







本文仅供学习用!!!!禁止使用其他用途
在有的时候我们想要买房,(虽然这个有时候可能是从来不会出现)但是,我们要有梦想!
这时候我们就需要一个可以观察房源信息的爬虫
我们以58同城网为例,爬取他的前10页二手房资源
以下是代码块,附注解:
导入需要的模块包
import requests
from lxml import etree
import csv
import time
编写保存函数:
def data_write(item):
with open('58tc.csv', 'a+', encoding='gb18030', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(item)
接下来,我们找到网页URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}# 定义爬虫头部
# 爬虫URL
pre_url = 'https://sz.58.com/ershoufang/p'
然后,将网页路径送入解析
因为我们获取一整页的数据,所以可以用以下方式:
该目录下包含整个信息页面,所以我们可以从此处获取志愿


for x in range(1, 11):
html = requests.get(pre_url+str(x), headers=headers)#爬取网页
time.sleep(2)
selector = etree.HTML(html.text)#将网页的源码交给etree.HTML
house_list = selector.xpath('//*[@id="__layout"]/div/section/section[3]/section[1]/section[2]/div')#网页的信息路径
以一个for循环依次获取每个小块下的信息
for house in house_list:#以一个for循环依次获取每个小块下的信息
apartment = house.xpath("a/div[2]/div[1]/div[1]/h3/text()")[0]
print('正在抓取' + apartment)
mianji = house.xpath("a/div[2]/div[1]/section/div[1]/p[2]/text()")[0]
这里我发现一个问题,58网一些text的内容好像不是在固定的path下,所以需要一个纠错机制
第一个是我们要的价格
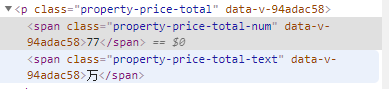
第二个才是我们要的价格
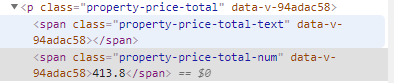
try:
jiage = house.xpath("a/div[2]/div[2]/p[1]/span[1]/text()")[0]
except:
jiage = house.xpath("a/div[2]/div[2]/p[1]/span[2]/text()")[0]
然后继续爬其他信息
jiage2 = house.xpath("a/div[2]/div[2]/p[2]/text()")[0]
weizhi = house.xpath("a/div[2]/div[1]/section/div[2]/p[2]/span[3]/text()")[0]
jiage = (jiage + str('万'))
如果觉得爬单层的页面不够刺激的话,我们可以尝试爬取深层网页
#尝试爬取深层房源页
house_depth = (house.xpath("a/@href")[0])#获取深层网页的url
html1 = requests.get(house_depth, headers=headers)
sel = etree.HTML(html1.text)#将提取到网页的HTML代码交给etree.HTML处理
time.sleep(10)#防止被网页反爬虫
#尝试提取深层网页的内容
house_years = sel.xpath('//*[@id="houseInfo"]/table/tbody/tr[2]/td[2]/span[2]/text()')[0]
house_type = sel.xpath('//*[@id="houseInfo"]/table/tbody/tr[1]/td[3]/span[2]/text()')[0]
到这里,爬虫基本完成啦,只需要把信息写入保存文件就行了
#将信息写入列表
item = [apartment, mianji, jiage, jiage2, weizhi, house_years, house_type]
data_write(item)
print('抓取完成')
以下是主函数:
def main():
info_title = ["公寓", "面积", "价格", "价格2", "位置", "房屋年限", "房屋类型"]
data_write(info_title)
spider()
if __name__ == '__main__':
main()
完成后如下
















 1961
1961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









