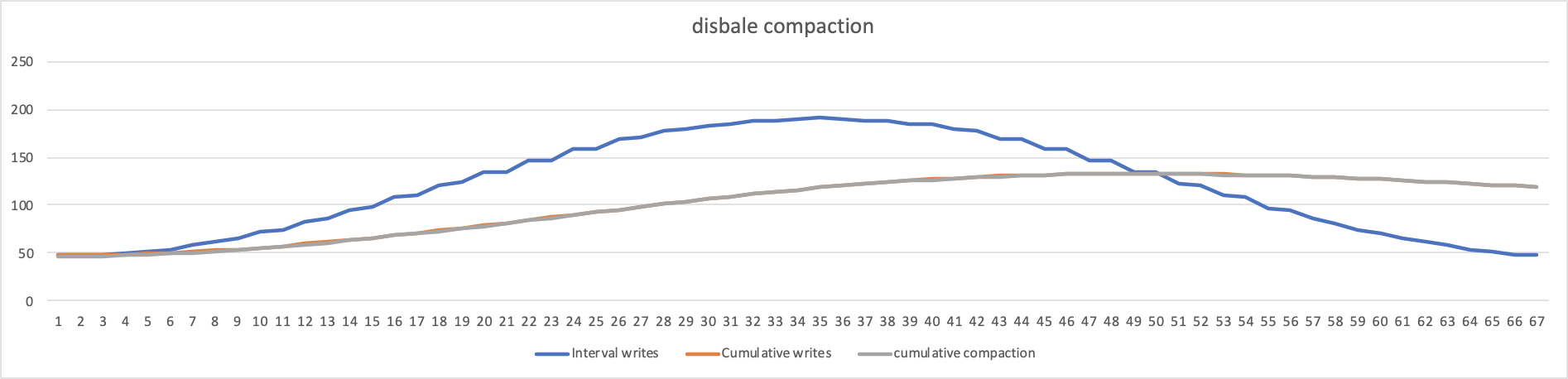
禁止掉自动compaction之后,很明显 interval writes 不会受到compaction的影响。同时 cumulative compaction 和 cumulative writes 基本重合,因为没有了compaction ,只剩下flush,所以两者的吞吐基本接近。 -
Rocksdb auto tune compaction
# rocksdb auto tune compaction ./db_bench \ -benchmarks="fillrandom,stats" \ -statistics \ -db=./test_db1 \ -wal_dir=./test_db1 \ -duration=350 \ -value_size=65536 \ -compression_type=None \ \ -sine_write_rate=true \ -sine_a=75000000 \ -sine_b=0.017942857 \ -sine_c=4.71 \ -sine_d=125000000 \ -stats_per_interval=1 \ -stats_interval_seconds=5 \ -max_background_flushes=4 \ -max_background_compactions=2 \ -max_write_buffer_number=6 \ -subcompactions=2 \ -rate_limiter_auto_tuned=true \ -rate_limiter_bytes_per_sec=380000000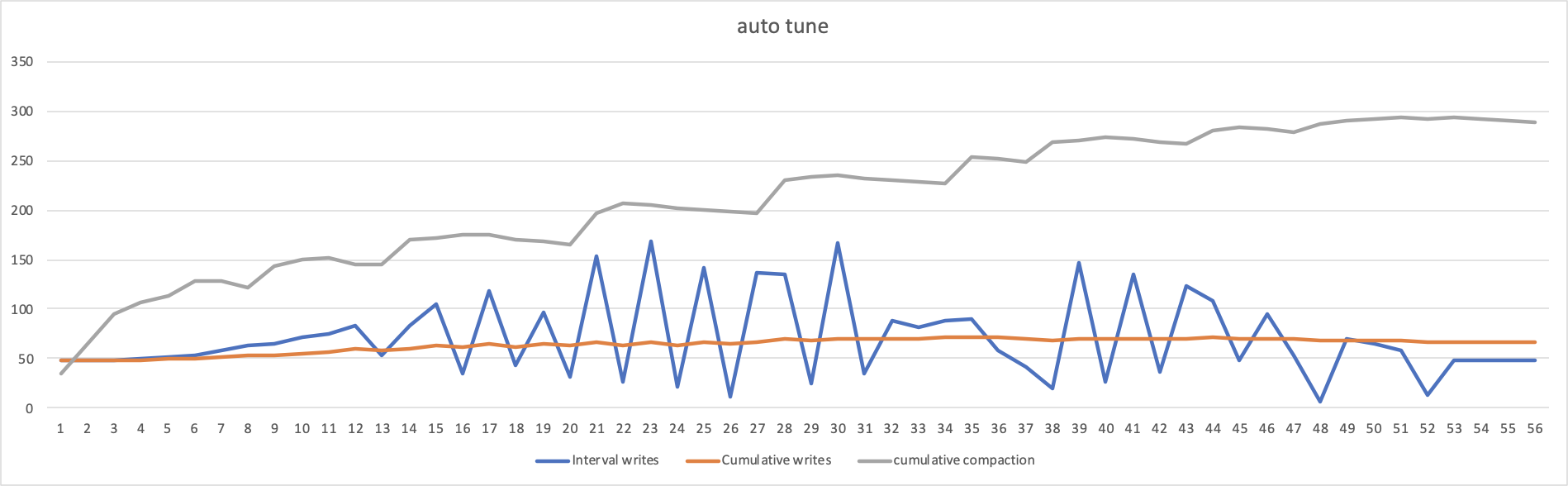
rocksdb的auto tune 开启,并且打开compaction。可以看到 很明显得降低了compaction/IO,之前cumulative compaction能够达到700M,到现在被限制到了300M以内。但底层仍然存在write stall, 仍然会对Interval writes 造成影响。
-
Newer auto tune
已经实现了auto tune ,在打开默认的auto tune的情况下通过option设置
auto_tuned_compaction为true即可# newer auto tune compaction # 和rocksdb原生的差异体现在 auto_tuned_compaction=true # 该配置是实现了论文中的newer auto tune的设计 /media/ssd1/zhanghuigui/db_src/rocksdb/build/db_bench \ -benchmarks="fillrandom,stats" \ -statistics \ -db=./test_db1 \ -wal_dir=./test_db1 \ -duration=350 \ -value_size="$value_size" \ -compression_type=None \ \ -sine_write_rate=true \ -sine_a=75000000 \ -sine_b=0.017942857 \ -sine_c=4.71 \ -sine_d=125000000 \ -stats_per_interval=1 \ -stats_interval_seconds=5 \ -max_background_flushes=4 \ -max_background_compactions=2 \ -max_write_buffer_number=6 \ -auto_tuned_compaction=true \ -subcompactions=2 \ -rate_limiter_auto_tuned=true \ -rate_limiter_bytes_per_sec=380000000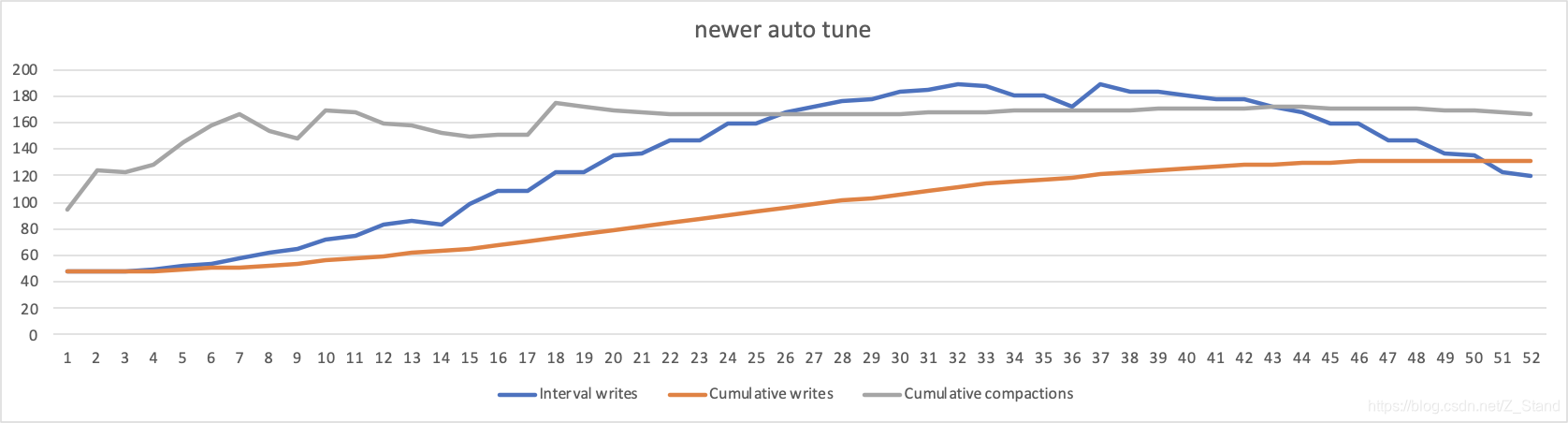
很明显,既能保证compaction/flush 的写入吞吐被限制住(从enable compaction的700M 降低到 160M),也能减缓Interval writes 即用户workload 不被影响(基本还是能够保持sin workload的形态)。

















 4083
4083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









