









文章目录
前言
本文着重围绕compaction展开讨论,争取通过这篇文章将RocksDB在其中的优化以及各种调优方式准确的呈现出来。这个系列主要分为三部分,这一篇主要以文字的形式讲述RocksDB的compaction做了哪些事情,流程是什么;下一篇以分析源码的形式将RocksDB的compaction流程展现出来;最后一篇则是展开呈现RocksDB对于compaction做的一系列优化,以及这些优化是为了解决哪些问题。
Compaction用来干什么的?
简单来说,由于LSM-Tree的特性,删除以及更新造成的重复key会不断形成叠加,如果不对这些重复的key进行清理的话整体的空间放大会被无限延展,因此compaction机制的到来可以使得整体数据量维持在一个可控范围内。
Leveled compaction
RocksDB中从L1开始的每一层代表一个sorted run,每一层的sst文件包含的key范围互不重叠,如下图。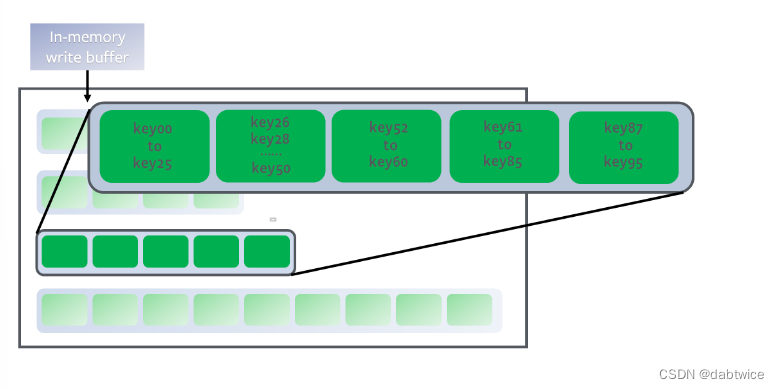
L0则是一个特殊的层,包含的是从memtable中下刷下来的数据。可以理解为L0中的每一个文件都是一个sorted run,因为没有保证不重叠性。
每一个非L0层都有一个大小阈值,这个数字随着层数的增加指数级递增。具体数据如下图,超出这个阈值之后就会触发compaction。
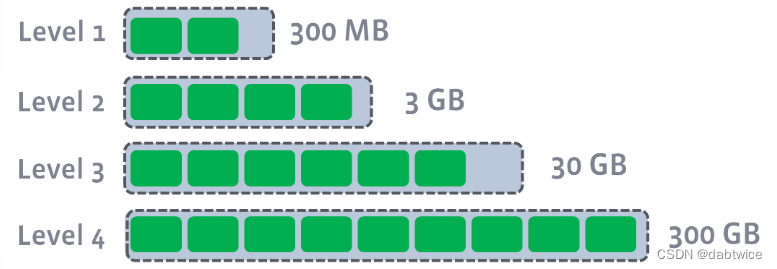
具体流程
上文提到compaction分为minor和major compaction。Minor compaction是当L0的文件数目超过level0_file_num_compaction_trigger的参数就会触发。通常来说因为L0的文件极大概率是相互重叠的,因为大部分情况所有的L0文件都会被合并到L1中。
Minor compaction合并到L1之后,根据前面讲到的规则,有可能会超出L1的数据阈值,从而触发major compaction。Major compaction此时会从L1中选取一个文件,将其与L2中重叠的range进行merge。如果此时L2的数据仍旧超过其阈值,那么就重复上述过程进行compaction,直到最下层。多个层级之间的compaction可以并行执行,其最大数目通过max_background_compaction进行控制。
当多个层级同时触发compaction条件时,RocksDB会首先给每层生成一个分数,规则如下:
- 对于非L0层,
score = current_level_size / level_target_size - 对于L0层,
score = file_num / level0_file_num_compaction_trigger, if file_num >= level0_file_num_compaction_trigger
最终RocksDB会选取分数最高的层首先进行compaction。
选择参与compaction的文件
- 根据每一层的分数选择要compaction的层
Li以及输出的层Lo. - 根据compaction优先级的设置选择优先级最高的文件。如果这个文件或者和他key范围重叠的下一层文件正在参与另一个compaction,那么就选择优先级第二高的文件,以此类推。将选中的文件加入compaction的输入文件集合(inputs set)。
- 重复第一步,直到选中文件的key范围与其周围sst文件的key范围严格不重叠。
- 将input set的key范围与当前正在被compact的文件进行检查确保他们不重叠。如果重叠就终止这次compaction。
- 在
Lo中找到与input set的key范围重叠的所有文件,并将其放入输出文件集合中(output level inputs set) - 将inputs set与output level inputs set进行compaction。
相关参数
有关Leveled-compaction最最重要的参数就是level_compaction_dynamic_level_bytes,它决定了每一层的大小上限是多少。
- 如果其为false,那么对于第n层来说,其大小上限为
target_size(n) = target_size(n - 1) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[n]
特别的,对于L0它的上线会被设置为参数max_bytes_for_level_base的值。 - 如果其为true,那么首先将最后一层的上限设置为其真实包含的数据量(如果最后一层有100G的数据,那么其上限就是100G),然后根据这个值从最后一层往前推每一层的值,实际上也就是
target_size(n - 1) = target_size(n) / max_bytes_for_level_multiplier,这样一来可以保证整个LSM-Tree的金字塔结构稳定性。
L0层间的compaction
有的场景下过多的L0文件会导致读性能下降(因为每次L0层都是全量读取),所以RocksDB会做L0同层文件间的合并,带来一点写放大的同时极大程度缓解了读放大的压力。
TTL机制
如果一个文件长时间没有被更新,那么它就会一直常驻在系统中。一个常见的例子是一个key被设为空值而并不是真正的删除,随后也不会再有针对这个key的更新,那么这个key就会永久驻留,造成空间浪费。RocksDB中可以针对一个CF设置ttl时间,对所有旧于这个时间的数据调度一个compaction。
Universal compaction
Tiered compaction的原理是将多个相似大小的sorted run同时合并起来形成一个更大的sorted run,RocksDB中提供的tiered compaction叫做universal compaction。
通常认为,这种compaction可以在牺牲一些读放大和空间放大的同时带来更低的写放大。一个直观的理解是,因为leveled属于层级compaction,即一层一层向下,假如一个update发生那么它必然会经历n层才会到达最下层;然而在universal/tiered中,一次merge会将很多小的sorted run直接merge成一个很大的sorted run,这一次compaction会使这个update更加靠近最下层,减少了它中间经历更多compaction才会到达最下层的次数,从而减少写放大。
但是正如刚才所说,这种设计方式增加了读放大和空间放大,带来更多CPU和I/O的开销。同时这种compaction方式使得sorted runs的数量很不稳定,从而在性能上带来更多毛刺,
相关参数
关于universal compaction,RocksDB提供了很多可供调整的参数
compaction_options_universal:包含了很多关于universal compaction的自有参数,下面是相关源码,其中重点参数的作用已经用中文做了标注。class CompactionOptionsUniversal { public: // 当前文件与下一个文件的大小比率的阈值,如果小于这个值则将下一个文件加入候选集合中,默认为1 unsigned int size_ratio; // 一次compaction涉及的最少文件数量,默认为2 unsigned int min_merge_width; // 一次compaction涉及的最多文件数量,默认为UINT_MAX unsigned int max_merge_width; // 存储一个字节需要的额外空间比例 // 例如,2%代表如果数据库中有100G的真实数据,实际存储占用空间为100*1.02=102G。 // 默认为200 unsigned int max_size_amplification_percent; // If this option is set to be -1 (the default value), all the output files // will follow compression type specified. // // If this option is not negative, we will try to make sure compressed // size is just above this value. In normal cases, at least this percentage // of data will be compressed. // When we are compacting to a new file, here is the criteria whether // it needs to be compressed: assuming here are the list of files sorted // by generation time: // A1...An B1...Bm C1...Ct // where A1 is the newest and Ct is the oldest, and we are going to compact // B1...Bm, we calculate the total size of all the files as total_size, as // well as the total size of C1...Ct as total_C, the compaction output file // will be compressed iff // total_C / total_size < this percentage // Default: -1 // compression相关 int compression_size_percent; // 用来控制停止选择文件加入compaction run的算法,默认为kCompactionStopStyleTotalSize CompactionStopStyle stop_style; // 这是个优化选项,通过非重叠文件之间的trivial move来优化universal的多层compaction,默认为关闭 bool allow_trivial_move; // 这是一个实验选项,尝试通过限制compaction size在max_compaction_bytes来避免大的compaction job,可能会导致写放大。默认为关闭。 bool incremental; CompactionOptionsUniversal() : size_ratio(1), min_merge_width(2), max_merge_width(UINT_MAX), max_size_amplification_percent(200), compression_size_percent(-1), stop_style(kCompactionStopStyleTotalSize), allow_trivial_move(false), incremental(false) {} };level0_file_num_compaction_triggerlevel0_slowdown_writes_triggerlevel0_stop_writes_triggernum_levelstarget_file_size_basetarget_file_size_multipliercompaction_options_universal.compression_size_percentcompaction_options_universal.allow_trivial_move
具体流程
当选择这种compaction时,磁盘上的所有sst会组织成多个sorted runs,一个sorted run代表一段时间内(time range)的数据,多个sorted runs保证不重叠。Compaction只会发生在相邻time range的sorted run之间,结束之后time range依旧不和其他sorted runs重叠。注意,这多个runs依然可以分布在多个level中,如下图。
RocksDB维护一个最大sorted runs数量的阈值N,当前RocksDB内的sorted runs达到N时就会触发compaction,此时会根据用最小代价减少sorted runs数量的准则选择要compact的sorted runs。具体为从最小的文件开始,在不超过当前compaction大小的情况下尽可能的顺序向后多选sorted runs。
Compaction结束生成的sorted runs会被尽可能的放到更高的level中。
-
包含
L{1+}的层数时,生成的sorted run会被放到参与compaction的最高层数中。例如从上面的图中,我们选择对File_1, File_2以及整个level 4进行compaction,那么生成的sorted run会被放到level 4中,如下图。 -
如果只compact level 0中的一部分,那么输出结果依然放在level 0中,因为level 0本身包含多个sorted runs。
-
如果level 0全量compaction,那么会放在最高的空level中。
Compaction的触发首先要满足n >= options.level0_file_num_compaction_trigger的条件,也就是当前sorted runs的数量超过阈值的时候。此时RocksDB会以此从下面四个条件中从前往后依次尝试,直到有一个compaction job成功被调度:
-
尝试根据数据的新旧调度compaction
对于universal compaction来说,根据数据新老进行compaction是硬性要求,因此会首先检查这个条件。如果有比periodic_compaction_seconds更老的文件,RocksDB会从旧到新选择sorted runs,直到碰到一个被别的compaction选中的sorted run为止。 -
如果空间放大过大,尝试进行major compaction
如果预估的空间放大大于compaction配置中的max_size_amplification_percent,就会触发一个major compaction,也就是所有的sorted runs会被合并成一个sorted run。 -
尝试根据size_ratio进行major/minor compaction
首先计算size_ratio_trigger = (100 + size_ratio) / 100,因为size_ratio一般趋近于0,则size_ratio_trigger趋近于1。按照sorted run的数据新旧,从R1开始(这里应该是从最新的还是最旧的sorted run开始呢?留给大家思考一下,下一篇看源码的时候一并揭晓),如果size(R2) / size(R1) <= size_ratio_trigger,则可以将R2一起加入compaction,以此类推知道有一个sorted run不满足条件,或者参与compaction的数量超出max_merge_width。 -
尝试忽略size_ratio进行minor compaction
如果上面的条件还是不满足,就会尝试这个选项。除了不考虑size_ratio之外,流程与第三个条件相似。
对写放大进行预估
如果想要对系统进行调优,合理的对写放大进行估计必不可少。相比于leveled compaction,universal的预估更加困难,因为它局部最优的compaction文件选择导致整个LSM-Tree的形状并不如leveled那般固定,这里就留给大家自行探索吧 😃
















 2747
2747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











