







前言
最近工作中部分项目中,对存储引擎的需求希望高性能的写、点查,并不需要Range。这里看到大家总会提到BitCask这个存储引擎方案,并不是很了解,特此做一个总体的学习记录。
引擎背景
BitCask 是分布式数据库Riak有存储引擎上的一些需求,但是当时(2010年左右)业界并没有一个能够满足需求的引擎,包括但不限于Berkeley DB, Tokyo Cabinet, Innostore等。所以BitCask便应运而生,主要为了解决以下一些需求:
- 读/写 的低延时
- 随机写场景下的高吞吐
- 支持数据量远大于内存的持久化存储
- 异常恢复机制,能够快速recovery且不丢数据
- 便捷得数据备份机制
- 支持易理解的数据结构
- 大并发/大数据量下的引擎稳定性保障
- 支持平滑迁移到
Riak
除了最后一条定制化需求之外,对于今天我们的存储引擎来说其实都是一些最基本的需求,因为没有强Range性能需求,所以这一些基本要求也是可以理解的,无非就是引擎的稳定性和性能。然而,当时业界并没有这样的一个存储引擎,所以Riak的开发者们也就只能撸起袖子自己搞了。google的bigtable中提出的LSM-tree对读性能并不友好,所以也不满足。
因为没有Range,他们便从hash数据结构入手来提供O(1)的点查,由借鉴了Log-Structure Merged 数据结构中的log-merging思想,来提供强大的写入性能。
引擎原理
1. 磁盘数据结构
BitCask磁盘数据结构非常简单,一个BitCask实例就是一个文件系统目录。需要保证同一时刻只有一个进程会访问这个目录,进程写入的数据更新仅仅会落在一个Active data file中,当这个文件达到了一个给定的阈值,会创建一个新的active data file,而之前的接受写入的文件会被标记为只读。
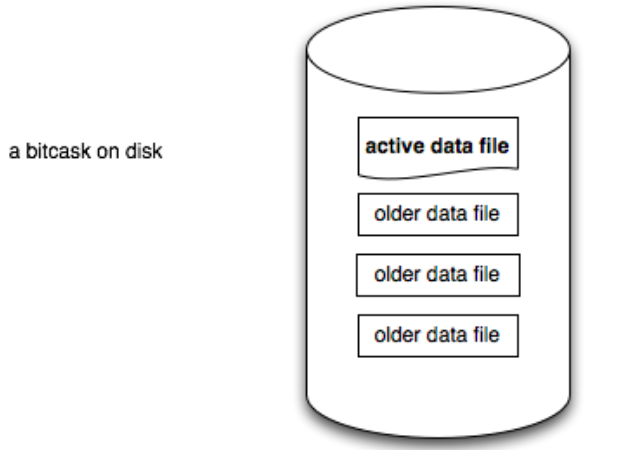
进程写入key/value到active data file的过程时追加写方式,也就是类似于一个文件writer,这个过程会转化成磁盘上的顺序写,所以写入性能肯定会很高。
每一个磁盘上的entry数据格式如下:
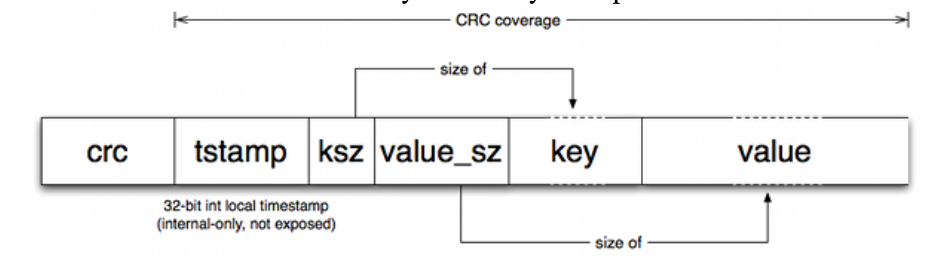
-
crc : 当前entry的数据校验
-
tstamp: 时间戳
-
ksz: key size
-
value_sz : value size
-
key : key的内容
-
value : value的内容
如果想要删除数据,也是写入一个deletion的 tombstone标记,后续的log-merging会清理。
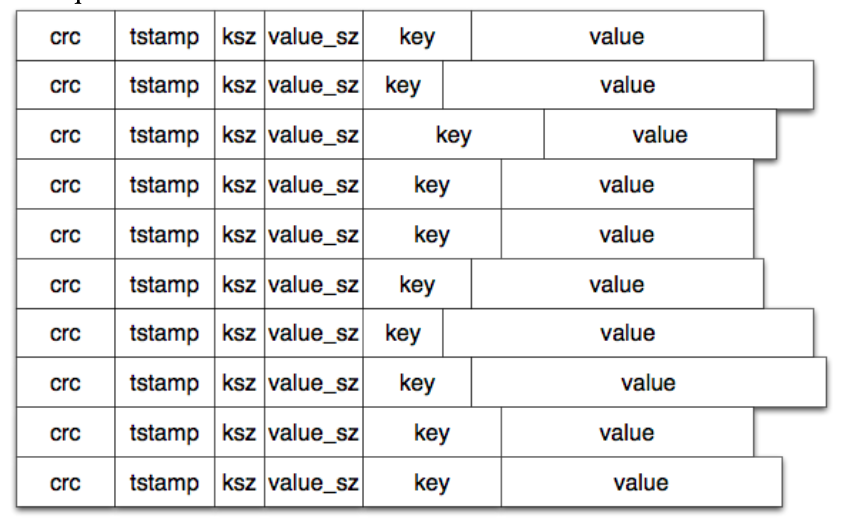
所以,每一个磁盘上的datafile 中的entry最后都追加成这样的形态:
2. 内存数据结构
之前说了,bitcask保证低延时的情况下也是为了提升读写吞吐的,他们为了让读性能远超LSM-tree的这样的数据结构,采用了hash表作为内存索引数据结构。
内存数据结构叫做keydir,形态如下:

这个hash表映射的key都是定长的,这个key在hash表中的’value’ 存储了几个字段:
- file_id : 这个key所属的datafile id
- value_sz : value size
- value_pos: value在 data file中的偏移地址
- tstamp: 时间戳
这个内存数据结构仅仅保存最新的key-value数据信息,同一个key的旧数据还会存储在旧的data file中,在后续的log-merging过中会被清理。
3. 读流程
如下图:
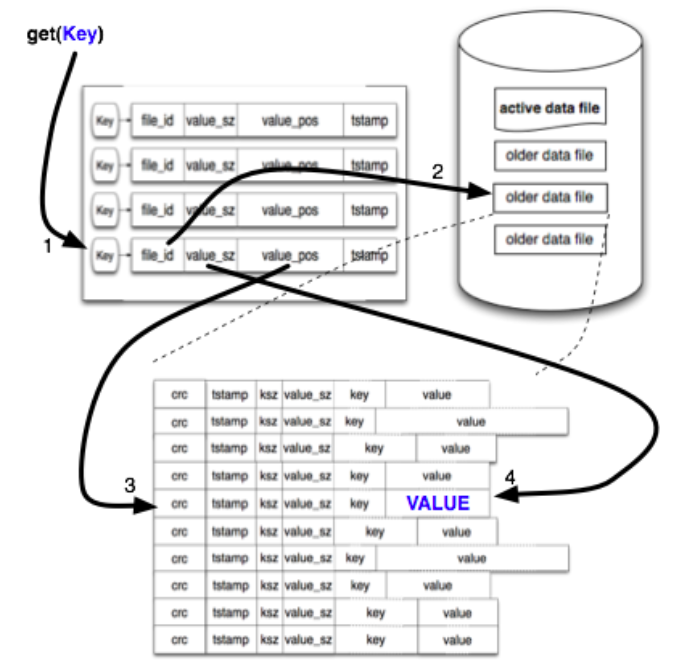
总共分为四步:
- 从内存的hash表中找到之前写入的key,取出这个key数据所在的file_id
- 拿着file-id找到对应的data file
- 根据value_pos 找到datafile上的指定entry
- 从entry的末尾向前读取value_sz 的数据,即为key的value数据
现在,从Get的流程中我们很明显的能够看到bitcask 设计上存在的一些问题:
- 内存索引 中hash表中存放的是所有写入的key,也就是一个机器能够存放的总数据量是有限的
- 因为没有持久化索引,所以机器异常恢复的时候需要遍历磁盘上所有的data file,来构建内存hash索引
- 没有读缓存,即读的过程中value都需要从磁盘加载,这里bitcask的开发者说是考虑到成本太高,也就没有做了。。。那个时候的内存应该还挺贵的,记得10年的能买得起的笔记本电脑内存应该还处于2G以下,那个时候笔记本架构普遍在大几千:)
但是这个并不影响bitcask在当时的性能优势,第一个数据量问题其实能够达到超过内存10倍的持久化存储能力就满足 Riak的需求了这里他们也没有再多说。第二个问题则就是时间上的问题,或者可以多线程recovery来重放,他们也能接受。。。
4. 数据合并
之前说了,为了提升写吞吐,bitcask采用了追加写方式,包括删除操作也是一个追加的过程。因为是追加写,也就有了GC来清理过期数据。
数据合并的过程大体如下,也很简单:
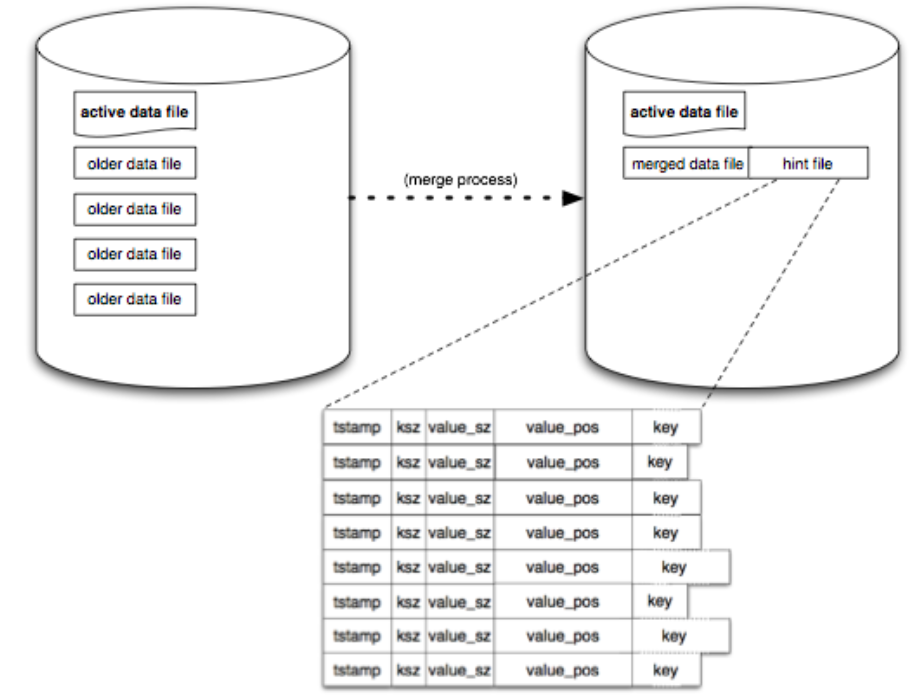
就是根据内存中的lastest hash表中的key数据,遍历所有older data files,只保留最新版本的key数据,将entry写入到一个新的merged data file中。因为这个文件可能会很大,所以会生成一个hint file来索引这个merged data file的内容。当然,hint file中的每一个entry也是对应merged data file中的每一个entry,只是并没有存储value,而是存储了value的偏移地址来加速读取。
这个merged data file和hint file 除了能够清理过期数据,释放空间之外还能够在机器异常恢复之后加速内存中hash 索引的重建(毕竟都是lastest version,也就不需要再重新遍历所有的数据了)
总结
总的来说,bitcask就是一个简单的持久化hash引擎。随着硬件的飞速发展,DRAM的价格越来越便宜,磁盘的性能不断飙升,且价格也在不断降低。到现在,甚至操作系统的I/O栈和网络协议栈都因为硬件的极致性能而成为瓶颈,而bitcask在那个时候构建在文件系统之上的持久化层相比于现在已经远远达不到性能要求了。
现在来看,内存数据结构不会有太大的变化,还是hash表。但底层只能基于新硬件来构建引擎,并且引擎层跳过操作系统I/O栈自己来管理硬件,在此基础上的hash引擎在当代才能够被称为高性能的hash引擎。
当然,还需要有类似rocksdb开发者们的卓越编码能力以及对操作系统细节的深刻理解和应用才能让引擎的性能在当下的硬件上发挥到极致。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









