








这是一篇来自斯坦福大学的工作,被ACL2022接收。
文章地址:https://arxiv.org/abs/2203.15827
源码地址:https://github.com/michiyasunaga/LinkBERT
目录
0、摘要
作者发现在目前的LM(语言模型)中,预训练阶段都只能学习到一篇文章的知识,而不能获得跨文档的依赖知识。基于这个问题作者提出了LinkBERT模型,该模型对多跳推理和小样本QA领域上效果很好。
1、引言
作者所定义的跨文档知识。

维基百科上的文章“Tidal Basin, Washington D.C.”(左)描述了该盆地举办“National Cherry Blossom Festival”。超链接文章(右)显示,这个节日庆祝的是“Japanese cherry trees”。
这个超链接提供了单一文档无法提供的新知识(例如“Tidal Basin has Japanese cherry trees”),它可以用于各种应用,包括回答“你在潮汐盆地能看到什么树?”这个问题。
超链接、参考文献这种文档是随处可见的且很容易收集,以此来指导我们人类扩展知识,推理知识。作者做就是以这种方式让模型学习更多和目标文档相关的知识以达到更好的效果。
2、结论
提出一种预训练语言模型LinkBERT,在各个数据集上的表现均优于BERT。该模型在多跳推理、多文档理解和小样本问答方面都取得了显著的进步,这表明使用文档链接信息进行预训练可以让模型比现有的lm学习到更多有效的知识。
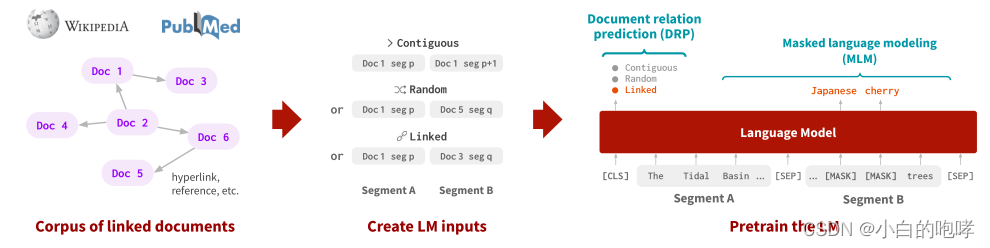
3、LinkBERT
LinkBERT:自监督的预训练方法。
3.1 引入文档图的概念
LinkBERT模型是基于语言和基于图的自监督学习的自然融合。具体来讲,作者将预训练语料库视为一个文档图G = (X, E),其中E(X(i), X(j)),这里的E表示文档之间的链接。
文档图的构建方法:
1.对于网站,当A文章中有文档B的超链接,则构造一条从A指向B的超链接。
2.对于论文,当A文章中引用了B文章,则构造一条从A指向B的超链接。
3.2 预训练任务
3.21 输入实例
构造输入:[CLS] XA [SEP] XB [SEP].其中XA是从语料库中抽取的一个锚文本片段。XB有3个来源:
1.XA的下一句话
2.随机文档中的一句话
3.文档图中XA指向的文档中抽出的一句话
同时,还要对输入的部分token做mask。
3.22 训练目标
两大训练任务:
1.MLM:和BERT一样,用以在最终层预测所有的token。
2.DRP(Document Relation Prediction):替换掉了BERT中的NSP(Next Sentence Prediction)任务,用以预测文档A和文档B的三种关系(连续,随机,链接)。
训练的损失函数: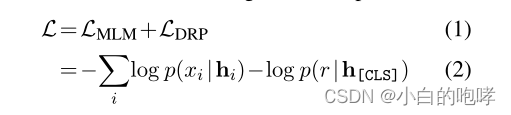
4、获取文档链接的策略
作者任务关联文档的选取需满足下列三个要求:
1.Relevance:选取的文档必须和当前文档有关系
2.Salience:选取的文档可以提供新的、有用的知识。作者认为仅通过计算词汇相似度来选择文档是不可行的,那样只能筛选出重复的知识。
3.Diversity:一些知识可能被反复多次作为文档图中的入度。但是由于我们目的是要学习更多的新的知识,所以要降低这些频次高的文档被选中的概率。作者使文档选中的概率与文档的入度成反比。
5、实验
5.1 预训练
选择和BERT相同的语料库:Wikipedia和BookCorpus.除了该模型使用了维基百科的超链接外,预训练的数据和BERT都是相同的。
BaseLine:BERT.
5.2 实验结果

在各个要求多文档的推理数据集上(HotpotQA, TriviaQA, SearchQA),LinkBERT都比BERT有较大提升。
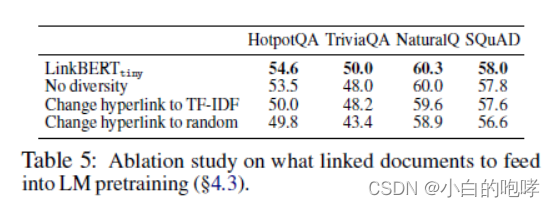
使用TF-IDF来选择相关文档,效果并不好。同时证明了作者对于选择文档要求Salience的必要性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











