






在最近的知识学习中,感觉到自己技术栈的匮乏,因此想扩展一下自己的技术面,在自我了解和咨询下,决定开始学习IceBerg,以下皆是自我学习的成果,希望记录下来也能更好的让自己理解,如果有不对的希望大佬可以指正
IceBerg是数据湖的一种,在我看来,他的出现主要是为了解决Hive的一些痛点,比如
-
海量分区耗时过长
-
元数据信息分散到HDFS和MYSQL上,难以保证写入原子性
-
没有文件级别的统计信息,因此fillter过滤的时候,只能过滤partition
-
对底层文件系统的复杂语义依赖
这是我在网上了解到的一些痛点,之后又了解到了IceBerg针对这些痛点所提出的改善
- 构建于存储格式之上的数据组织方式
IceBerg的存储格式还是基于如ORC,Parquet等存储格式,只是基于这些,在他之上提供了更好的元数据管理模式,有V1和V2版本,这些后面介绍
-
保证ACID的能力
-
提供行级别的修改能力
-
保证schema的准确性,并提供一定的扩展性
当然IceBerg的功能特性远不止这些,我再举几个例
-
模式演化:支持对表的增加、修改、删除等操作且没有副作用
-
隐藏分区:分区字段可以不用显示展示,可以通过计算字段值得出
-
快照控制:可实现完全相同的快照下进行可重复查询
…
IceBerg的架构
在架构体系上,有两个版本,分别是V1版本和V2版本
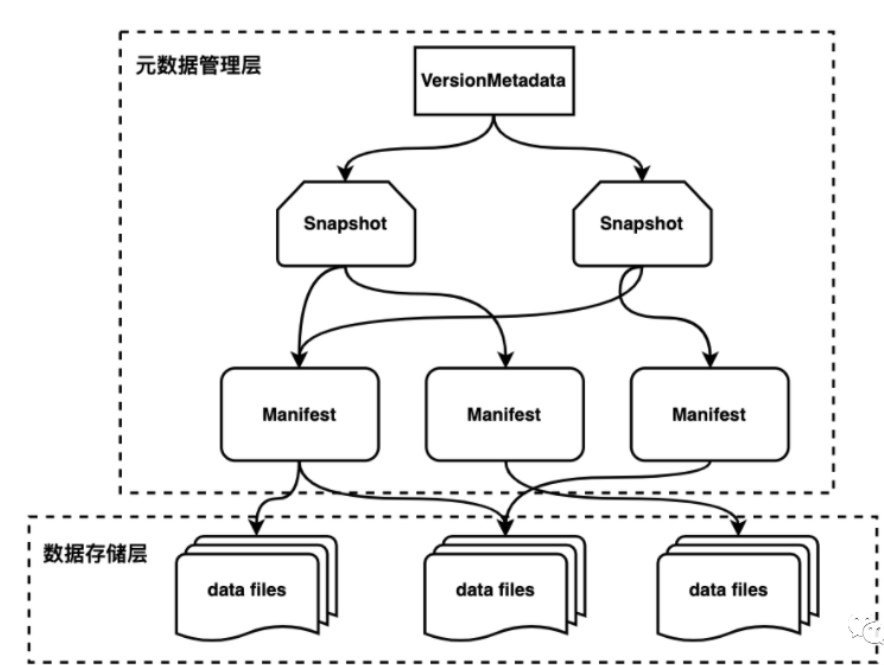
这是在网上找到的三层元数据结构
- VersionMetadata
记录当前最新的元数据版本
- Snapshot
快照信息,指向一个Manfest List清单列表文件,其中包含父快照ID,快照时间戳等
- Manifest List
列表清单文件,每个清单文件占据一行。每行中存储了清单文件的路径、清单文件里面存储数据文件的分区范围、增加了几个数据文件、删除了几个数据文件等信息。这些信息可以用来在查询时提供过滤
- Manifest
这是清单文件,里面记录了实际数据Data的详细描述,包括存储路径、状态、分区信息、列级别的统计信息(比如每一列的最大值/最小值等,可以用来进行分区过滤)、文件的大小等
- data files
实际的数据存储处,一般存储在HDFS的Data路径下
如果要进行数据查询,顺序应该是
-
进入menstore目录下,先找到VersionMetadata文件(JSON格式),从其中找到对应的快照文件
-
找到以snap开头avro结尾的Snapshot文件,从其中找到清单文件的对应名称
-
找到对应的清单文件,以avro结尾,再从清单文件中,找到data数据在data路径下的存储位置和存储名称,然后进行访问
接下来要提到的,就是我之前说的V1和V2版本了
上述的架构可以说就是V1版本,而V2版本也是基于这个架构,不过是在他之上进行了增强设计
合并了Manifest List 和Snapshot
行级修改能力
新增Delete File,存储在Metadata目录下,与Manifest同级,负责记录删除行的信息,通过delete_file_path进行关联
有两种类型,分别是
- Position Delete : 记录被删除行的文件路径和行偏移量(适合随机删除)
- Equality Delete: 存储匹配删除条件的列值,比如user_id =1001(适合批量删除)
实现的原理
- 写入流程 : 执行Delete时生成DELETE FILE,执行UPDATE的时候先执行DELETE再INSERT
- 读取合并 : 查询的时候动态合并DATA FILE 和 DELETE FILE,过滤掉标记行
统计信息增强
-
增加了统计维度:
除了基础的min/max等,还增加了null_value_count等,以及记录了每个文件的row_count,file_size_in_bytes等优化查询效率 -
查询加速场景:
利用partition_summaries来快速跳过无用的分区,通过column_sizes来优化IO读取,优先读取小文件等
元数据示例
Manifest_content:{
"contain_null" : False,
"lower_bound" : "2025-01-01", // 这个是代表上边界和下边界,方便时间过滤/数值列值裁剪
"upper_bound" : "2025-01-30",
"column_sizes" : {"id" : 128MB,"name" : 256MB}
}
//文件级的统计
//可用于小文件合并等策略驱动
{
"record_count" : 100000 //文件总行数
,"value_count" : {"id" : 10000} //非NULL值统计
}
//分区摘要
//可快速定位分区
"partition_summaries": [
{
"contains_null": true,
"partition": {"dt": "2025-01-01"},
"file_count": 5
}
]
并发控制的优化
写入通过检查快照ID是否变化,冲突时自动报错或重试(乐观锁)
通过commit.retry_num-retries来配置,默认是3次重试
以及支持多个任务同时修改不同分区(V1需串行)
V1采取的是全局锁的形式,经典场景就是:任务A写入dt=20250422的分区,任务B写入dt=20250430就会阻塞。V2引入乐观并发控制OOC来并发写入,写入时只锁定目标分区,非目标分区不受影响,但是要开启write.spark.fanout.enable = true,要注意V1版本无法实现真正的并行
Catalog
Catalog在IceBerg中处于核心管理地位,作为用户和Iceberg表交互的唯一入口,所有表的元数据操作都要通过Catalog来发起
在Hive生态中,Catalog是通过Metastore(如Hive Metastore Service)统一管理数据库和表的元数据系统。访问表时可通过HiveServer2/JDBC等接口,其层级关系为表→数据库→Catalog,其中Catalog提供了跨数据库的元数据管理能力,并支持多引擎共享。
因此我们可以简单的认为:Catalog就是一个让我们访问不同数据库的接口
在IceBerg中,Catalog共有三种
- Hive Catalog(默认,也是最常用的)
-- 指定catalog为hive,并命名为iceberg_hive
set iceberg.catalog.iceberg_hive.type = hive
-- 指定连接hive的端口
set iceberg.catalog.iceberg_hive.uri = "thrift://hadoop:9083;"
-- 指定Hive在HDFS上的存储路径
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hive;
CREATE TABLE iceberg_test2
(
id int
)
-- 指定存储格式为Iceberg
STORED BY "org.apache.iceberg.mr.hive.HiveIcebergStorageHandler"
-- 指定Catalog名称
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
- Hadoop Catalog
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hadoop;
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
-- hadoop Catalog需要显示指引存储地址
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberghadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
- 指定路径加载
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
-- 一定要指定我们已有数据表的位置
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberghadoop/default/iceberg_test3'
-- 启用配置
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
该语句本质是通过Hive建立到已有Iceberg表的逻辑映射,而非创建新表结构
Hive的集成
这一块学习的时候没有了解特别深,因为我主要想学Spark + Iceberg的应用方向,就简单介绍一下我的理解
创建表
-- 可以选择是否是外部表
CREATE [EXTERNAL] TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
创建分区表
隐藏分区是我认为IceBerg中很重要的功能特性
CREATE EXTERNAL TABLE iceberg_create3 (
id int,
name string,
ts timestamp
)
PARTITIONED BY (
bucket(16, id), -- 哈希分区
months(ts) -- 时间函数分区
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES (
'iceberg.catalog'='hive',
'format-version'='2' -- 推荐使用V2格式
);
与Spark的集成
Spark同样也是使用Hive Catalog和Hadoop Catalog
// Hive Catalog配置(连接HMS元数据库)
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://hadoop1:9083 // Hive Metastore地址
use hive_prod;
// Hadoop Catalog配置(基于文件系统)
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://hadoop1:8020/warehouse/spark-iceberg // 需HDFS路径
use hadoop_prod
要注意切换Catalog的时候要use一下
创建表
正常创建表,与Hive语法会有些不同
CREATE TABLE hadoop_prod.default.sample1 (
id bigint COMMENT 'unique id',
data string)
USING iceberg
要注意我们的命名规范是Catalog.Database.Table,Spark SQL可以自动解析对应的Catalog和数据库,这是显式指定
同样还可以创建分区表,分区表也有显示分区和隐式分区之分
-- 这是显示分区,显示指定分区字段
CREATE TABLE hadoop_prod.default.sample2 (
id bigint,
data string,
category string)
USING iceberg
PARTITIONED BY (category); -- 显示指定分区字段为category
-- 这是隐式分区,分区字段通过表字段计算得来
CREATE TABLE hadoop_prod.default.sample3 (
id bigint,
data string,
category string,
ts timestamp)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category)
隐式分区是我们常用的方法,常用的转换还有以下几种
支持的转换有:
➢ years(ts):按年划分
➢ months(ts):按月划分
➢ days(ts)或 date(ts):等效于 dateint 分区
➢ hours(ts)或 date_hour(ts):等效于 dateint 和 hour 分区
➢ bucket(N, col):按哈希值划分 mod N 个桶
➢ truncate(L, col):按截断为 L 的值划分
字符串被截断为给定的长度
整型和长型截断为 bin: truncate(10, i)生成分区 0,10,20,30,…
当我们使用CTAS的方式去创建表的时候,要注意指定分区的属性,不然分区属性就失效了(Replace into的建表方式也类似)
CREATE TABLE hadoop_prod.default.sample5
USING iceberg
PARTITIONED BY (bucket(8, id), hours(ts), category)
TBLPROPERTIES ('key'='value') -- 这是占位符,实际使用是会转换如'format-version'='2'的配置
AS SELECT * from hadoop_prod.default.sample3
要注意执行时会触发Spark作业
删除表
-
对于Hadoop Catalog来说,使用Drop Table可以直接删除数据和表
-
对于Hive Catalog来说,使用Drop Table在0.4之后只会删除表,数据并不会删除,所以要使用Drop Table Purge才能删除
DROP TABLE hive_prod.default.sample7 PURGE


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









