









1、简介
如果在核心DOM中,网页中节点层级很深时,访问这个节点时将十分麻烦。那么,HTML DOM中应运而生了,提供通过id访问的方法。
2、新特性
- 每一个HTML标记,都对应一个元素对象。
- 每一个HTML标记的属性,与对应的元素对象的属性相呼应。
HTML DOM访问HTML元素的方法(最常用)
1、getElementByIdentity(id)
- 功能:查找网页中指定id的元素对象
- 语法:document.getElementByIdentity(“id”)
2、getElementsByTagName(tagName)
- 功能:查找指定的HTML标记,返回一个数组
- 语法:parentNode.getElementsByTagName(“标记”)
注意:每个HTML标记,都有三大类属性,如:<img>
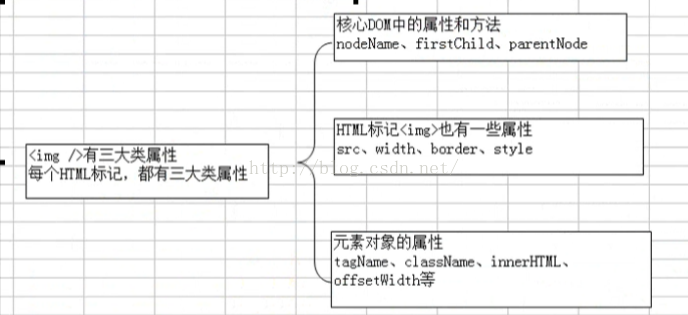
元素对象的属性
- tagName:标签名称,与核心DOM中nodeName一样
- className:CSS “类”的样式,如:object.className = “类名”;不需要”."
- id:同HTML标记id属性一样
- title:同HTML标记title属性一样
- style:同HTML标记style属性一样,代表CSS,但是属于行内CSS
- innerHTML:包含HTML标记中的所有内容,包括HTML标记等。比nodeValue(只能文本节点)强大
- offsetWidth:元素对象的宽度,不带px单位。只有CSS才带单位
- offsetHeight:元素对象的高度,不带px单位
- scrollWidth:元素对象的总宽度,包括滚动条中的内容
- scrollHeight:元素对象的总高度,包括滚动条中的内容
- scrollTop:指内容向上滚动了多少距离(有滚动条才有效)
- scrollLeft:指内容向左滚动了多少距离(有滚动条才有效)
循环滚动原理图
















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









